今回は機械学習でよく使われる学習アルゴリズムの一つ「ランダムフォレスト」を実装して、手描き文字の分類に挑戦してみましょう。このアルゴリズムは機械学習の分野でよく利用されるものですが、実際にRustを使ってゼロから実装することで、理解を深めましょう。
-
ランダムフォレストで手描き数字の判定に挑戦してみよう

ランダムフォレストとは?
今回は、筆者が好きな機械学習アルゴリズムの一つ「ランダムフォレスト(Random Forest)」を取り上げて、Rustでゼロから実装してみましょう。
ランダムフォレストは、アンサンブル学習の一つです。アンサンブル学習とは、複数のモデルを組み合わせて、より高い予測精度を実現するための機械学習手法です。
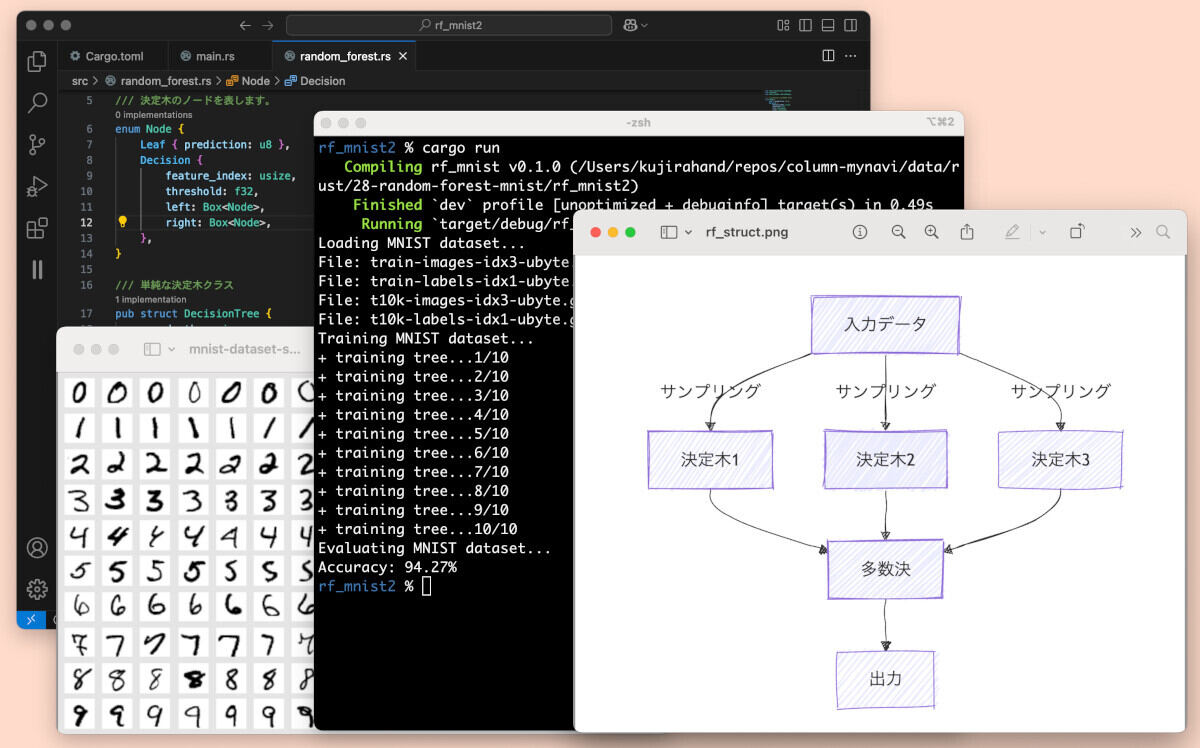
ランダムフォレストでは、複数の「決定木(Decision tree)」を利用します。次の図のように、複数の決定木がそれぞれ予測を行った後で、多数決によって最終的な答えを決定します。
-
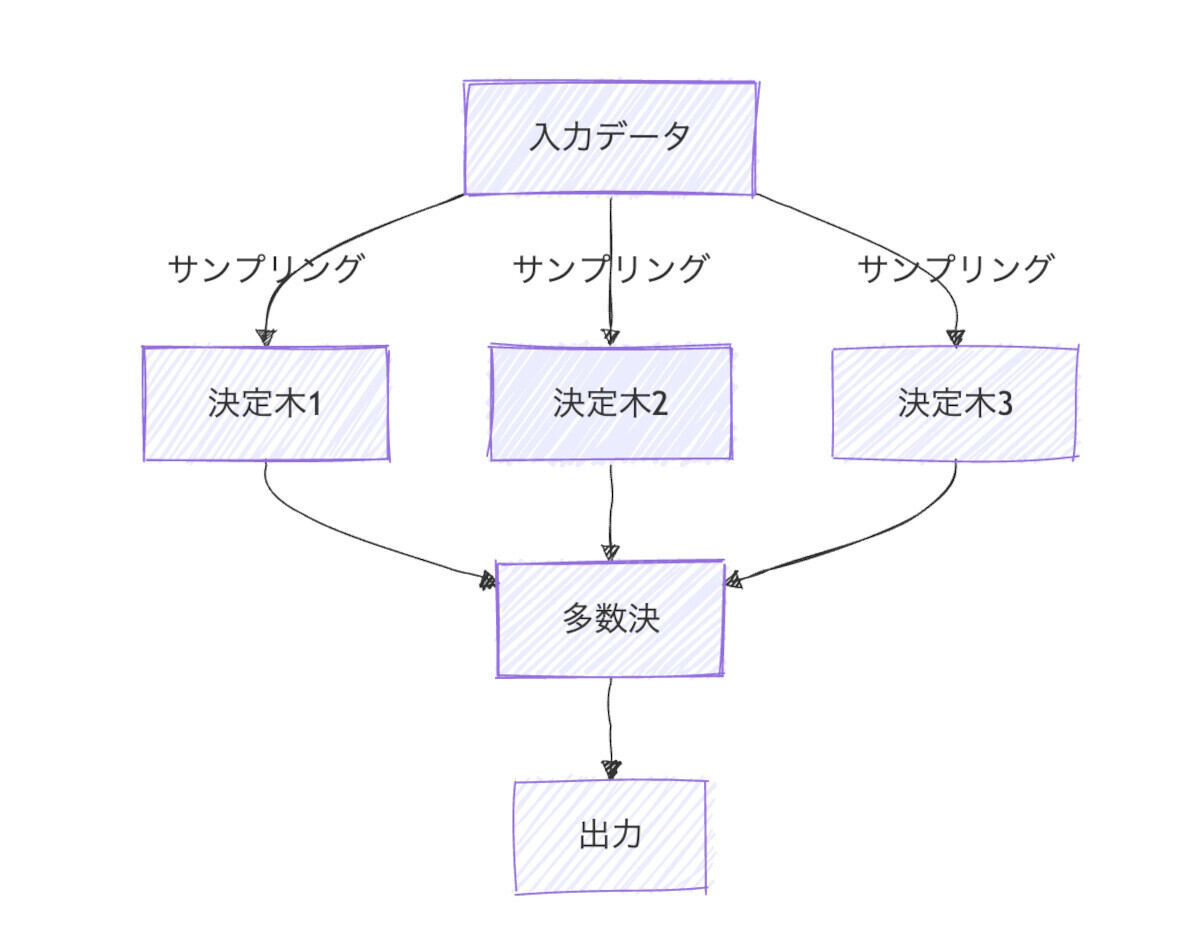
ランダムフォレストの仕組み

手描き数字の画像データセットMNISTについて
そして、単にランダムフォレストをライブラリとして実装しても面白くないので、これを実際に活用してみましょう。今回は、大量の手描き数字の画像を学習させて、未知の画像からどんな数字が描かれているかを判定して、どのくらいの精度がでるのかを評価してみます。
大量の手描き数字のデータがインターネット上で公開されています。これが「MNIST」と呼ばれる有名なデータセットです。これは、次の画像のように、大量の手描き数字が収録されたデータセットです。
-

MNISTのデータセット

MNISTの画像データセットには、6万枚の学習用データと1万枚のテスト用データが含まれています。それぞれ、28x28のグレイスケール画像と、どの数字が描かれているのかを表すラベルから成り立っています。
ちなみに、MNISTのデータセット自体は、こちら(https://github.com/fgnt/mnist)で配布されているのですが、独自のデータ形式で配布されているため、データの読み込みが大変です。そこで、筆者が本連載のために作成した「mnist-reader」クレートを利用しましょう。このクレートを利用すると、MNISTのデータを自動でダウンロードして、手軽に読み込みを行うことができます。
プロジェクトを作成しよう
それでは、プロジェクトを作成して、必要なライブラリをプロジェクトに追加しましょう。ターミナル(WindowsではPowerShell、macOSではターミナル.app)を起動して、下記のコマンドを実行します。
# プロジェクトの作成
mkdir rf_mnist
cd rf_mnist
cargo init
# 今回利用するライブラリを追加
cargo add mnist_reader # MNISTのデータセットを読み込むため
cargo add lazyrand # 乱数を使うため
MNISTデータセットの読み込みテストをしてみよう
メインプログラム「src/main.rs」を以下のように書き換えて、MNISTデータセットのダウンロードと読み込みが成功するか確認してみましょう。
use mnist_reader::{MnistReader, print_image};
fn main() {
// MNISTのデータセットをダウンロード
let mut mnist = MnistReader::new("mnist-data");
mnist.load().unwrap();
// MNISTの最初のデータを表示
let images: Vec<Vec<f32>> = mnist.train_data;
print_image(&images[0]);
let labels: Vec<u8> = mnist.train_labels;
println!("labels[0]={}", labels[0]);
}
そして、ターミナルで以下のコマンドを実行してみましょう。
cargo run
すると、MNISTのデータセットをダウンロードして、最初のデータを表示します。
-
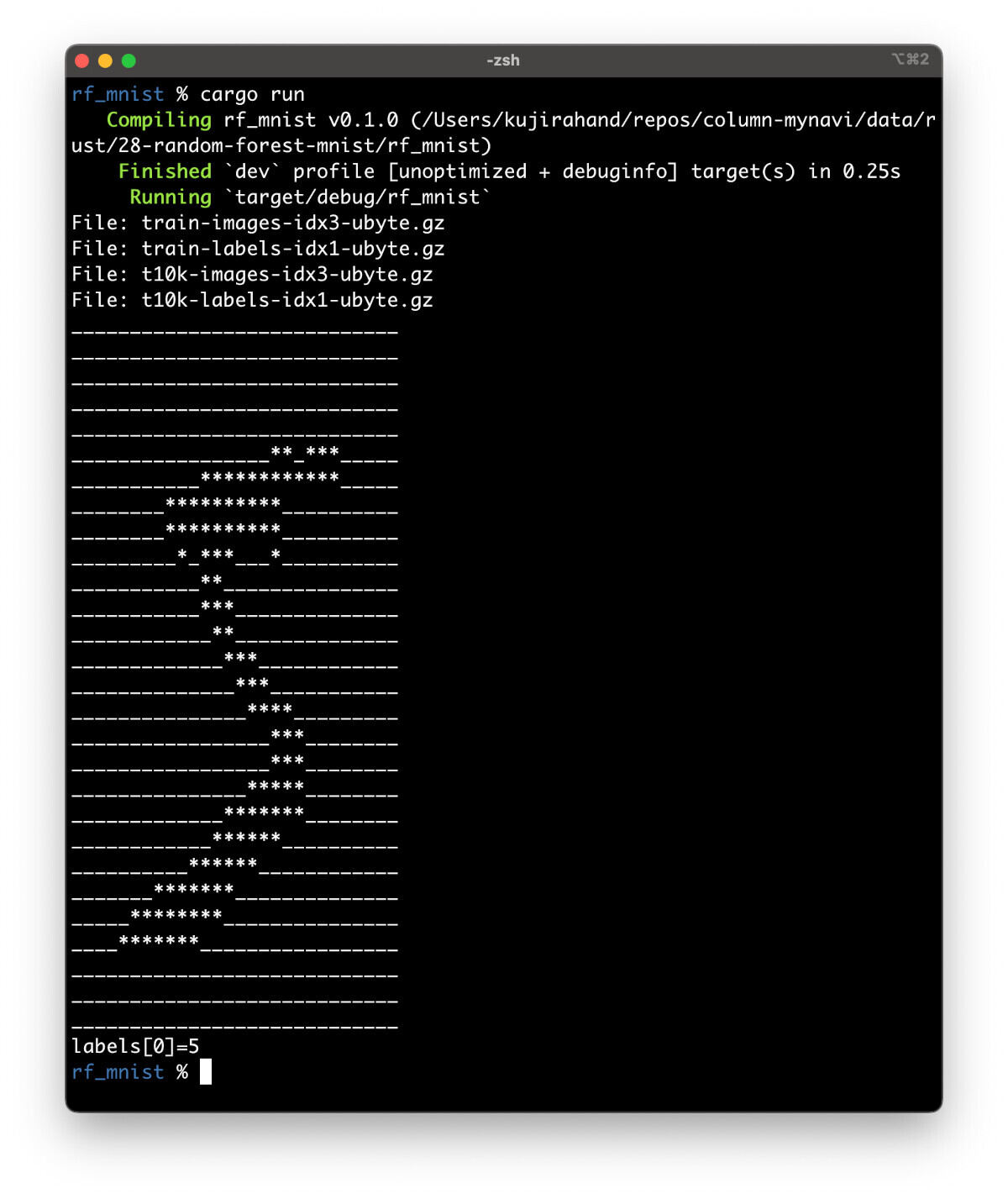
MNISTのテストプログラムを実行したところ

なお、今回のプロジェクト「rf_mnist」フォルダは、下記のような構造になります。mnist-dataフォルダは、プログラムを初回実行した時に作成されて、MNISTのデータセットが自動的にダウンロードされます。
.
├── Cargo.lock
├── Cargo.toml
├── <mnist-data>
│ ├── t10k-images.idx3-ubyte.gz
│ ├── t10k-labels.idx1-ubyte.gz
│ ├── train-images.idx3-ubyte.gz
│ └── train-labels.idx1-ubyte.gz
└── <src>
├── random_forest.rs
└── main.rs
ランダムフォレストを実装してみよう
それでは、ランダムフォレストを実装してみましょう。「src/random_forest.rs」というファイルを作成しましょう。ランダムフォレストのアルゴリズムのプログラムが少し長いので、以下に抜粋したものを紹介します。
実際には、こちらのGistにアップしたプログラム( https://gist.github.com/kujirahand/b3c6a5b40310fb88964116fbe2665d9d )から、コードをコピーして貼り付けてください。
以下は、ランダムフォレストで決定木を実装するための構造体DecisionTreeの定義の抜粋です。
/// 決定木のノード
enum Node {
Leaf { prediction: u8 }, // サンプルの予測ラベル
Decision {
feature_index: usize, // データを二分するための条件
threshold: f32, // 分岐に使うしきい値
left: Box<Node>, // 条件を満たす場合の子ノード
right: Box<Node>, // 条件に合致しない場合の子ノード
},
}
/// 単純な決定木クラス
pub struct DecisionTree {
max_depth: usize,
min_samples_split: usize,
max_features: usize,
root: Option<Box<Node>>,
}
注目したいのは、列挙型NodeのDecisionにおける、leftとrightです。Rust の列挙型や構造体は、全フィールド分のサイズをコンパイル時に確定しなければなりません。そのため、Box
続いて、ランダムフォレスト本体の実装を確認してみましょう。
/// ランダムフォレスト本体
pub struct RandomForest {
trees: Vec<DecisionTree>,
}
impl RandomForest {
/// readerのtrain_dataを用いて学習する
pub fn train(reader: &MnistReader, n_trees: usize, max_depth: usize, min_samples_split: usize) -> Self {
// 決定木を指定数だけ作成して学習を行う
〜省略〜
let mut trees = Vec::with_capacity(n_trees);
for i in 0..n_trees {
println!("+ training tree...{}/{}", i+1, n_trees);
〜省略〜
tree.train(&data, &labels);
trees.push(tree);
}
RandomForest { trees }
}
/// 1サンプルを予測
pub fn predict(&self, sample: &[f32]) -> u8 {
let mut votes = HashMap::new();
for tree in &self.trees { // 決定木の予測結果を集めて投票
let pred = tree.predict(sample);
*votes.entry(pred).or_insert(0) += 1;
}
votes.into_iter().max_by_key(|&(_, c)| c).map(|(cls, _)| cls).unwrap_or(0)
}
/// テストデータで精度を計算
pub fn evaluate(&self, reader: &MnistReader) -> f32 { … }
}
ランダムフォレストの実装においては、入力データをサンプリングして複数の決定木を作成して、その後で投票(多数決)で最終的なクラスラベルを決定します。そして、決定木は、データを「ある特徴量がしきい値より小さいか大きいか」といった2択の判定を繰り返すことでラベルを予測します。
それで、上記のプログラムでも、データの学習を行うtrainメソッドでは、複数の決定木を作成しています。予測を行うpredictメソッドでは、生成した決定木に予測をしてもらって、最後にどの予測が正しいかを投票で決めるという流れになっています。
メインプログラムを完成させよう
それでは、上記のプログラム(src/random_forest.rs)を利用して、メインプログラム(src/main.rs)を完成させましょう。今回は、ランダムフォレストの実装がメインなので、実際に手描き数字を分類するUI画面などは持たせず、テスト用のデータを用いて、ランダムフォレストの性能を評価するだけに留めました。
次のようなプログラムになります。
mod random_forest;
use mnist_reader::MnistReader;
use random_forest::RandomForest;
fn main() {
// MNISTのデータセットをダウンロード
let mut mnist = MnistReader::new("mnist-data");
println!("Loading MNIST dataset...");
mnist.load().unwrap();
// ランダムフォレストでデータの学習を行う
println!("Training MNIST dataset...");
let rf = RandomForest::train(&mnist, 10, 30, 10);
println!("Evaluating MNIST dataset...");
// テストデータで評価を行って、判定精度を表示
let result = rf.evaluate(&mnist);
println!("Accuracy: {:.2}%", result * 100.0);
}
プログラムを確認してみましょう。モデルの学習を行うtrainメソッドでは、決定木を指定数(n_trees)だけ作成して学習を実行します。そして、予測を行うpredictメソッドでは、trainで作成した決定木を利用して、予測を行って、投票結果を元に最終的な判定結果を返します。
プログラムを実行するには、ターミナルで下記のコマンドを実行します。
cargo run
筆者のMacbook Pro M4を利用して測定したところ、実行に48秒かかり、判定精度は94.47%と表示されました。ただし、乱数を使って学習を行っているため、実行するたびに精度は変わります。
-
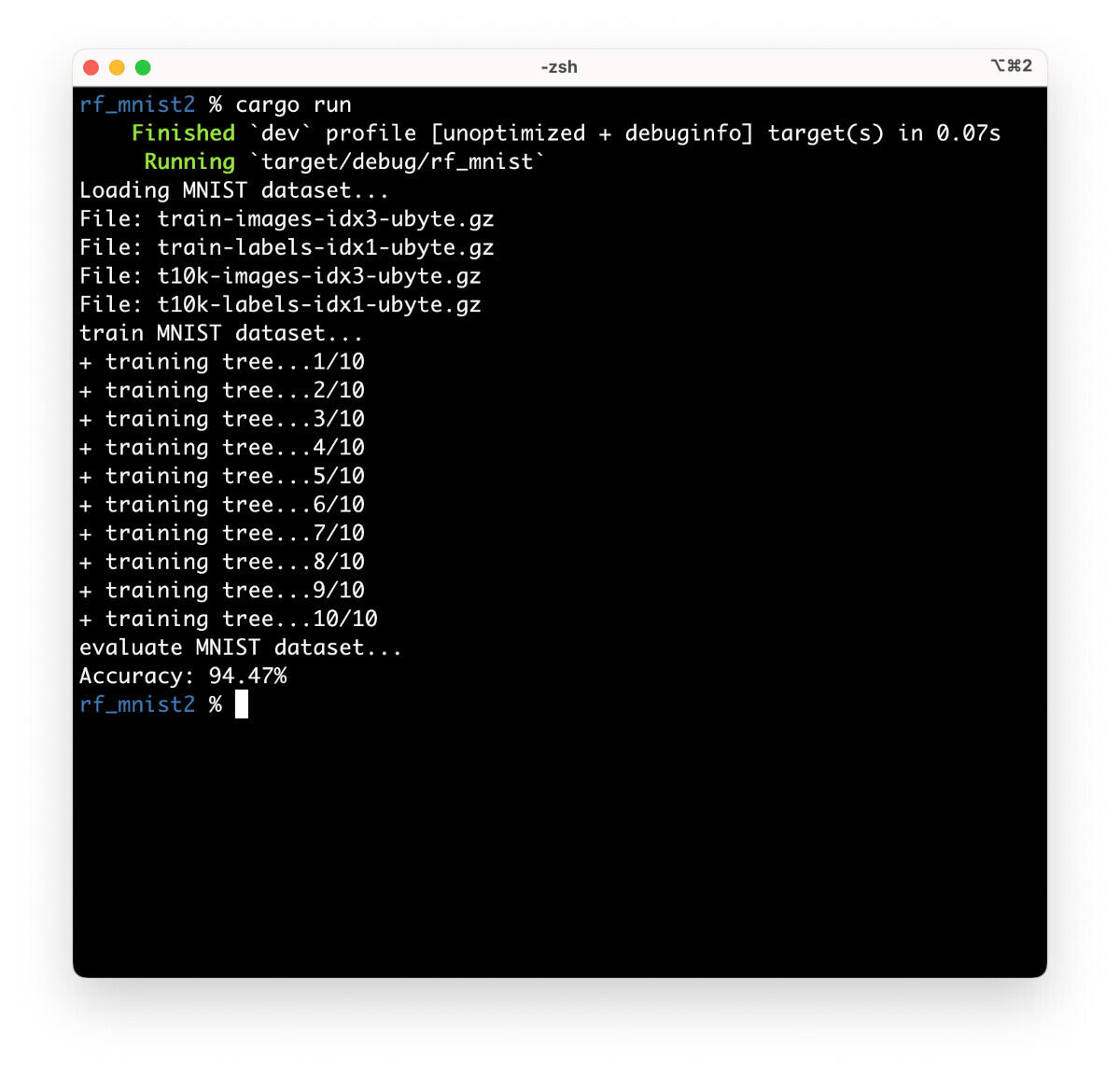
自作のランダムフォレストでMNISTデータセットを学習して精度をテストしたところ



なお、学習に時間はかかりますが、 RandomForest::trainメソッドのパラメータを変更すると、より良い精度がでます。データの学習を実行する部分を、下記のように書き換えると、判定精度が96.74%まで向上します。学習用に作った自作ライブラリとしては、この程度の精度が出れば十分でしょう。
let rf = RandomForest::train(&mnist, 100, 30, 10);
まとめ
以上、今回はゼロからランダムフォレストを実装して、手描き数字の画像データセットMNISTでどのくらいの精度が出るのかを試してみました。全貌を理解するには、機械学習の知識が必要となるのですが、ゼロからアルゴリズムを実装することで、その仕組みがなんとなく分かったのではないでしょうか。余力があれば、さらに精度を高める工夫をしたり、UIを作成して画像を入力すると結果が表示されるような仕組みを作ってみると良いでしょう。
自由型プログラマー。くじらはんどにて、プログラミングの楽しさを伝える活動をしている。代表作に、日本語プログラミング言語「なでしこ」 、テキスト音楽「サクラ」など。2001年オンラインソフト大賞入賞、2004年度未踏ユース スーパークリエータ認定、2010年 OSS貢献者章受賞。これまで50冊以上の技術書を執筆した。直近では、「大規模言語モデルを使いこなすためのプロンプトエンジニアリングの教科書(マイナビ出版)」「Pythonでつくるデスクトップアプリ(ソシム)」「実践力を身につける Pythonの教科書 第2版」「シゴトがはかどる Python自動処理の教科書(マイナビ出版)」など。