Rustは実行効率や安全性を重視したプログラムが作れる人気のプログラミング言語です。それでも習得が難しいと言われることもあります。本連載ではいろいろな有名アルゴリズムを解くことでRustに慣れることを目的にしています。今回は、シーザー暗号を解いてみましょう。

Rustは難しい言語か?
RustはC/C++言語並みに実行効率が良いのですが、安全性を重視した言語になっています。最近では、ブラウザ上でもRustを快適に動かすことができるようになっており、ますます多くのプログラマーがRustを学んでいます。
-

Rustのメリット - RustのWebサイトより

とは言え、PythonやJavaScript、Rubyなどのスクリプト言語と比べたら難しいと感じる場面もあります。
まず、Rustはコンパイル言語であり、逐次実行するスクリプト言語とは大きく異なっています。また、スクリプト言語よりもデータ型に厳密です。加えて、スクリプト言語ではあまり意識することがなかった、メモリの扱いについても考える必要があります。
それでも、C/C++言語と比べて難しいかと言われると、筆者の個人的な感想で言えば、それほど難しくないのではと思います。C/C++ではメモリの確保と解放はプログラマーの責任で処理しなくてはなりません。メモリ管理の失敗によりアプリがクラッシュしたり、脆弱性の原因になったりします。
これに対して、Rustでは所有権システムにより、コンパイラにより自動で確保と解放が行われるため、そのため、それほど神経質にメモリ管理を意識する必要はありません。もちろん、Rustのメモリ管理の肝である所有権システムについては学ぶ必要がありますが、C/C++のポインタの概念と同じく、慣れの問題とも言えるでしょう。また、Rustの言語文法は新しい言語だけあって整然としており、複雑怪奇という訳ではありません。
どんな言語でも、最初はその言語について習熟するのに時間がかかるのは仕方のないことです。実際のところ、PythonやJavaScript、Rubyなどのスクリプト言語よりは難しいけど、C/C++よりは難しくないというところでしょう。本連載では定番アルゴリズムをRustで解いていくので、それらを眺めることで自然とRustに慣れることができます。
シーザー暗号とは?
連載2回目の今回は、Rustで『シーザー暗号(英語:Caesar cipher)』を実装してみます。このシーザー暗号は、最もシンプルで広く知られた暗号の一つです。古代ローマの軍事的指導者ガイウス・ユリウス・カエサルが使用したことで有名な暗号です。カエサルの英語読みがシーザーなので、シーザー暗号と呼ばれます。
その仕組みですが、アルファベットを辞書順で3文字ずらすことで作成する暗号です。次の図のように、[A]ならばB,C,Dと3文字ずらして[D]に、同様に、[B]ならば[E]、[C]ならば[F]とずらすことで暗号を作ります。
-
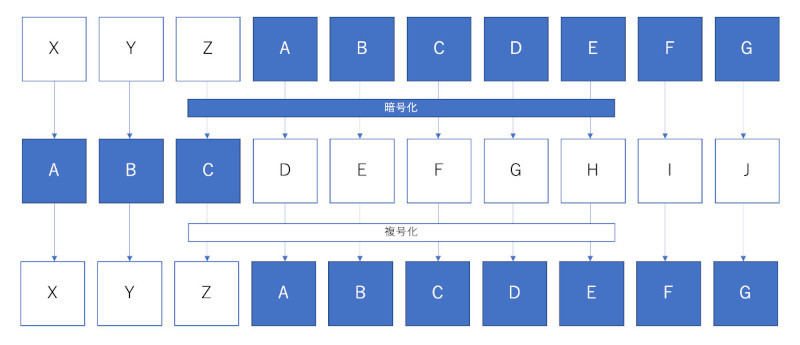
シーザー暗号の仕組み

例えば「CAFE」ならば、シーザー暗号で3文字右にずらして「FDIH」となります。逆に、暗号文「FDIH」を復号化するには、3文字左に文字をずらします。もちろん、同じ要領で任意の文字ずらす(シフトする)ことで、異なる暗号文を作ることもできます。
Rustで実装してみよう
それでは、このシーザー暗号をRustで実装してみましょう。Rustで実装する場合も、他の言語と同様に1文字ずつ暗号化したい文字を取り出して、指定文字数だけシフトさせて結果文字列に追加していくという処理を行います。
以下がシーザー暗号のプログラムです。以下を「caesar.rs」という名前で保存しましょう。
fn main() {
// 暗号化と復号化 --- (*1)
let text = "I LOVE YOU.";
let enc_text = rotate(&text, 3); // 暗号化
let dec_text = rotate(&enc_text, -3); // 復号化
println!("文字列: {}", text);
println!("暗号化: {}", enc_text);
println!("復号化: {}", dec_text);
}
// シーザー暗号を作成する関数 --- (*2)
fn rotate(text: &str, shift: i16) -> String {
// 変換結果を保存する文字列オブジェクト --- (*3)
let mut result = String::new();
// 1文字ずつ繰り返す --- (*4)
for ch in text.chars() {
// 小文字は大文字に変換 --- (*5)
let ch = if ch.is_lowercase() { ch.to_ascii_uppercase() } else { ch };
// 大文字のときのシフト処理 --- (*6)
if 'A' <= ch && ch <= 'Z' {
let a = 'A' as i16;
let enc = (((ch as i16) - a + shift + 26) % 26 + a) as u8;
result.push(enc as char);
}
else { // その他はそのまま文字を追加 --- (*7)
result.push(ch);
}
}
return result;
}
プログラムを確認してみましょう。Rustのプログラムはmainから始まります。(*1)のmain関数ではシーザー暗号の実行テストのため「I LOVE YOU.」という文を暗号化・復号化して表示します。ここでは、辞書順に3文字ずらします。そのため、(*2)で定義しているrotate関数を、暗号化の場合は3、復号化の場合は-3します。暗号化したい文を変えるには、この(*1)の変数textを変更します。
そして、暗号化の処理を行うのが(*2)のrotate関数です。この関数では、1文字ずつ確認し、変換後の文字を(*3)で初期化している変数resultに追記していきます。Rustで関数を定義する場合、引数にはデータ型を明示する必要があります。ただし、関数内のローカル変数は、型推論により自動的にデータ型が決定するので明示する必要ありません。今回のプログラムでも、データ型を明示したのは、関数の定義と、(*6)の文字型から文字コードへの変換の部分だけです。ここからRustの型推論が強力であることが分かります。
なお、Rustで変数定義する場合、「let 変数名 = 初期値」と書くと変更不可の変数となり、「let mut 変数名 = 初期値」と書くと可変の変数となります。昨今、無意味に可変の変数を使うことはトラブルの元になることが多いので、可変の変数を使う場合、可変であることを明示するという仕様になっています。
そして、(*4)では引数として与えられた変数textを1文字ずつfor文で繰り返します。(*5)では処理の簡易化のため、英数小文字を英数大文字に変換します。Rustではif文が値を返すことができるので、このように記述できます。
(*6)では英数大文字のときに、シフト処理(指定文字分ずらす処理)を行います。文字chの文字コードを得るのは簡単で「ch as i16」のように書きます。なお「i16」はデータ型で16ビット整数のことです。シフト処理ですが、単に3文字ずらすだけだと、アルファベットの範囲を超えてしまうので、割り算の余り演算子である「%」を利用して、アルファベットの範囲に収まるように工夫します。そしてシフト処理した文字は、変数resultに追記します。
また、(*7)の部分ですが、アルファベット以外の文字であれば変換対象外として、文字を何も変換せずにそのままresultに追記します。


プログラムを実行してみよう
それでは、プログラムをコンパイルして実行してみましょう。RustにはCargoというビルドシステムがありますが、今回はRustのコンパイラrustcを使ってコンパイルしてみます。ターミナルで以下のコマンドを実行しましょう。(「$」は入力可能を表す記号なので入力不要です。また、Windowsでは「/」を「\」と読み替えてください。)
# ソースコードをコンパイル
$ rustc caesar.rs
# 実行
$ ./caesar
上記コマンドを実行すると、次のように表示されます。「I LOVE YOU.」という文字列を暗号化し、さらに復号化して表示します。
-
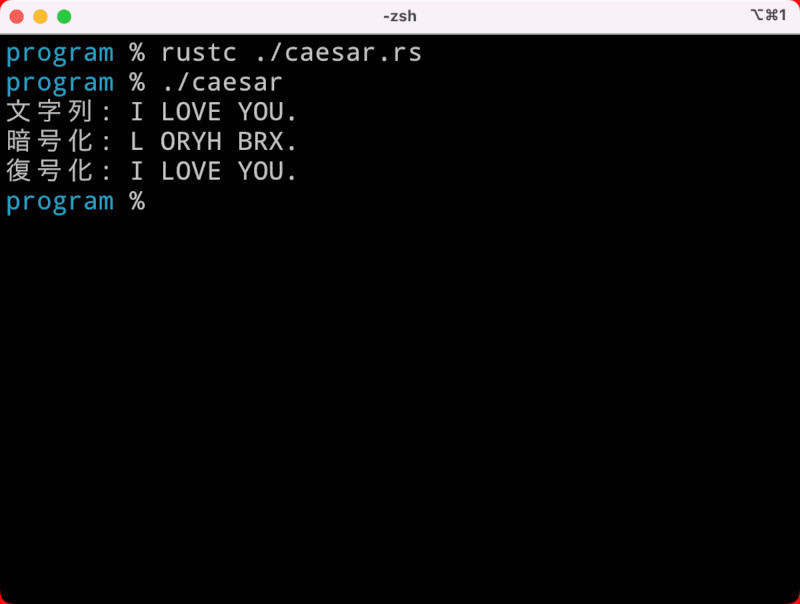
プログラムをコンパイルして実行したところ

まとめ
以上、今回はRustでシーザー暗号を実装してみました。もちろん、Rust初見だと、一体どうなっているのだろうと思う部分もあるでしょう。コメントを多く入れたので、少し長く見えますが、他の言語と比べても記述量が増えたわけではありません。逆にRustの型推論のおかげで、プログラムがスッキリと見えるのではないでしょうか。
なお、ここでは、コマンドラインツールとして作っていませんが、余力があれば、コマンドラインから使えるよう改良してみると良いでしょう。効率的にプログラミングを学ぶ一つの方法は、既存のプログラムを改良してみることです。挑戦してみてください。
自由型プログラマー。くじらはんどにて、プログラミングの楽しさを伝える活動をしている。代表作に、日本語プログラミング言語「なでしこ」 、テキスト音楽「サクラ」など。2001年オンラインソフト大賞入賞、2004年度未踏ユース スーパークリエータ認定、2010年 OSS貢献者章受賞。技術書も多く執筆している。直近では、「シゴトがはかどる Python自動処理の教科書(マイナビ出版)」「すぐに使える!業務で実践できる! PythonによるAI・機械学習・深層学習アプリのつくり方 TensorFlow2対応(ソシム)」「マンガでざっくり学ぶPython(マイナビ出版)」など。