



前回までの取り組みで、欲しかった機能はほとんど実装した。ただし、まだ無駄な処理が残っているので、若干修正して高速化を図る。すでに日常的に使えるレベルのスクリプトにはなっているので、後は実際に使っていく中で調整していけばよいだろう。
無駄な処理を考える
まず、前回の成果物を確認しておこう。Microsoft Edgeのヘッドレスモードを中心に、ヘッドレスモードでは取得できないコンテンツをcurlで取得するPowerShellスクリプト「netcat.ps1」だ。
#!/usr/bin/env pwsh
#========================================================================
# URLで指定されたリソースを取得
#========================================================================
#========================================================================
# 引数を処理
# -URL url WebリソースのURL
# -Agent agent リクエストで使うエージェントを指定
#========================================================================
Param(
[Parameter(Mandatory=$true)][String]$URL = "",
[String]$Agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64)"
)
#========================================================================
# Webリソース取得に利用するアプリケーション
#========================================================================
$msedge='C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe'
$curl='C:\Windows\System32\curl.exe'
#========================================================================
# Webリソースの種類を取得
#========================================================================
$ContentType=(& $curl --location `
-A $Agent `
-Ss -I `
$URL |
Select-String "^Content-Type:")
#========================================================================
# どの方法でWebリソースを取得するかを判断
#========================================================================
switch -Wildcard ($ContentType)
{
#================================================================
# HTMLコンテンツ: なるべくWebブラウザのヘッドレスモードを使用
#================================================================
'*text/html*' {
#========================================================
# Microsoft Edgeを使って取得
#========================================================
$method='msedge'
}
#================================================================
# それ以外のコンテンツは curl を使って取得
#================================================================
default {
#========================================================
# curlを使って取得
#========================================================
$method='curl'
}
}
#========================================================================
# Webリソースを取得
#========================================================================
switch ($method)
{
#================================================================
# Microsoft Edgeを使って取得
#================================================================
'msedge'
{
$o1='--headless'
$o2='--dump-dom'
$o3='--enable-logging'
$o4='--user-agent="$agent"'
$tmpf=New-TemporaryFile
Start-Process -FilePath $msedge `
-RedirectStandardOutput $tmpf `
-ArgumentList $o1,$o2,$o3,$o4,$URL `
-Wait
Get-Content $tmpf
Remove-Item $tmpf
}
#================================================================
# curl を使って取得
#================================================================
'curl'
{
& $curl --location `
-A $Agent `
-get $URL
}
}
このスクリプトの処理の本質的な部分は、次のようになる。
- curlでWebサーバからレスポンスヘッダを取得し、対象コンテンツの種類を取得する
- 種類がtext/htmlであればMicrosoft Edgeのヘッドレスモードで、それ以外の場合にはcurlでコンテンツを取得する
つまり、Webサーバとの通信が最低でも2回は発生していることになる。場合によってはこの処理は無駄だ。
例えば、URLの最後が「.html」になっていればHTMLだろうし、「.pdf」になっていればPDFだろう。わざわざWebサーバにコンテンツの種類を問い合わせるのは無駄だ。このようにURLからコンテンツの種類が明確にわかる場合には、Webサーバに問い合わせることなく種類を確定するようにする。これでWebサーバへの通信回数を減らすことができるので、処理の高速化を実現できる。


コンテンツ種類の判定処理を改良する
前回作成したPowerShellスクリプトの次の部分を改良すればよい。
#========================================================================
# Webリソースの種類を取得
#========================================================================
$ContentType=(& $curl --location `
-A $Agent `
-Ss -I `
$URL |
Select-String "^Content-Type:")
指定されたURLは$URL変数に入っているので、これをswitch構文で振り分けて処理を行うだけだ。前回作成した処理は、どの振り分けにも当てはまらなかった場合にのみ実行すればよいので、まずは次のように書き換える。
#========================================================================
# Webリソースの種類を取得
#========================================================================
switch -Wildcard ($URL)
{
ここにURLベースで種類を割り振り
default {
$ContentType=(& $curl --location `
-A $Agent `
-Ss -I `
$URL |
Select-String "^Content-Type:")
break
}
}
どこで事前の振り分け処理を行うかだが、それは頻繁にアクセスするURLを分析してその種類に応じて書いておけばよい。代表的なMIMEタイプ(コンテンツ種類)全てを書いておくのもありだが、この手のスクリプトは基本的に小さく見通しの良い状態にしておくことが望ましいので、使う分だけ追加することをお薦めする。
ここでは、以下のように処理を記述する。
#========================================================================
# Webリソースの種類を取得
#========================================================================
switch -Wildcard ($URL)
{
'*.html' {
$ContentType='text/html'
break
}
'*.htm' {
$ContentType='text/html'
break
}
'*.shtml' {
$ContentType='text/html'
break
}
'*.txt' {
$ContentType='text/plain'
break
}
'*.csv' {
$ContentType='text/csv'
break
}
'*csv=1' {
$ContentType='text/csv'
break
}
'*.pdf' {
$ContentType='application/pdf'
break
}
'*.zip' {
$ContentType='application/zip'
break
}
default {
$ContentType=(& $curl --location `
-A $Agent `
-Ss -I `
$URL |
Select-String "^Content-Type:")
break
}
}
.html、.htm、.shtml、.txt、.csv、csv=1、.pdf、zipについてそれぞれ事前にMIMEタイプを設定している。これに該当するURLに関しては、コンテンツ種類をWebサーバには問い合わせない。この分だけ処理が高速化するというわけだ。
高速化したスクリプト
今回の改良を取り込むと、netcat.ps1は次のようになる。
#!/usr/bin/env pwsh
#========================================================================
# URLで指定されたリソースを取得
#========================================================================
#========================================================================
# 引数を処理
# -URL url WebリソースのURL
# -Agent agent リクエストで使うエージェントを指定
#========================================================================
Param(
[Parameter(Mandatory=$true)][String]$URL = "",
[String]$Agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64)"
)
#========================================================================
# Webリソース取得に利用するアプリケーション
#========================================================================
$msedge='C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe'
$curl='C:\Windows\System32\curl.exe'
#========================================================================
# Webリソースの種類を取得
#========================================================================
switch -Wildcard ($URL)
{
'*.html' {
$ContentType='text/html'
break
}
'*.htm' {
$ContentType='text/html'
break
}
'*.shtml' {
$ContentType='text/html'
break
}
'*.txt' {
$ContentType='text/plain'
break
}
'*.csv' {
$ContentType='text/csv'
break
}
'*csv=1' {
$ContentType='text/csv'
break
}
'*.pdf' {
$ContentType='application/pdf'
break
}
'*.zip' {
$ContentType='application/zip'
break
}
default {
$ContentType=(& $curl --location `
-A $Agent `
-Ss -I `
$URL |
Select-String "^Content-Type:")
break
}
}
#========================================================================
# どの方法でWebリソースを取得するかを判断
#========================================================================
switch -Wildcard ($ContentType)
{
#================================================================
# HTMLコンテンツ: JavaScriptでコンテンツを表示するタイプのページ
# にも対応するため、なるべくWebブラウザのヘッドレスモードを使用
#================================================================
'*text/html*' {
#========================================================
# Microsoft Edgeを使って取得
#========================================================
$method='msedge'
break
}
#================================================================
# それ以外のコンテンツは curl を使って取得
#================================================================
default {
#========================================================
# curlを使って取得
#========================================================
$method='curl'
break
}
}
#========================================================================
# Webリソースを取得
#========================================================================
switch ($method)
{
#================================================================
# Microsoft Edgeを使って取得
#================================================================
'msedge'
{
$o1='--headless'
$o2='--dump-dom'
$o3='--enable-logging'
$o4='--user-agent="$agent"'
$tmpf=New-TemporaryFile
Start-Process -FilePath $msedge `
-RedirectStandardOutput $tmpf `
-ArgumentList $o1,$o2,$o3,$o4,$URL `
-Wait
Get-Content $tmpf
Remove-Item $tmpf
break
}
#================================================================
# curl を使って取得
#================================================================
'curl'
{
& $curl --location `
-A $Agent `
-get $URL
break
}
}
PowerShellスクリプトはこんな感じでシンプルにしておくと、後から機能追加や改良が行いやすい。改良したいと思ったらささっと書き換え、日々コツコツとスクリプトを育てていくのが、長期にわたって手を抜くためのポイントだ。
効果を確認する
では改良した効果を確認してみよう。比較的データの取得に時間がかかるケースで試してみる。まず、前回作成したPowerShellスクリプトでCSVデータを取得すると次のようになる。
PS C:\Users\daichi> time netcat.ps1 'https://gs.statcounter.com/chart.php?device=Desktop%20%26%20Mobile%20%26%20Tablet%20%26%20Console&device_hidden=desktop%2Bmobile%2Btablet%2Bconsole&multi-device=true&statType_hidden=browser®ion_hidden=ww&granularity=monthly&statType=Browser®ion=Worldwide&fromInt=202107&toInt=202207&fromMonthYear=2021-07&toMonthYear=2022-07&csv=1'
"Date","Chrome","Safari","Edge","Firefox","Samsung Internet","Opera","UC Browser","Android","IE","Instabridge","360 Safe Browser","QQ Browser","Yandex Browser","Edge Legacy","Whale Browser","Puffin","KaiOS","Mozilla","Coc Coc","Sogou Explorer","Sony PS4","Unknown","Maxthon","Chromium","Other"
2021-07,65.12,18.65,3.4,3.45,3.13,2.13,1.18,0.71,0.57,0,0.29,0.27,0.23,0.21,0.14,0.08,0.11,0.08,0.05,0.05,0.05,0.02,0.03,0.01,0.05
2021-08,64.94,18.75,3.57,3.55,3.06,2.17,1.1,0.66,0.58,0,0.27,0.25,0.23,0.22,0.13,0.08,0.11,0.08,0.06,0.05,0.04,0.02,0.03,0.01,0.04
2021-09,65.15,18.4,3.77,3.67,2.89,2.32,1.05,0.58,0.57,0,0.29,0.26,0.22,0.2,0.12,0.08,0.09,0.08,0.06,0.05,0.06,0.02,0.02,0.01,0.05
2021-10,64.67,19.06,3.99,3.66,2.81,2.36,0.97,0.57,0.5,0,0.31,0.24,0.22,0.11,0.11,0.07,0.06,0.08,0.05,0.05,0.03,0.01,0.02,0.01,0.04
2021-11,64.06,19.22,4.19,3.91,2.8,2.34,0.94,0.67,0.49,0,0.27,0.24,0.23,0.11,0.11,0.07,0.07,0.08,0.01,0.05,0.03,0.01,0.01,0.02,0.03
2021-12,63.8,19.6,3.99,3.91,2.85,2.35,0.94,0.68,0.46,0,0.27,0.26,0.26,0.09,0.11,0.07,0.07,0.08,0.04,0.06,0.03,0.01,0.01,0.02,0.04
2022-01,63.06,19.84,4.12,4.18,2.89,2.33,0.89,0.65,0.45,0.19,0.24,0.24,0.25,0.08,0.12,0.07,0.08,0.08,0.07,0.05,0.03,0.02,0.01,0.02,0.04
2022-02,62.78,19.3,4.06,4.21,2.77,2.26,0.86,0.65,0.47,1.21,0.23,0.23,0.22,0.15,0.11,0.07,0.1,0.08,0.07,0.05,0.03,0.02,0.01,0.02,0.04
2022-03,64.53,18.84,4.05,3.4,2.82,2.22,0.82,0.64,0.38,0.91,0.24,0.23,0.23,0.13,0.12,0.08,0.08,0.07,0.06,0.05,0.03,0.02,0.01,0.02,0.05
2022-04,64.34,19.16,4.05,3.41,2.85,2.07,0.84,0.76,0.39,0.66,0.26,0.24,0.23,0.16,0.11,0.09,0.07,0.08,0.06,0.05,0.03,0.03,0.01,0.02,0.04
2022-05,64.95,19.01,3.99,3.26,2.85,2.11,0.76,0.7,0.64,0.25,0.23,0.22,0.22,0.23,0.11,0.1,0.07,0.07,0.07,0.04,0.03,0.02,0.01,0.01,0.04
2022-06,65.87,18.61,4.13,3.26,2.87,2.11,0.71,0.68,0.29,0.21,0.22,0.21,0.22,0.06,0.11,0.1,0.05,0.07,0.08,0.04,0.03,0.02,0.01,0.01,0.03
2022-07,65.12,18.86,4.11,3.29,2.95,2.12,1,0.72,0.28,0.16,0.23,0.35,0.22,0.05,0.11,0.11,0.03,0.07,0.08,0.04,0.03,0.03,0.01,0.01,0.03
0.00user 0.01system 0:22.72elapsed 0%CPU (0avgtext+0avgdata 15436maxresident)k
0inputs+0outputs (4007major+0minor)pagefaults 0swaps
PS C:\Users\daichi>
Webサーバへのアクセスは2回発生しており、合計で22秒72かかっている。
では次に、今回作成したPowerShellスクリプトを実行してみる。
PS C:\Users\daichi> time netcat.ps1 'https://gs.statcounter.com/chart.php?device=Desktop%20%26%20Mobile%20%26%20Tablet%20%26%20Console&device_hidden=desktop%2Bmobile%2Btablet%2Bconsole&multi-device=true&statType_hidden=browser®ion_hidden=ww&granularity=monthly&statType=Browser®ion=Worldwide&fromInt=202107&toInt=202207&fromMonthYear=2021-07&toMonthYear=2022-07&csv=1'
"Date","Chrome","Safari","Edge","Firefox","Samsung Internet","Opera","UC Browser","Android","IE","Instabridge","360 Safe Browser","QQ Browser","Yandex Browser","Edge Legacy","Whale Browser","Puffin","KaiOS","Mozilla","Coc Coc","Sogou Explorer","Sony PS4","Unknown","Maxthon","Chromium","Other"
2021-07,65.12,18.65,3.4,3.45,3.13,2.13,1.18,0.71,0.57,0,0.29,0.27,0.23,0.21,0.14,0.08,0.11,0.08,0.05,0.05,0.05,0.02,0.03,0.01,0.05
2021-08,64.94,18.75,3.57,3.55,3.06,2.17,1.1,0.66,0.58,0,0.27,0.25,0.23,0.22,0.13,0.08,0.11,0.08,0.06,0.05,0.04,0.02,0.03,0.01,0.04
2021-09,65.15,18.4,3.77,3.67,2.89,2.32,1.05,0.58,0.57,0,0.29,0.26,0.22,0.2,0.12,0.08,0.09,0.08,0.06,0.05,0.06,0.02,0.02,0.01,0.05
2021-10,64.67,19.06,3.99,3.66,2.81,2.36,0.97,0.57,0.5,0,0.31,0.24,0.22,0.11,0.11,0.07,0.06,0.08,0.05,0.05,0.03,0.01,0.02,0.01,0.04
2021-11,64.06,19.22,4.19,3.91,2.8,2.34,0.94,0.67,0.49,0,0.27,0.24,0.23,0.11,0.11,0.07,0.07,0.08,0.01,0.05,0.03,0.01,0.01,0.02,0.03
2021-12,63.8,19.6,3.99,3.91,2.85,2.35,0.94,0.68,0.46,0,0.27,0.26,0.26,0.09,0.11,0.07,0.07,0.08,0.04,0.06,0.03,0.01,0.01,0.02,0.04
2022-01,63.06,19.84,4.12,4.18,2.89,2.33,0.89,0.65,0.45,0.19,0.24,0.24,0.25,0.08,0.12,0.07,0.08,0.08,0.07,0.05,0.03,0.02,0.01,0.02,0.04
2022-02,62.78,19.3,4.06,4.21,2.77,2.26,0.86,0.65,0.47,1.21,0.23,0.23,0.22,0.15,0.11,0.07,0.1,0.08,0.07,0.05,0.03,0.02,0.01,0.02,0.04
2022-03,64.53,18.84,4.05,3.4,2.82,2.22,0.82,0.64,0.38,0.91,0.24,0.23,0.23,0.13,0.12,0.08,0.08,0.07,0.06,0.05,0.03,0.02,0.01,0.02,0.05
2022-04,64.34,19.16,4.05,3.41,2.85,2.07,0.84,0.76,0.39,0.66,0.26,0.24,0.23,0.16,0.11,0.09,0.07,0.08,0.06,0.05,0.03,0.03,0.01,0.02,0.04
2022-05,64.95,19.01,3.99,3.26,2.85,2.11,0.76,0.7,0.64,0.25,0.23,0.22,0.22,0.23,0.11,0.1,0.07,0.07,0.07,0.04,0.03,0.02,0.01,0.01,0.04
2022-06,65.87,18.61,4.13,3.26,2.87,2.11,0.71,0.68,0.29,0.21,0.22,0.21,0.22,0.06,0.11,0.1,0.05,0.07,0.08,0.04,0.03,0.02,0.01,0.01,0.03
2022-07,65.12,18.86,4.11,3.29,2.95,2.12,1,0.72,0.28,0.16,0.23,0.35,0.22,0.05,0.11,0.11,0.03,0.07,0.08,0.04,0.03,0.03,0.01,0.01,0.03
0.01user 0.01system 0:10.62elapsed 0%CPU (0avgtext+0avgdata 15360maxresident)k
0inputs+0outputs (3985major+0minor)pagefaults 0swaps
PS C:\Users\daichi>
-
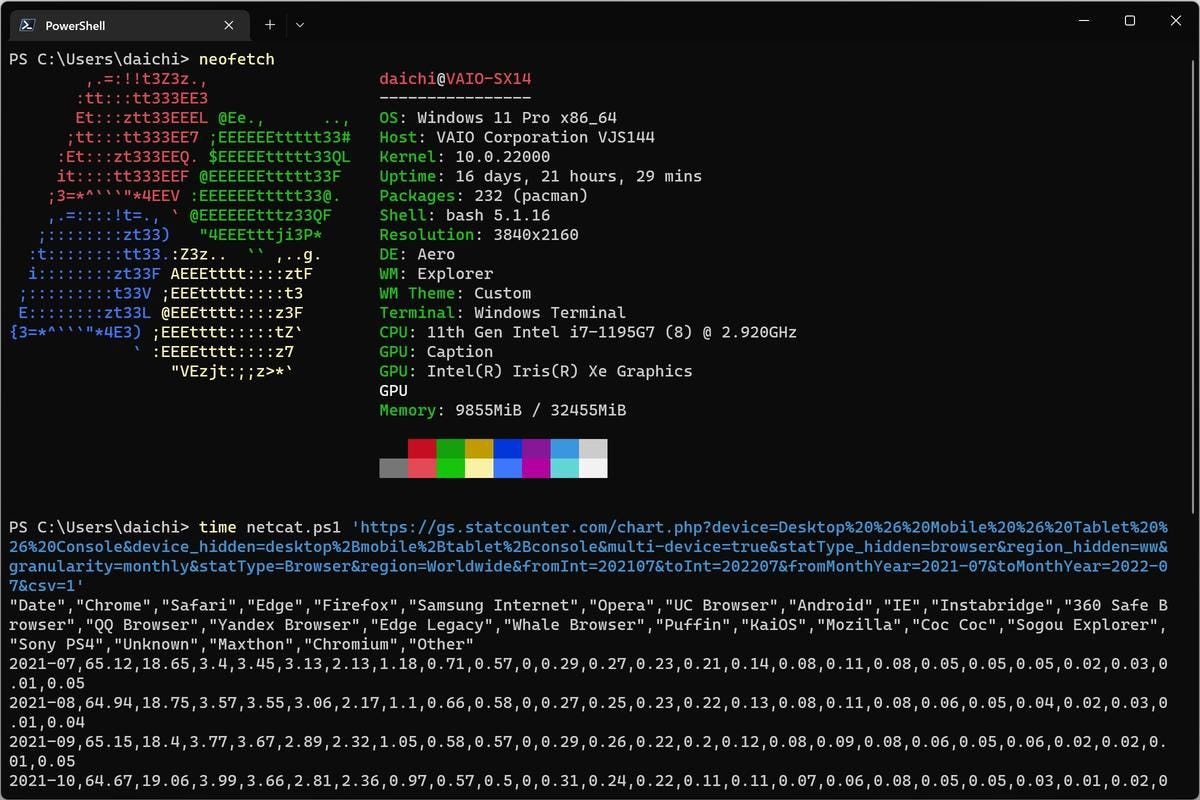
実行結果

こちらは10秒62だ。Webサーバへのアクセスが1回に減っているので、処理時間も半分ほどになっている。
このサーバの場合、もともとの処理時間がかなり長いのでこれだけはっきりした違いが出ているが、ほかのWebサーバでもある程度の高速化は確認できるはずだ。PowerShellスクリプトは、使い倒してこそ意味がある。たくさん便利なツールを作り、日々の作業負荷を低減させていこう。










