



前回まで、表示されるWebページのHTMLを自動的に取得する方法を解説してきた。今回からは、Webページの表示そのものをスクリーンショットとして取得するPowerShellスクリプトの作成に取り組んでいく。中身ではなく、見た目を自動的に保存しておきたいというケースもあるからだ。すでにこれを実現するための機能はいくつか存在しているので、それらを組み合わせて、Webページのスクリーンショットを自動取得するスクリプトを作成していく。
自動処理の始まりになる「netcat.ps1」
前回までに作成した「netcat.ps1」では、「curl.exe」と「Microsoft Edge」のヘッドレスモードを使ってWebページのHTMLを取得できるようにした。
netcat.ps1の注目ポイントは、Webページを取得する方法としてMicrosoft Edgeを使ったことで、JavaScriptを使ってコンテンツを表示するタイプのWebページにおいてもHTMLの取得ができるようにした点にある。こうした用途ではcurl.exeが使われることが多いのだが、curl.exeはJavaScriptを解釈しない。そのため、JavaScriptがそのまま取得されてしまうのだ。欲しいのは、Webページで閲覧したときのようにJavaScriptを実行した後の状態なので、JavaScriptを理解して実行するMicrosoft Edgeを使って表示されたHTMLを取得するようにした。
このようにしてHTMLが直接得られれば、さらにそこからデータを加工するといった自動処理につなげることができる。自動化の取っ掛かりとしてnetcat.ps1は有益だ。
Webページのスクリーンショットがほしい
Webページの自動取得に欲しくなってくるのが、スクリーンショットの自動取得だ。表示されているコンテンツのHTML自体を得ることはできるようになったわけだが、場合によっては表示されているそのままをスクリーンショットとして自動取得して利用したいことがある。
例えばデータのグラフが含まれたページや、画像データなどが含まれたページなどだ。こうしたページのデータは画像データとしてスクリーンショットを撮り、それをベースに報告書を作成するといったことを行いたいことがある。これまでは手動でこうした処理を行っていたかもしれないが、自動的に取得できればある程度作業を自動化させることができる。業務の作業時間短縮に効果的な方法だ。
具体的な利用方法は、今後PowerShellスクリプトを作っていく上で示してく。


Webブラウザの表示している内容をそのまま画像データで保存したい
「Webページのスクリーンショット」とは、「Webブラウザで見ている状態」そのものだ。Webブラウザの機能を使うと、表示しているページの内容をそのまま画像で保存することができるが、それと同じことをPowerShellスクリプトで行いたいということになる。
例えば、Microsoft Edgeで「https://docs.microsoft.com/ja-jp/powershell/」にアクセスすると次のようになる。
-
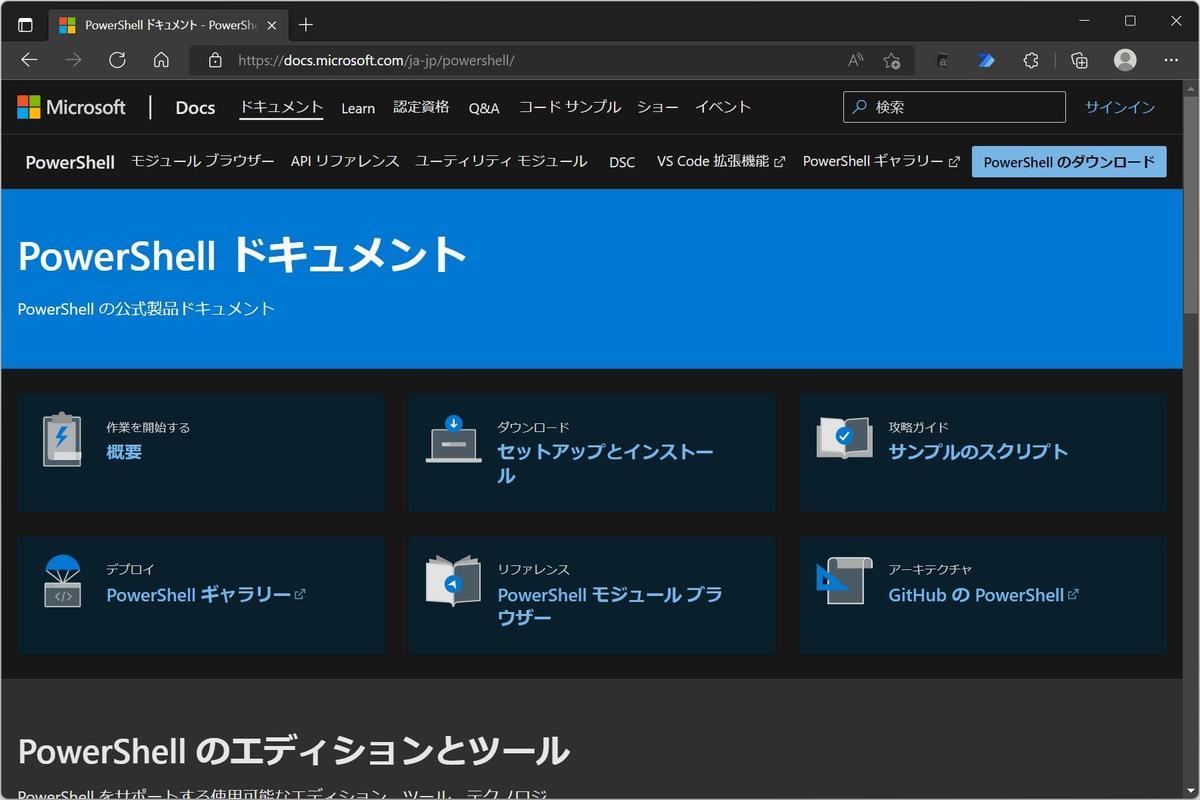
Microsoft Edgeで「PowerShellドキュメン」を閲覧

これをそのまま画像データに保存したいといった感じだ。開発者モードを使えば画像データとして保存することができるし、例えばMozilla Firefoxであればブラウザの機能としてページを画像で保存できるようになっている。拡張機能をインストールしても似たようなことはできる。つまり、すでに機能として表示していない内容を保存する機能は存在しているということだ。
Webブラウザのヘッドレスモードを使う
Webページのレンダリングに関してはやはりWebブラウザの実装が一番進んでいる。最新バージョンのWebブラウザを使うことで、良い結果を得やすい。
そしてnetcat.ps1で使用したWebブラウザ(Microsoft Edge)のヘッドレスモードには、Webページの内容を画像として保存する機能が用意されている。これは今回欲しい機能そのものだ。
Microsoft Edge (msedge.exe)の場合、「--headless」のオプションでヘッドレスモードで動作するようになったことはこれまで取り上げてきた通りだ。このソフトウエアにはさらに「--screenshot」というオプションが用意されており、表示した内容をPNGファイルとして保存することができるようになっている。
「--screenshot」ではファイルをフルパスで指定する。ためしに、先ほどMicrosoft Edgeで閲覧したWebページ「https://docs.microsoft.com/ja-jp/powershell/」をこの方法で画像に落とし込むと次のようになる。
Microsoft Edgeのヘッドレスモードでスクリーンショットを取得
& 'C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe' --headless --screenshot=C:\Users\daichi\ss.png https://docs.microsoft.com/ja-jp/powershell/
-
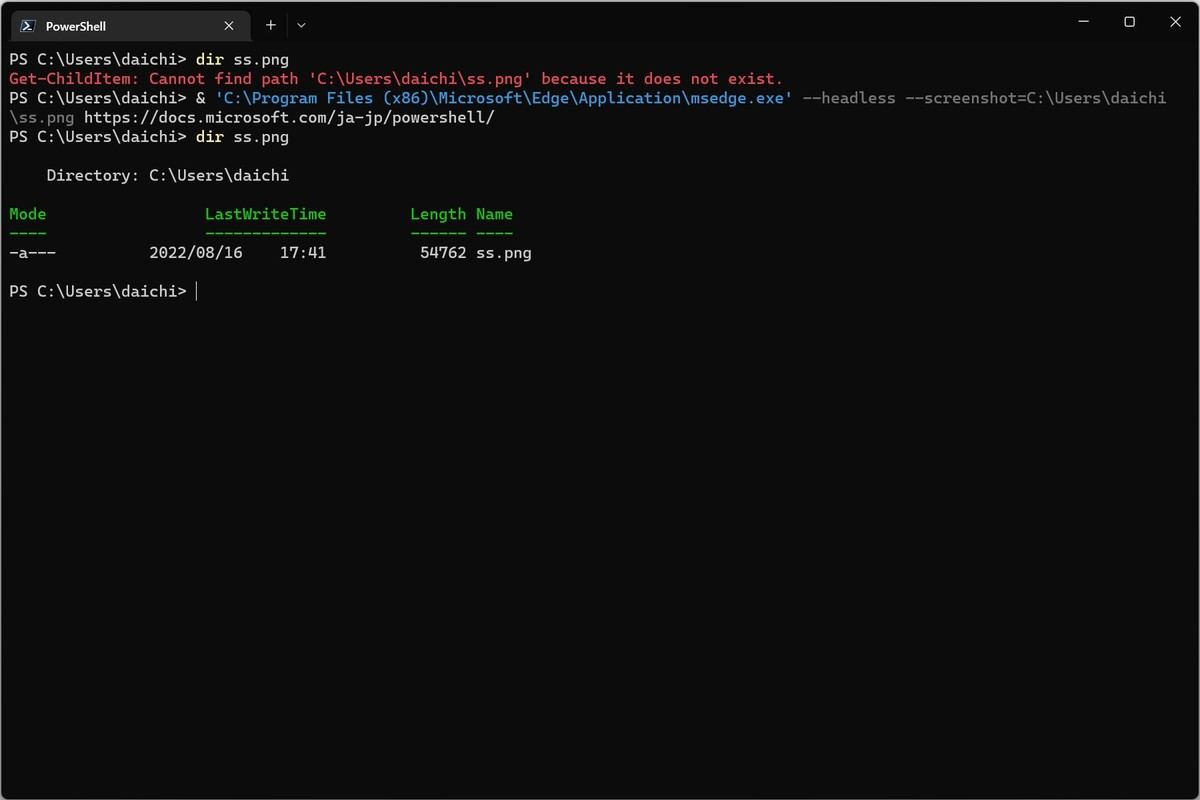
Microsoft Edgeのヘッドレスモードでスクリーンショットを取得

得られた画像ファイルを閲覧すると次のようになる。
-
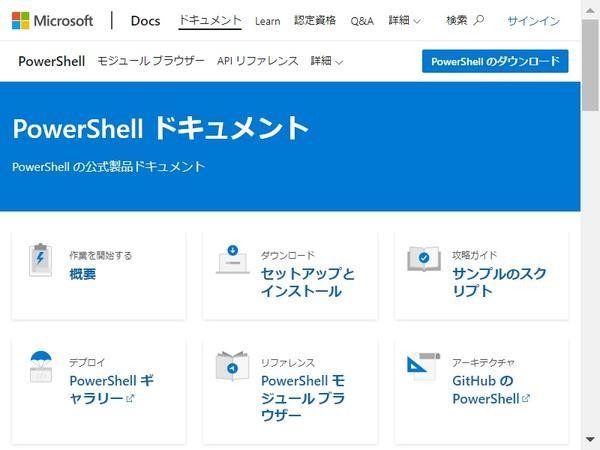
取得したスクリーンショット

Webブラウザのウインドウが表示されることなく、Webページのレンダリング結果が画像で保存されていることがわかる。
このままではまだ使い物にならないが、整理していけば汎用的なPowerShellスクリプトとして便利に使えるようになる。
netcat.ps1の経験をとりこみながら作っていく
Microsoft Edgeヘッドレスモードのスクリーンショット取得機能を使って、Webページのスクリーンショットを取得するPowerShellスクリプト「getss.ps1」(get screenshot powershell script)を作っていく。Microsoft Edgeのヘッドレスモードを使うし、取得する対象がテキストファイルか画像データかの違いなだけでnetcat.ps1もgetss.ps1も似たような構造になるので使い回しが効く。
getss.ps1はWebページのみならず、さまざまなスクリーンショット、たとえばデスクトップのスクリーンショットを撮るといった用途にも使用できる。こうした拡張も考慮しつつPowerShellスクリプトにまとめていく。








