今回は、散布図に関連する話として、2つのデータの相関性を調べる関数CORREL()の使い方を紹介していこう。相関係数を求めることで、「本当に2つのデータに関連性があるのか?」を見極める手法として活用していただければ幸いだ。
相関性とは?
相関性とは、「2つのデータがどれくらい密接に関わっているか?」を示したものとなる。簡単に言えば、
・一方の数値が「増加」すれば、もう一方の数値も「増加」する
・一方の数値が「減少」すれば、もう一方の数値も「減少」する
といった比例の関係性にあることを示す用語となる
具体的な例を使って解説していこう。以下の図は、ある企業が「商品A」のWeb広告を出稿した際に、「広告が表示された回数」と「商品Aの売上金額」について記録したものとなる。12週間にわたってWeb広告を出稿したが、週ごとに広告予算を変化させたため、Web広告の「表示回数」は週によって大きく異なる(表示回数ゼロの週もある)。
-
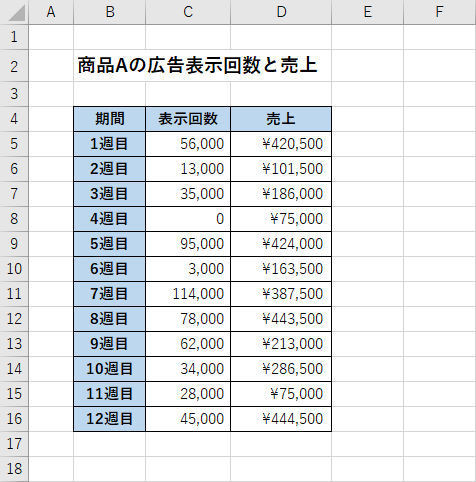
広告の「表示回数」と「売上」をまとめた表(商品A)

一般的に考えると、Web広告の「表示回数」が多くなるほど、商品Aを目にするユーザーの数も多くなり、その結果、商品Aの「売上」も増える、と期待したいものである。
上記の表を見ると、そのような傾向がありそうな気もするが、正確なところは把握しづらい。このような場合に活用できるのが「相関係数」を求める関数CORREL()である。
相関係数を求める関数関数CORREL()の使い方
それでは、関数CORREL()の使い方を紹介していこう。関数CORREL()は、以下に示した書式で記述する。
=CORREL(セル範囲,セル範囲)
基本的には、第1引数に「1つ目のデータのセル範囲」、第2引数に「2つ目のデータのセル範囲」を指定すればよい。
先ほど例として示した、Web広告の「表示回数」と「売上」について相関性を調べてみよう。まずは関数CORREL()を入力し、第1引数にWeb広告の「表示回数」が入力されているセル範囲を指定する。
-
関数CORREL()の入力-1
続いて、第2引数に「売上」のデータが入力されているセル範囲を指定する。
-
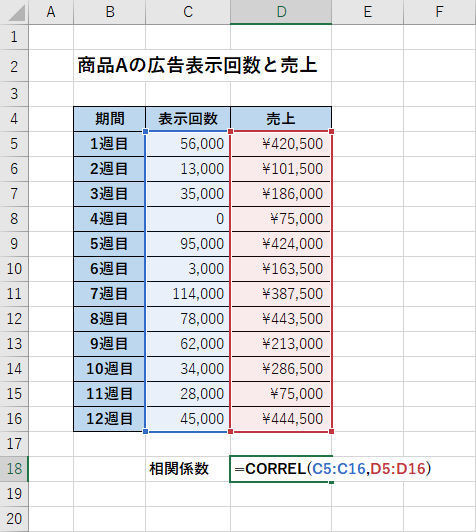
関数CORREL()の入力-2

「カッコ閉じ」を入力して[Enter]キーを押すと、計算結果が表示される。今回の例では、0.7618・・・という数値が表示された。
-
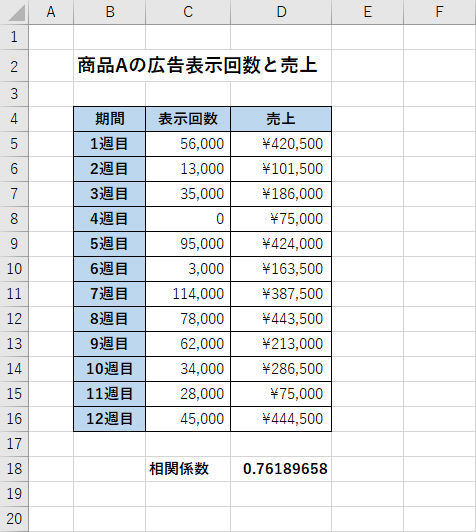
関数CORREL()の計算結果

この計算結果は「相関係数」と呼ばれるもので、必ず-1~1の値が算出される仕組みになっている。まずは、相関係数が0~1の場合について分析方法を解説していこう。
相関係数は1に近づくほど「相関性がある」、0に近づくほど「相関性がない」ということを示す指標になる。もう少し具体的に書くと、
0.9~1.0・・・かなり強い相関性がある
0.7~0.9・・・強い相関性がある
0.4~0.7・・・相関性がある
0.2~0.4・・・弱い相関性がある
0.0~0.2・・・ほとんど相関性はない
という結論になる。
先ほど示した例の場合、相関係数は0.7618・・・と表示されたので「強い相関性がある」という結論になる。言い換えると、Web広告の「表示回数」増えれば増えるほど「売上」も増加していく、と考えられる訳だ。つまり、「費用をかけてWeb広告を出稿することに意味がある」と考えられる。
結果を比較しやすくために、もうひとつ例を紹介しておこう。以下の表は、「商品B」について同様の実験を行った結果である。
-
広告の「表示回数」と「売上」をまとめた表(商品B)
これらのデータについても関数CORREL()で相関係数を求めてみると、以下のような計算結果が表示された。
-
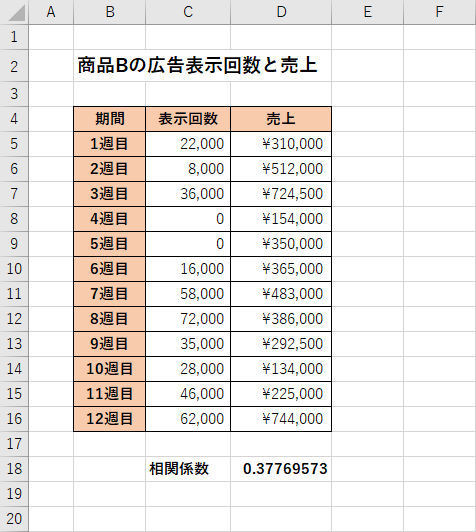
関数CORREL()の計算結果

この結果を見ると、商品BにおけるWeb広告の「表示回数」と「売上」の相関係数は0.3776・・・になることが分かる。つまり、「弱い相関性がある」ことになる。言い換えると、「相関性が全くないとは言わないが、商品Aほどの効果はない」という結論になる。
このように関数CORREL()を使うと、「2つのデータがどれくらい密接に関わっているか?」を調べることができる。今回の例では、Web広告を出すなら「商品A」を重視したほうが効果的である、という結果になる。
相関係数の算出は、さまざまな分野に応用でき、また手軽に実行できる分析手法なので、ぜひ覚えておくとよいだろう。
負の相関について
参考までに、相関係数が負の値(-1~0)になった場合の考え方も解説しておこう。この場合は、相関係数が-1に近づくほど「負の相関性」が強くなり、0に近づくほど相関性は弱くなっていく。
「負の相関性」とは、一方の数値が「増加」すれば、もう一方の数値は「減少」していく、という関係性を示している。具体的な例としては、「料金を高く設定するほど、利用者の数は減っていく」、「ゴミ箱の設置数を増やせば、ポイ捨ての数は減っていく」などが挙げられるだろう。
こちらも相関係数を使ってデータを分析するときの知識として覚えておくとよい。
散布図を使った相関性の確認
2つのデータの相関性を調べるときは、散布図を作成するのも効果的だ。以下の図は、先ほど示した「商品A」について、Web広告の「表示回数」と「売上」を散布図にまとめ、近似曲線(線形近似)を表示したものとなる。
※「散布図の作成方法」ならびに「近似曲線の表示方法」は、本連載の第38~41回を参照。
-
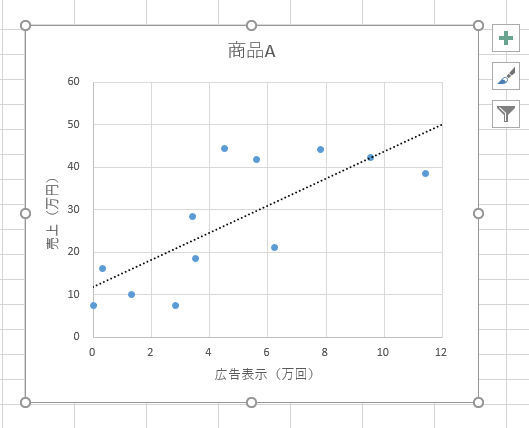
商品Aの散布図

このグラフを見ると、近似曲線の近くに多くのデータが集まっていることが確認できる。同様に「商品B」についても散布図を作成すると、以下の図のようになる。
-
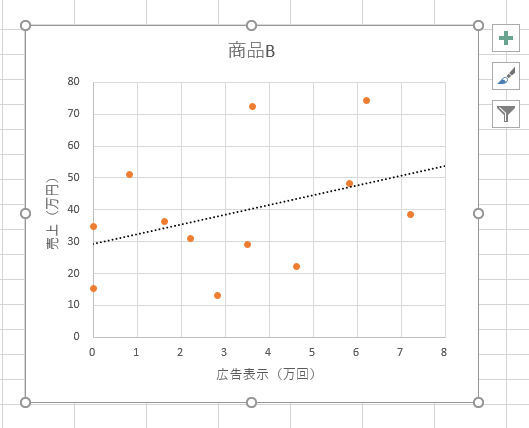
商品Bの散布図

こちらは、近似曲線から離れた場所にもデータが点在しているグラフとなる。つまり、それだけ相関性が小さい、と考えられる。
このように散布図を見ることで、ある程度の相関性を把握することも可能である。とはいえ、結果が数値として示される「相関係数」のほうが“曖昧さ”がなくなり、使い勝手がよいのも事実。関数CORREL()で相関係数を求める方法と、散布図&近似曲線でデータ分布を確認する方法、の両方を学んでおけば、より正確にデータを分析できるだろう。
今回は、関数CORREL()の使い方と計算結果の見方を解説したが、これだけでは「相関係数がどのように算出されているか?」がブラックボックス状態になってしまう。そこで、より深く知りたい方のために、次回は相関係数の算出方法を紹介していこう。