昨今、ChatGPTをはじめとする会話型AI(人工知能)が人気ですが、1990年代後半にも簡単な会話ができる「人工無能」と呼ばれる会話ボットが流行したことがありました。現代のAIに比べればほとんど役に立たないものですが、簡単に作成できて言葉遊びを楽しめて面白いものです。Rustの学習題材としてぴったりなので作成してみましょう。
-
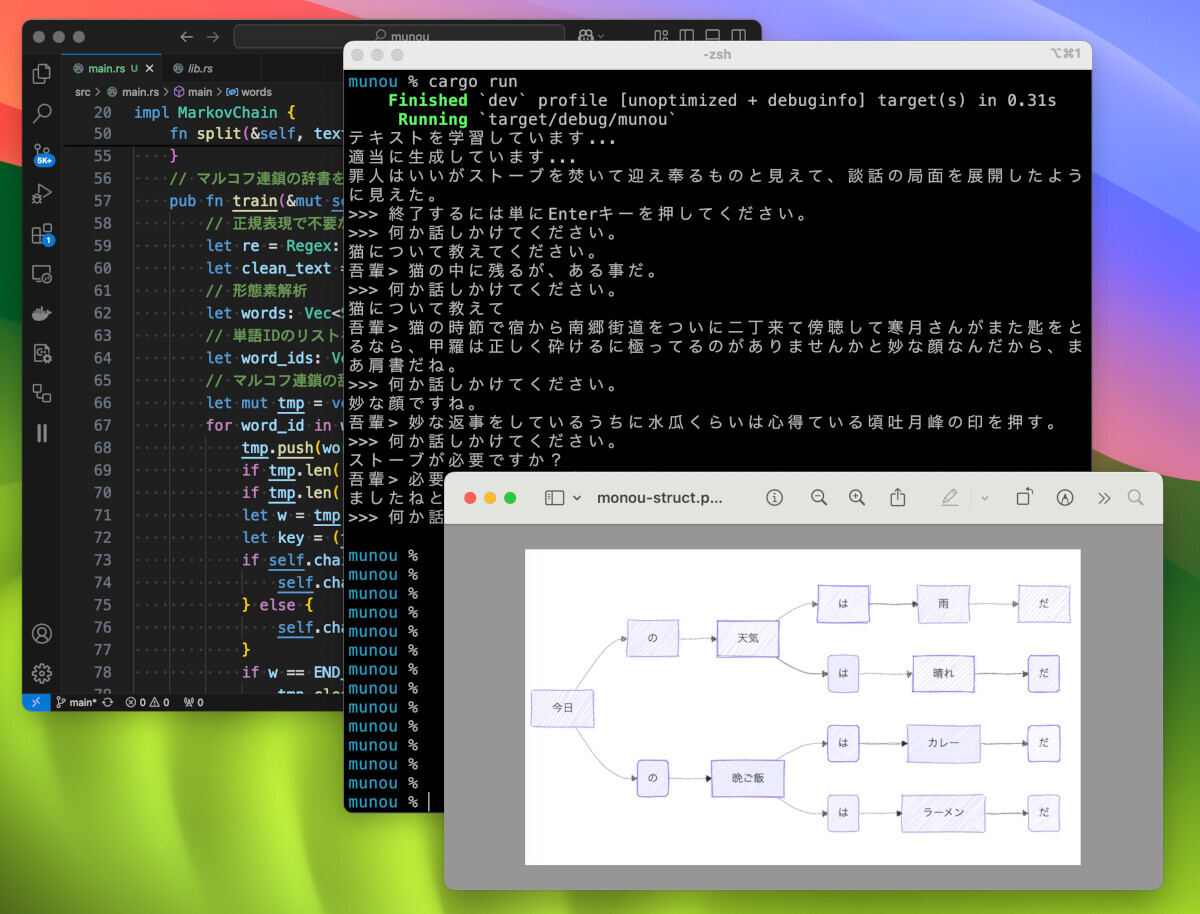
人工無能を実行したところ

会話型ボットのルーツ「人工無能」
SF小説や物語では、感情を持ったロボットが登場し、あたかも人間のように会話する場面が描かれます。日本のアニメでは、鉄腕アトムやドラえもんなど、とても親近感を覚えるロボットが登場します。昨今の会話型AIには感情はないものの、人間とまともな会話ができるという点では、理想のロボットに近づいていると言えるでしょう。
今回作成する人工無能は、インターネットが普及した1990年代後半から2000年代において、流行したものです。仕組みが単純であるため、掲示板に設置されたり、デスクトップマスコットに搭載されました。変な受け答えをすることから面白がられました。
人工無能の動作原理
人工無能の原理はとても簡単です。最初、学習の段階で、単語と単語のつながりを覚えておきます。そして、文章生成の段階で、ランダムに単語のつながりをたどって、テキストを生成します。
具体的には、「今日|の|天気|は|雨|だ」「天気|は|晴れ|だ」「今日|の|晩ご飯|は|カレー|だ」「晩ご飯|は|ラーメン|だ」という文章があったとしたら、次のような構造で登録します。そして、ランダムに矢印の進む先を選びます。そうすると、それっぽい文章が作成できるというものです。
-
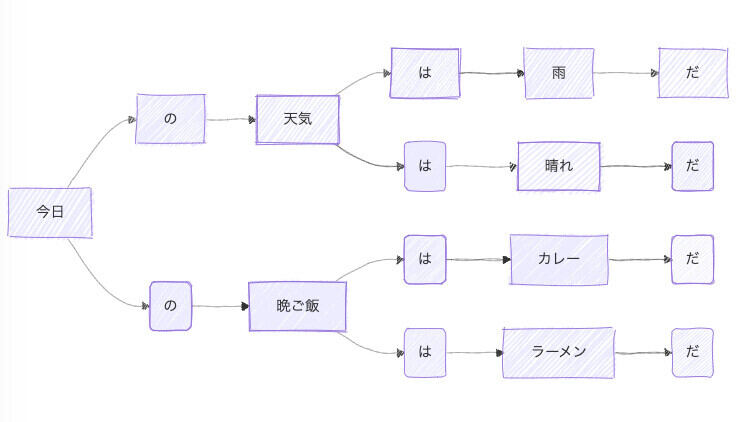
人工無能の辞書データ

プロジェクトを作成しよう
column
今回作成する人工無能のサンプルをこちら(https://kujirahand.com/blog/go.php?824)からダウンロードできるようにしています。下記で人工無能のプロジェクト作成の方法を紹介しますが、うまく動かせない場合に参考にしてください。
それでは、ターミナル(WindowsならPowerShell、macOSならターミナル.app)を起動して、次のコマンドを実行しましょう。
# プロジェクトを初期化
mkdir munou
cd munou
cargo init
# 形態素解析ライブラリをバージョン指定で追加
cargo add vibrato@=0.5.1
# プログラムを動かすのに必要なその他のライブラリを追加
cargo add zstd@=0.12.3
cargo add lazyrand
cargo add regex
形態素解析用の辞書をダウンロード
日本語の文章を単語に分割するために、形態素解析辞書ファイルのダウンロードが必要になります。こちら(https://github.com/daac-tools/vibrato/releases/tag/v0.5.0)から辞書ファイル「ipadic-mecab-2_7_0.tar.xz」をダウンロードしましょう。解凍して、中にある辞書データ「system.dic.zst」をフォルダ「monou」に保存してください。
学習用のテキストを用意しよう
人工無能に学習させるための日本語データを用意しましょう。ここでは、夏目漱石の小説「吾輩は猫である」を学習させてみましょう。青空文庫 こちら(https://www.aozora.gr.jp/cards/000148/card789.html)からテキスト形式をダウンロードして学習させましょう。解凍したアーカイブにあるテキストファイル「wagahaiwa_nekodearu.txt」をフォルダ「munou」にコピーしましょう。
ただし、青空文庫にあるテキストファイルは、文字エンコーディングがSHIFT_JISとなっており、別途エンコーディング変換のライブラリが必要になってしまいます。そこで、テキストエディタを利用して、「wagahaiwa_nekodearu.txt」をUTF-8に変換しておきましょう。
プロジェクトのファイル一覧
用意した辞書ファイルとテキストファイルが、下記のようなフォルダ構造になるように配置しましょう。
.
├── Cargo.lock
├── Cargo.toml
├── src
│ └── main.rs ……… メインプログラム
├── wagahaiwa_nekodearu.txt ……… UTF-8に変換した小説テキスト
└── system.dic.zst ……… 形態素解析の辞書
最初に、プログラムを実行してみましょう。メインプログラム「src/main.rs」に、こちら(https://gist.github.com/kujirahand/d713ee0e2301077e8b76070442ccd1af)にあるプログラムを書き込みましょう。
プログラムを書き込んだら、次のコマンドを実行しましょう。
cargo run
すると「吾輩は猫である」を読み込んで学習を行います。そして、下記のような文章を作成します。意味はよく分かりませんが、なんとなく夏目漱石っぽい文章が生成されます。
可哀相にヴァイオリンを小脇に掻い込んでひょろひょろと一枚岩を飛び下りて、いかに呑気でも、一つ懸けて来ました。
人工無能は学習した文章によって、大きく生成する内容が変わります。その後、ユーザーとの対話モードになりますが、対話の中に含まれる名詞を拾って作文をするようにしました。
例えば、「猫について教えてください。」と書くと次のように答えます。
吾輩> 猫は油断のなら世間に出されたものもなかったと今度は書斎から寝室へ来て立っている例は少なくない。
プログラムを確認しよう
人工無能のプログラムは、全体でも171行です。それほど長くないのですが、一度に全部見るには、ちょっと長いのでポイントだけを確認しましょう。
最初のポイントは、日本語の文章を形態素解析して、単語(正確には形態素)に分割する部分です。日本語は英語と違って単語がスペースで区切られていません。そのため、単語ごとに区切るには形態素解析を行う必要があります。
Rustにはいくつか形態素解析を行うライブラリがありますが、今回はvibratoというクレートを利用しました。vibratoが良い点は、有名な形態素解析ライブラリのMecabと互換性があり、Mecabの辞書をそのまま利用できる点にあります。今回のプログラムで、vibratoを呼び出している部分を抜粋して確認してみましょう。
辞書は圧縮されているので、これを読み込むには、zstd::Decoderを利用します。そして、Dictionary::readメソッドで形態素解析辞書を読み取ります。その後、Workerオブジェクトを生成して、reset_sentenceメソッドでテキストを設定し、tokenizeメソッドで実際に分割するという手順で形態素解析を行います。
impl MarkovChain {
pub fn new() -> Self {
// 形態素解析の辞書を読む
let reader = zstd::Decoder::new(fs::File::open("system.dic.zst").unwrap()).unwrap();
let dict = Dictionary::read(reader).unwrap();
MarkovChain {
// …
tokenizer: Tokenizer::new(dict), // トークナイザーを初期化
}
}
// 文章を形態素解析で分割する
fn split(&self, text: &str) -> Vec<String> {
let mut worker = self.tokenizer.new_worker();
worker.reset_sentence(text);
worker.tokenize();
worker.token_iter().map(|t| t.surface().to_string()).collect()
}
// …
}
続いて、人工無能の辞書データを定義を確認してみましょう。今回は、下記のような構造体を定義しました。ここでは辞書データに登録する単語をVec<String>型のwordsで管理します。そして、Vec型のインデックスを単語IDとすることにしました。単語IDと単語データの逆引き用にword_hashを用意しました。そして、マルコフ連鎖の辞書として、HashMap型のchainを用意しました。これは、(単語ID, 単語ID)のタプルをキーとして与えると、単語IDを返すというものです。つまり、単語1+単語2を与えると、それに続く単語3が得られるという単純なHashMapです。
// 人工無能の構造体
struct MarkovChain {
words: Vec<String>, // 単語のリスト
word_hash: HashMap<String, isize>, // 単語とIDの対応表
chain: HashMap<(isize, isize), Vec<isize>>, // マルコフ連鎖の辞書
tokenizer: Tokenizer, // 形態素解析器
}
それでは、実際に文章を辞書に登録するメソッドtrainを見てみましょう。最初に辞書に登録しない不要な文字列を削除します。そして、テキストを形態素解析を行って、形態素(単語ごと)に分割します。単語を3つずつに分けて、マルコフ連鎖のchainに登録します。
// マルコフ連鎖の辞書を作成する
pub fn train(&mut self, text: &str) {
// 正規表現で不要な文字を削除
let re = Regex::new(r"(《.*?》|[.*?]|[|\s\u{3000}\-]|[「」『』])").unwrap();
let clean_text = re.replace_all(text, "");
// 形態素解析
let words: Vec<String> = self.split(&clean_text);
// 単語IDのリストを作成
let word_ids: Vec<isize> = words.iter().map(|w| self.get_word_id(w)).collect();
// マルコフ連鎖の辞書を作成
let mut tmp = vec![TOP_WORD_ID, TOP_WORD_ID];
for word_id in word_ids {
tmp.push(word_id);
if tmp.len() < 3 { continue; }
if tmp.len() > 3 { tmp.remove(0); }
let w = tmp[2];
let key = (tmp[0], tmp[1]);
if self.chain.contains_key(&key) {
self.chain.get_mut(&key).unwrap().push(w);
} else {
self.chain.insert(key, vec![w]);
}
if w == END_WORD_ID {
tmp.clear();
tmp.push(TOP_WORD_ID);
}
}
}
ちなみに、人工無能では、辞書の登録の仕方がポイントになるのですが、下記の表のように、単語を3つずつに区切って登録します。w1とw2に連なる単語がw3になるようにします。つまり、HashMap型のchainに登録する際、(w1, w2)のキーに対して、w3が値になるようにするのです。
-
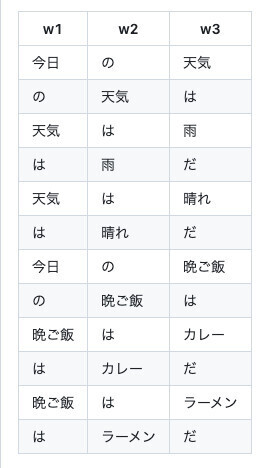
人工無能のテーブル



続いて、文章の生成処理を確認してみましょう。基本的には、単語w1とw2を元にして、w3を取り出すという処理になります。ただし、w3には複数のエントリがあるので、それをランダムに選び出すようにします。
// 次の単語IDを生成する
fn generate_next_id(&self, w1: isize, w2: isize) -> isize {
let w_ids = match self.chain.get(&(w1, w2)) {
Some(w_ids) => w_ids,
None => return END_WORD_ID,
};
if w_ids.is_empty() { return END_WORD_ID; }
lazyrand::choice(w_ids).unwrap()
}
// w1, w2に続く文章を生成する
pub fn generate_text(&self, w1: isize, w2: isize) -> String {
let mut result = String::new();
let mut w1 = w1;
let mut w2 = w2;
result.push_str(self.words[w1 as usize].as_str());
result.push_str(self.words[w2 as usize].as_str());
let mut w3;
loop {
w3 = self.generate_next_id(w1, w2);
result.push_str(self.words[w3 as usize].as_str());
if w3 == END_WORD_ID {
break;
}
w1 = w2;
w2 = w3;
}
result.replace("★", "")
}
まとめ
以上、今回は、Rustで人工無能を作る方法を紹介しました。短く分かりやすいプログラムにするため、機能を最小限に削りました。ユーザーの発言をパターンマッチで確認して、ふさわしい会話を返すようにすると、よりそれっぽくなります。
また、ユーザーと会話するたびに、ユーザーの発言を元にして、再度学習処理を行うようにもできるでしょう。人工無能の作成は、凝れば凝っただけ面白い会話ができるようになるので、いろいろ試してみると良いでしょう。
自由型プログラマー。くじらはんどにて、プログラミングの楽しさを伝える活動をしている。代表作に、日本語プログラミング言語「なでしこ」 、テキスト音楽「サクラ」など。2001年オンラインソフト大賞入賞、2004年度未踏ユース スーパークリエータ認定、2010年 OSS貢献者章受賞。これまで50冊以上の技術書を執筆した。直近では、「大規模言語モデルを使いこなすためのプロンプトエンジニアリングの教科書(マイナビ出版)」「Pythonでつくるデスクトップアプリ(ソシム)」「実践力を身につける Pythonの教科書 第2版」「シゴトがはかどる Python自動処理の教科書(マイナビ出版)」など。