NVLinkとNVSwitch
V100 GPUは6本のNVLink2のポートを持っており、2つのGPUを6本のNVLink2で直結接続すると150GB/sの高バンド幅の接続とすることができる。そして、一方のGPUからXBAR、HUB、NVLink2を通って反対側のGPUに接続し、NVLink2、HUB、XBAR、L2キャッシュを通して、反対側のGPUに接続されているHBM2メモリをアクセスできる。この逆に、向こう側のGPUがNVLink2のブリッジを通ってこちら側のHBM2メモリをアクセスすることもできる。
PCIeバスは32GB/sであるが、6本を束ねたNVlinkは双方向の合計のバンド幅は300GB/sであり、PCIeの約10倍という圧倒的に高いバンド幅を持っている。
-

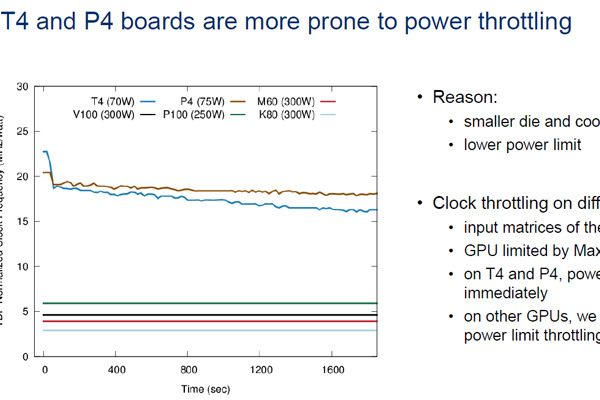
2つのV100 GPUを6本のNVLink2を並列に使って接続すると150GB/s×2の高バンド幅の接続ができる

3個のGPUを接続する場合は、NVLinkは1対1で接続する必要があるので、GPU間の接続リンク数は減少してしまうが、3リンク並列の接続を行うことができる。なお、この接続ではもっと多くのGPUをつなぐことはできず、この構成はスケーラブルではない。
-
3個のV100を接続する場合は、相互の接続には3リンクを使い、リング状に接続する

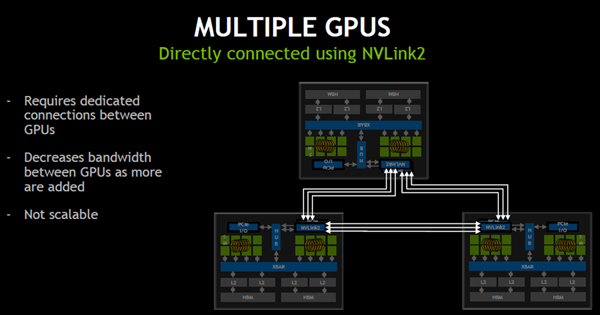
NVSwitchは18ポートを持ち、任意のポート間の接続ができるスイッチであり、次の図のように3つのGPUとスイッチ間をそれぞれ6本のリンクで接続することができる。このネットワークでは、どのGPUも最大150GB/s×2でデータの送受ができる。
-
NVSwitchは18ポートを持ち、各GPUは最大150GB/s×2でデータの送受を行うことができる

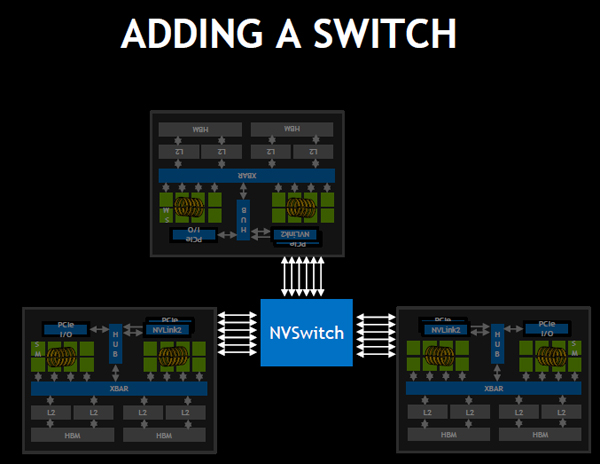
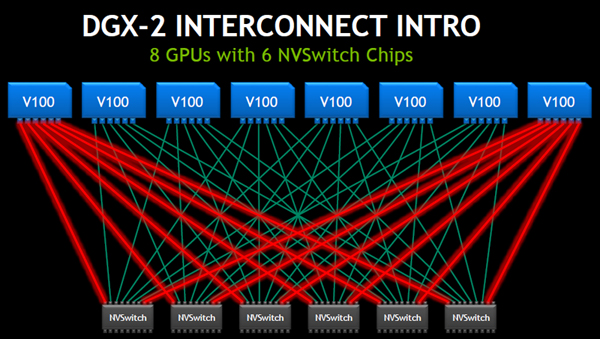
そして、NVSwitchの数を増やして、次の図のように接続すれば、8個のGPUを6個のNVSwitchで接続することができる。
なお、この接続ではNVSwitchの下側のポートが空いており、ここを使って上側と同じように8個のGPUを接続することが可能である。
-
8個のV100 GPUを6個のNVSwitchを使って、この図のように接続すれば、各GPUは150GB/sで送受ができるようになる

なお、この接続では赤でハイライトしたリンクを生かせば。左端と右端のGPUペアの間に6本のリンクがあるという接続ができる。また、同様に、任意のGPUペアの間に6本のリンクを持たせることができ、GPU間で最大150GB/sの通信ができるようになっている。そして、特定のGPUペアだけでなく、すべてのGPUが150GB/sで送信し、150GB/sで受信することができる。
-
赤でハイライトしたリンクを使えば左端と右端のGPUの間に6本の並列リンクが存在することになる

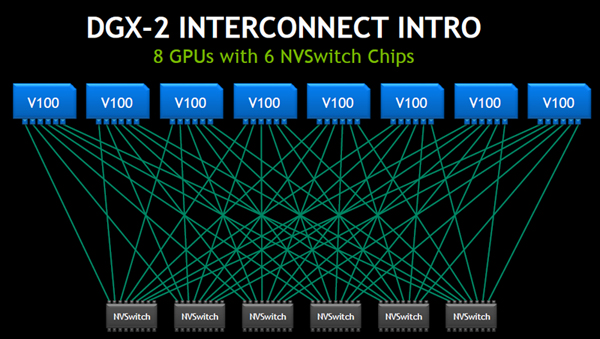
DGX-2全体のNVLink2の接続は、次の図のようになっている。この接続は前述の6スイッチで8個のGPUをつなぐ接続を2組作り、NVSwitchの空いているポートを緑の線のリンクで直結している。これはDGX-2では8GPUのベースボードを上下に積み、その間を直結の短いケーブル(実際は両端にコネクタが付いた多層プリント板の配線)で結びたいという実装上の要求から使われた構成であり、前述のように、ネットワーク的には12個のスイッチは不要であり、6個のNVSwitchで16個のV100 GPUを接続することができる。
-
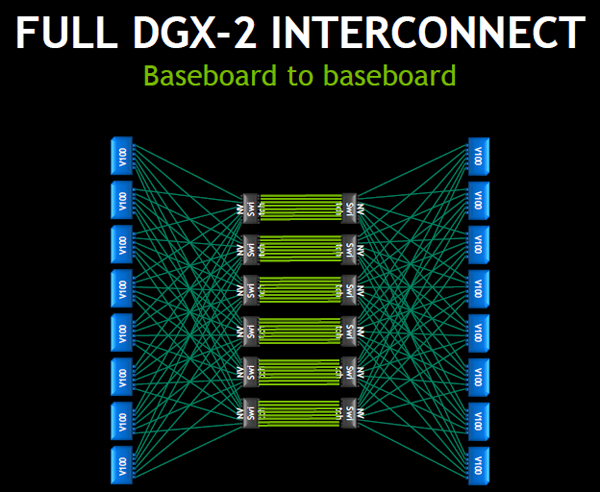
12個のNVSwitchを使って16個のV100 GPUを接続するDGX-2のネットワーク

NVLinkを通ってデータを移動させるには、塊でまとめて移動させる方法と、1語ずつ移動する方法がある。塊でデータを移動させるには、コピーを行うDMAエンジンを使う。CUDAで言えばcudaMemcpy()を呼び出す。
SMがメモリのアドレスを指定してアクセスを行えば1語を読んだり、書いたりすることができる。LOAD、STOREやATOMオペレーションでスレッド当たり1~16バイトのメモリをアクセスできるので、LOADでメモリを読み、別のアドレスにSTOREすれば語単位でデータの移動ができる。
-

NVLinkでデータを移動するには、DMAを使って塊で移動する方法と、LOAD、STOREで語単位で移動する方法がある

DGX-2には2個のXeon 8168 CPUが搭載されており、SMからPCIeを経由してCPUの1.5TBの容量のホストメモリをアクセスすることができる。それぞれのCPUから2本のPCIeバスが出ており、全体では4本のPCIeがある。
これらのPCIeバスを経由して、GPUからホストメモリを読み書きするバンド幅は約50GB/sである。
-
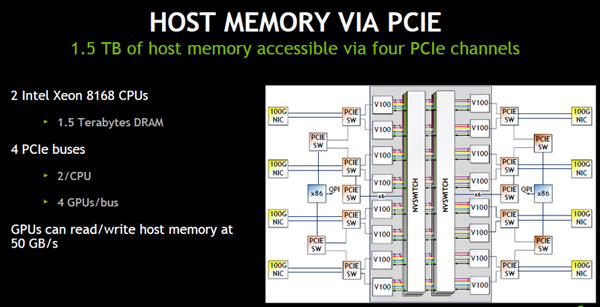
DGX-2の2個のCPUには合計1.5TBのホストメモリが付いている。GPUから4本のPCIeを経由してホストメモリを読み書きするバンド幅は約50GB/sである

次のグラフは、16個のGPUそれぞれにホストメモリを読むカーネルを10秒おきに起動した場合に、ホストメモリの使用バンド幅を示す図である。DGX-2には4本のPCIeがあるので、4個のGPUが一本のPCIeバスを共用することになる。この図では、まず、1つの転送が開始されて全体で12GB/s程度の転送が行なわれ、動作するカーネルが増えても、1つのPCIeを共用するので、使用バンド幅は若干の増加にとどまる。40秒後に次のGPUの転送が開始されると次のPCIeが使われ、使用するバンド幅が25GB/s弱になる。そして、80秒後には3番目のGPUの転送が始まり、120秒後には4番目のGPUの転送が始まり50GB/sに近いバンド幅が実際に使われていることが分かる。
-

ホストメモリを最高速度で読むカーネルを10秒おきに起動した場合のホストメモリの使用バンド幅を示すブラフ。PCIeが4本であるので、4GPUが起動されるごとに大きく使用バンド幅が増えている

(次回は4月18日に掲載します)