



前回は、Amazon SageMakerのチュートリアルをベースにして、ノートブックインスタンスの作成までの手順を説明しました。今回は、下表の「ステップ3:データの準備」にあたる、学習/推論に利用するデータの準備を行っていきます。
| 工程 | ステップ | 枝番 | 実施内容 | 連載回 |
|---|---|---|---|---|
| 開発 | 1 | Amazon SageMakerコンソールにログインする | 第5回 | |
| 2 | Amazon SageMakernotebook instanceを作成する | 第5回 | ||
| 3 | データの準備 | 第6回 | ||
| 3a, 3b | ノートブックを起動する | |||
| 3c | ノートブックの利用準備をする | |||
| 3d | S3 バケットを作成する | |||
| 3e | 学習/推論に利用するデータをダウンロードする | |||
| 3f | データを分割する | |||
| 学習 | 4 | データからのモデルのトレーニング | 第7回 | |
| 4a | 学習データを S3 バケットにアップロードする | |||
| 4b | 学習の設定をする | |||
| 4c | 学習を行う | |||
| 推論 | 5 | モデルのデプロイ | 第8回 | |
| 5a | 推論エンドポイントを作成して、モデルをデプロイする | |||
| 5b | 推論を行う | |||
| 6 | モデルの性能評価 | 第8回 | ||
| 後片付け | 7 | リソースを終了する | 第8回 |
ステップ3:データの準備
前回解説したステップ2までの工程で、ノートブックインスタンスの作成を完了しました。ここからはノートブックを起動して、学習/推論に必要なデータの準備を行っていきます。
 |
ノートブックインスタンスで利用できる2種類のプログラミングツール
Amazon SageMakerのノートブックインスタンスでは、「Jupyter Notebook」もしくは「JupyterLab」が利用できます。ノートブックインスタンスは、これらがプリインストールされた状態で作成されているので、利用者側でインストールする必要はありません。
Jupyter Notebook、JupyterLabは、「Project Jupyter」と呼ばれる非営利のOSSプロジェクトにより管理されているプログラミングのツールです。特に、Pythonの開発環境が充実していますが、RやSparkなどさまざまな言語で利用することができます。
 |
参考までに、以下にAWS JapanがGitHubで公開しているサンプルのノートブックの画像(JupyterLabを使って開いたもの)を掲載しておきます。
 |
ノートブックでは、「セル」と呼ばれる灰色のブロックにコードを記述して、少しずつ確認しながら実行することができます。マークダウンでテキストや画像、数式などを記載することも可能です。
コーディングの際、ソースコードにコメントで設計根拠などを残すことがありますが、Jupyter NotebookやJupyterLabでは、従来の方法よりも詳細に情報を残すことができます。なお、JupyterLabはJupyter Notebookの後継にあたるノートブックです。
チュートリアルを実施する上ではどちらを選んでも問題ありません。チュートリアルではJupyter Notebookが利用されているので、本稿ではJupyterLabを利用して進めたいと思います。
ステップ3a, 3b:ノートブックを起動する
「アクション」の「JupyterLabを開く」をクリックし、「JupyterLab」を起動します。なお、「Jupyterを開く」のほうをクリックすると、Jupyter Notebookが起動します。
 |
JupyterLabを起動すると、「Launcher」タブが表示されます。このチュートリアルでは、Python 3の実行環境があれば良いので、「Notebook」の配下にある「conda_python3」をダブルクリックします。
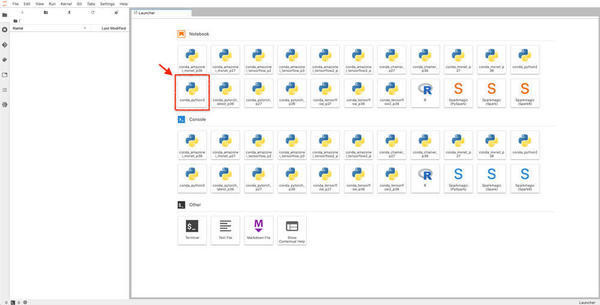 |
すると、「Untitled.ipynb」というタブに切り替わり、左側のメニューに同名のファイルが表示されます。これがノートブックのファイルとなります。今回はこの状態のまま進めますが、左側のメニューに表示されている「Untitled.ipynb」を右クリックして、「Rename」を選択することによりファイル名を変更することが可能です。
また、ノートブックの右端に「conda_python3」と表示されており、自分がどの環境を使っているのかはここを確認するとわかります。
 |
ステップ 3c:ノートブックの利用準備をする
JupyterLabでノートブックを起動したら、ノートブックの利用準備として、このチュートリアルで利用するライブラリ(モジュール)の読み込み(インポート)や権限の設定などを行います。
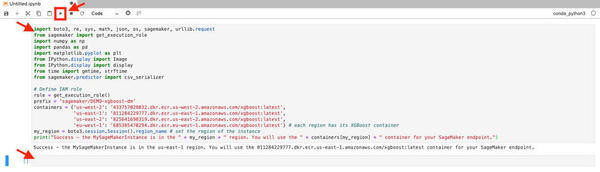
以下のコードをセルにコピー&ペーストして実行してください。
# import libraries
import boto3, re, sys, math, json, os, sagemaker, urllib.request
from sageMakerimport get_execution_role
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from IPython.display import Image
from IPython.display import display
from time import gmtime, strftime
from sagemaker.predictor import csv_serializer
# Define IAM role
role = get_execution_role()
prefix = 'sagemaker/DEMO-xgboost-dm'
containers = {'us-west-2': '433757028032.dkr.ecr.us-west-2.amazonaws.com/xgboost:latest',
'us-east-1': '811284229777.dkr.ecr.us-east-1.amazonaws.com/xgboost:latest',
'us-east-2': '825641698319.dkr.ecr.us-east-2.amazonaws.com/xgboost:latest',
'eu-west-1': '685385470294.dkr.ecr.eu-west-1.amazonaws.com/xgboost:latest'} # each region has its XGBoost container
my_region = boto3.session.Session().region_name # set the region of the instance
print("Success - the MySageMakerInstance is in the " + my_region + " region. You will use the " + containers[my_region] + " container for your SageMakerendpoint.")
 |
上部のメニューバーに表示されている三角のアイコンを押下するか、「Shift」+「Enter」で実行できます。この後もいくつかコードを示しますが、同様の方法で実行してください。セルの下側に以下のメッセージが出力されれば成功です。
Success - the MySageMakerInstance is in the us-east-1 region. You will use the 811284229777.dkr.ecr.us-east-1.amazonaws.com/xgboost:latest container for your SageMakerendpoint.
では、上記のコードについて説明していきましょう。コードはそれぞれ「# import libraries」と「# Define IAM role」から始まる2つの処理に分けられます。
# import libraries
import boto3, re, sys, math, json, os, sagemaker, urllib.request
from sageMakerimport get_execution_role
import numpy as np
import pandas as pd
# (以下、省略)
「# import libraries」から始まる処理では、チュートリアルの実行に必要なライブラリ(モジュール)の読み込み(インポート)を行っています。具体的には、Pythonでよく利用される「NumPy」や「Pandas」に加えて、AWSでの開発に利用する「AWS SDK for Python (Boto3)」や Amazon SageMakerの開発に利用する「Amazon SageMakerSDK for Python」などを読み込んでいます。Matplotlib など利用しないものも一部含まれますが、ここではいったん無視します。
# Define IAM role
role = get_execution_role()
prefix = 'sagemaker/DEMO-xgboost-dm'
containers = {'us-west-2': '433757028032.dkr.ecr.us-west-2.amazonaws.com/xgboost:latest',
'us-east-1': '811284229777.dkr.ecr.us-east-1.amazonaws.com/xgboost:latest',
'us-east-2': '825641698319.dkr.ecr.us-east-2.amazonaws.com/xgboost:latest',
'eu-west-1': '685385470294.dkr.ecr.eu-west-1.amazonaws.com/xgboost:latest'} # each region has its XGBoost container
my_region = boto3.session.Session().region_name # set the region of the instance
一方、「# Define IAM role」から始まる処理では、主に以下のような処理を実行しています。
- ノートブックインスタンスにアタッチしたIAMロールの実行権限の取得
- S3バケットのプレフィックスの設定
- 組み込みアルゴリズムXGBoostのコンテナイメージのECRレジストリのパスの設定
- リージョンの設定
これらのうち、1と3の処理について見ていきます。
1. ノートブックインスタンスにアタッチした IAM ロールの実行権限の取得
role = get_execution_role()
ノートブックインスタンスにアタッチされている実行ロールのARNを取得して、その実行ロールを使用して操作を行います。ここで言う「実行ロール」とは、ノートブックインスタンス作成時に新規作成したIAM ロールであり、「AmazonSageMakerFullAccess ポリシー」が操作権限として与えられています。
詳細を知りたい方は、公式サイトの「Amazon SageMakerの実行ロールを取得する」「sagemaker.session.get_execution_role(sagemaker_session=None)」を参照してください。
3. 組み込みアルゴリズムXGBoostのコンテナイメージのECRレジストリのパスの設定
containers = {'us-west-2': '433757028032.dkr.ecr.us-west-2.amazonaws.com/xgboost:latest',
'us-east-1': '811284229777.dkr.ecr.us-east-1.amazonaws.com/xgboost:latest',
'us-east-2': '825641698319.dkr.ecr.us-east-2.amazonaws.com/xgboost:latest',
'eu-west-1': '685385470294.dkr.ecr.eu-west-1.amazonaws.com/xgboost:latest'} # each region has its XGBoost container
第4回で説明したように、Amazon SageMakerではAmazon ECRから学習用コンテナイメージをダウンロードし、学習用インスタンス上でコンテナを起動して学習を行います。
上記のコードはAWSが管理するAmazon ECRのレジストリから「XGBoost リリース 0.72のコンテナイメージで最新 (latest) のもの」を取得するための設定です。
「AWSが管理する学習用コンテナイメージを利用して学習を行う」とは、「組み込みアルゴリズムによる学習を行う」ということです。組み込みアルゴリズムを利用することにより、機械学習アルゴリズムの実装が不要となって利用者が開発する規模を小さく抑えることができます。
AWSが管理する Amazon ECRのレジストリはリージョンごとに用意されています。今回は「バージニア北部(us-east-1)」で実施しているので、「811284229777.dkr.ecr.us-east-1.amazonaws.com/xgboost:latest」からコンテナイメージを取得します。「東京 (ap-northeast-1)」で利用する場合は、「’ap-northeast-1’: ‘501404015308.dkr.ecr.ap-northeast-1.amazonaws.com’」を追加するなどコードの改変が必要です。
また、今回はXGBoost リリース 0.72を利用していますが、より新しい「XGBoost リリース 0.90」もリリースされています。リリース 0.72と0.90とでは、レジストリのパスが異なりますので、注意が必要です。詳細を知りたい方は、「組み込みアルゴリズムの共通パラメータ」を参照してください。XGBoost以外のアルゴリズムについても記載されているので、応用する際には参照して適切に変更していただければと思います。
ステップ 3d:S3バケットを作成する
ここでは、学習/推論に利用するデータを格納するためのS3バケットを作成します。作業は引き続き、JupyterLabで行います。
以下のコードをセルにコピー&ペーストして実行してください。なお、コードをセルにコピー&ペーストした後に、必ず「bucket_name」の「your-s3-bucket-name」の箇所を変更してから実行してください。S3バケット名は世界で唯一の値にする必要があるので、名前が重複するとエラーとなります。「システム名」などの固有になりやすい情報を含めると重複しづらいと思います。検証目的であれば「日付」を入れても良いでしょう。
bucket_name = 'your-s3-bucket-name' # では、上記のコードについて説明していきます。
チュートリアルでは、AWS SDK for Python (Boto3) を利用してノートブックから S3 バケットを作成する方法が示されています。AWSマネジメントコンソールからも同等の作業ができますが、ここではチュートリアルに従ってノートブックから作成してみましょう。
s3 = boto3.resource('s3')
AWS SDK for Python (Boto3)では、AWSのリソースを操作する方法に「Resources」と「Clients」の2種類があります。S3バケットの作成はどちらでも可能ですが、チュートリアルでは抽象度の高い「Resources」のほうのAPIを使ってS3バケットを作成しています。
- Resources:高レベルのオブジェクト指向インタフェース。Clientsと比べて抽象度が高い。
- Clients:低レベルのサービス接続。メソッドはサービスAPIとほぼ1:1で対応し、全てのサービスの操作がサポートされる。
if my_region == 'us-east-1':
s3.create_bucket(Bucket=bucket_name)
else:
s3.create_bucket(Bucket=bucket_name, CreateBucketConfiguration={ 'LocationConstraint': my_region })
create_bucketメソッドには、「CreateBucketConfiguration」という引数があり、LocationConstraintでS3バケットを作成するリージョンを指定することができます。これが省略された場合は、作成するリージョンが「バージニア北部 (us-east-1)」となるため、my_regionの値によって条件分岐をしています。
ステップ 3e:学習/推論に利用するデータをダウンロードする
前のセクションで学習/推論用のデータを格納するためのS3バケットの作成が完了しました。このチュートリアルでは、インターネット上で公開されているデータを学習/推論に利用します。
データをノートブックインスタンスのローカルディスク上にダウンロードして、簡単な前処理を行います。以下のコードをセルにコピー&ペーストして実行してください。
try:
urllib.request.urlretrieve ("https://d1.awsstatic.com/tmt/build-train-deploy-machine-learning-model-sagemaker/bank_clean.27f01fbbdf43271788427f3682996ae29ceca05d.csv", "bank_clean.csv")
print('Success: downloaded bank_clean.csv.')
except Exception as e:
print('Data load error: ',e)
try:
model_data = pd.read_csv('./bank_clean.csv',index_col=0)
print('Success: Data loaded into dataframe.')
except Exception as e:
print('Data load error: ',e)
上記で呼び出しているurllib.request.urlretrieveメソッドは、引数に指定したURLからファイルをローカルにダウンロードします。
urllib.request.urlretrieve ("https://d1.awsstatic.com/tmt/build-train-deploy-machine-learning-model-sagemaker/bank_clean.27f01fbbdf43271788427f3682996ae29ceca05d.csv", "bank_clean.csv")
引数に渡したURLは、そのホスト名からAWSの静的ファイルを配布するためのCDNサービスであるAmazon CloudFront、もしくはAmazon S3だと推測されます。ここからノートブックインスタンスのローカルディスク上に、学習や推論に利用するデータである「Bank Marketing Data Set」をダウンロードしているわけです。
なお、AWSが配布しているデータは、チュートリアルを進めやすいように前処理が施されています。UCIのMachine Learning Repositoryで公開されているデータをダウンロードして利用する場合は、機械学習で利用できるようにデータの前処理が必要となりますのでご注意ください。
また、Pandasのread_csv関数を使ってダウンロードしたBank Marketing Data SetをDataFrameに読み込んでいるのが以下の部分です。
model_data = pd.read_csv('./bank_clean.csv',index_col=0)
ステップ 3f:データを分割する
Bank Marketing Data Setは、41,188行×61列のデータです。これを学習と推論の双方で利用するために学習:推論 = 7:3の割合で分割します。
以下のコードをセルにコピー&ペーストして実行してください。
train_data, test_data = np.split(model_data.sample(frac=1, random_state=1729), [int(0.7 * len(model_data))])
print(train_data.shape, test_data.shape)
コードの解説
train_data, test_data = np.split(model_data.sample(frac=1, random_state=1729), [int(0.7 * len(model_data))])
NumPyのsplitメソッドを使って、DataFrameとして読み込んだデータ(model_data)を学習データ(train_data)とテストデータ(test_data)が7:3の割合になるように分割しています。
さらに、Pandasのsampleメソッドを使ってランダムにデータを選択することで、データの順序性を排除しています。
* * *
今回は、Amazon SageMakerのチュートリアルをベースにして、学習/推論に利用するデータの準備を行う手順を説明しました。次回は、今回準備したデータを使っていよいよ学習を行います。
著者紹介
 |
菊地 貴彰 (KIKUCHI Takaaki) - 株式会社NTTデータ
システム技術本部 デジタル技術部
Agile プロフェッショナル担当
大学・大学院では、機械学習を専攻。ベイズ的枠組みを用いて、複数の遺伝子のデータから遺伝子どうしの相互作用ネットワークの推定に関する研究を行った。
株式会社NTTデータに入社後は、法人や金融のシステム開発のシステム基盤担当としてキャリアを積み、現在はデジタル技術やAgile開発を専門に扱う組織でシステム開発全般を担当する。
2019, 2020 APN AWS Top Engineers, Japan APN Ambassador 2020に選出に選出。
本連載の内容に対するご意見・ご質問はtwitter: @kikuchitk7まで。









