今回から、PythonとPythonのライブラリ「Pandas」を用いてExcelデータの効率的な処理方法について説明していく。まずは、請求データの抽出と絞り込みに焦点を当て、請求データを「会社名」と「対象月」をもとに選別する。
さらに、ExcelファイルをPandasで読み込む際のデータ型の重要性やスクリプトの汎用性を高めるための改良方法も示す。Pythonを使ったExcel作業の効率化に興味のある場合は押さえておきたい内容だ。
連載「PythonでExcel作業の効率化を図ろう」のこれまでの回はこちらを参照。
Pandasを使い、2つの条件で請求データを絞り込む
今回は、請求書の請求データを取り出す部分を実装する。請求書テンプレートでは次のスクリーンショットのように「項目名(説明)」、「単価」、「数」にハメ込むデータを抜き出す処理だ。
-
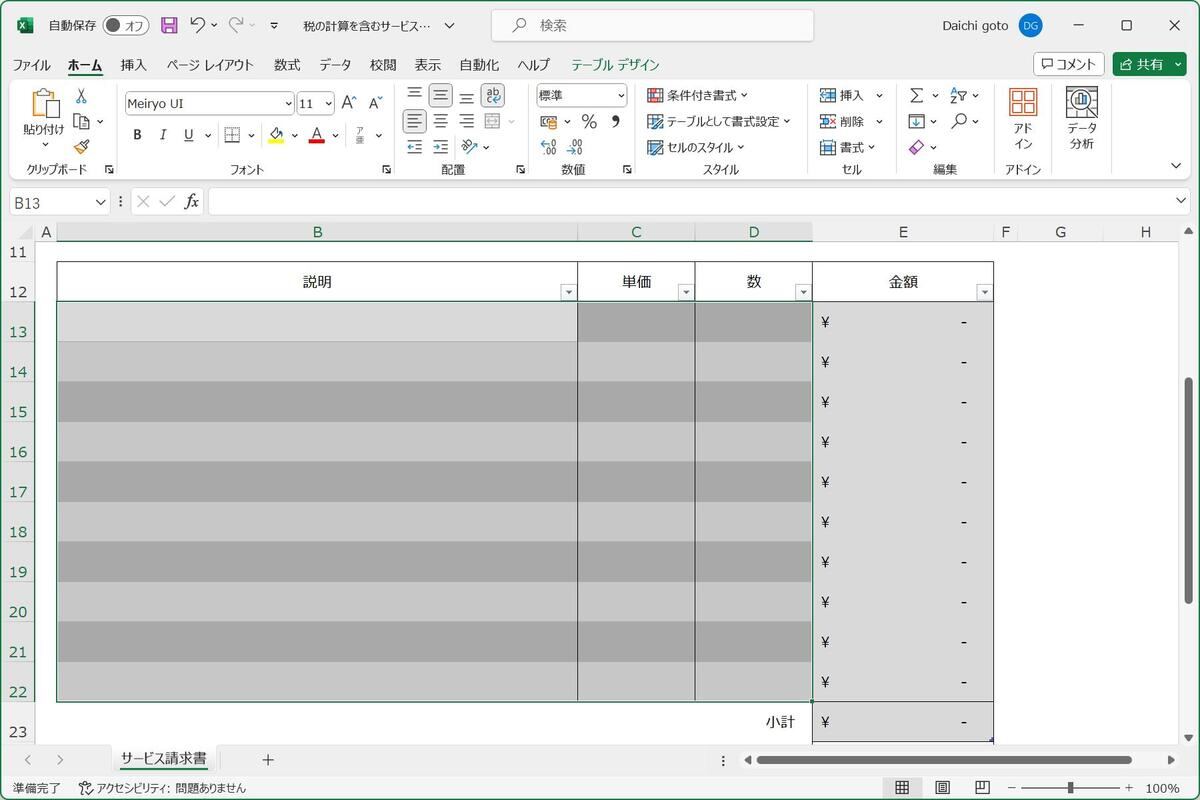
請求書テンプレートに差し込む請求金額データを抜き出す

請求データをどのように管理しているかは業務によるが、ここでは次のスクリーンショットのように、「会社名」「対象月」「項目名」「単価」「数」というデータで複数の企業に対する請求データを単一のMicrosoft Excelシートに保存して管理していることを想定する。
-
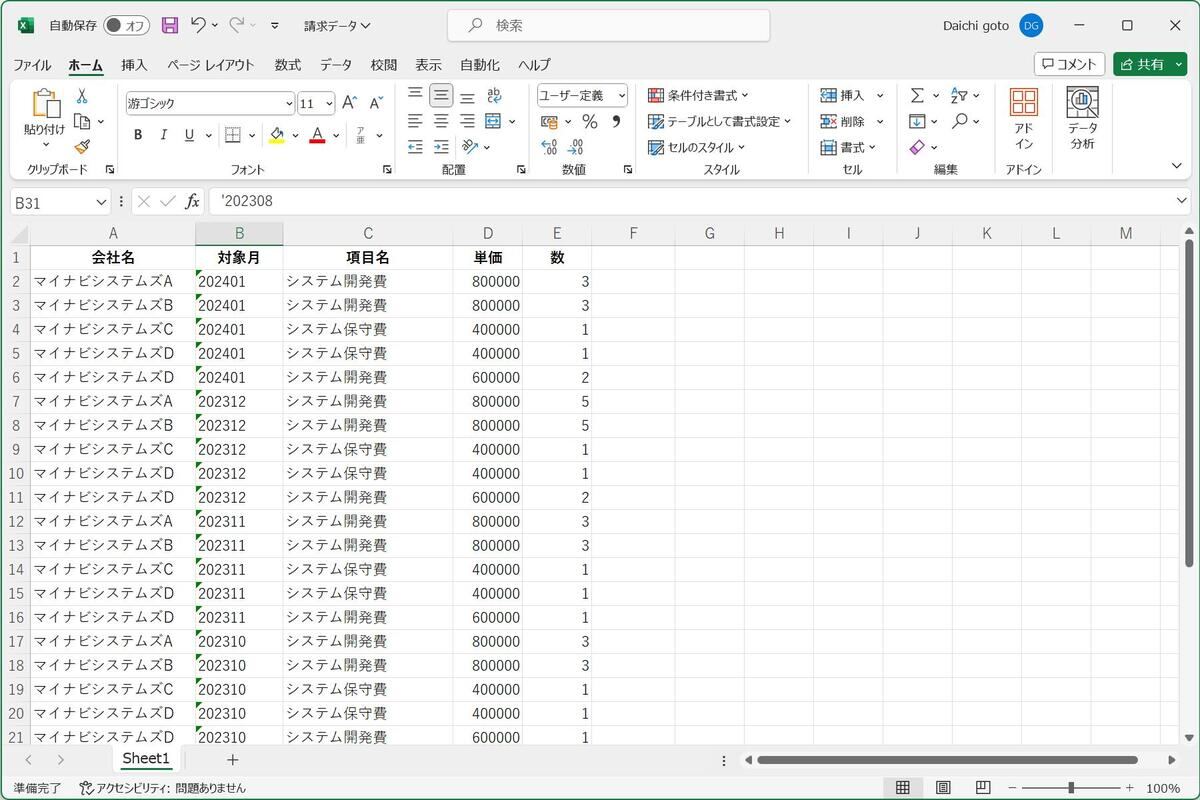
請求データをまとめているMicrosoft Excelファイル:請求データ.xlsx

上記のデータの場合、「会社名」と「対象月」がわかれば、作成する請求書の請求金額のデータが取り出せることになる。ここではPandasを使ってデータを取り出す方法を取り上げる。
一つ注意しておきたいのは、上記のデータは対象月のデータの最初に「'」を追加して明示的に文字列としてデータを保存している点だ。この値はそのまま扱うと数値として判断されてしまうため、明示的に文字列として保存されるようにしている。


Pandasを使ってデータを絞り込む実装
早速、以下に成果物を示す。前回に作成したスクリプトを書き換えて、次のようにすれば「会社名」と「対象月」でほしい請求金額データを得られる。
import pandas
#=========================================================================
# 初期値を設定
#=========================================================================
billing_data_xlsx_file_path = '請求データ.xlsx'
billing_company_name = 'マイナビシステムズD'
billing_month = '202401'
#=========================================================================
# 請求データファイルの読み込み
#=========================================================================
dataframe = pandas.read_excel(billing_data_xlsx_file_path, dtype={'対象月': str})
#=========================================================================
# 指定された会社の指定された月の請求データを取得
#=========================================================================
billing_data = dataframe[
(dataframe[dataframe.columns[0]] == billing_company_name) &
(dataframe[dataframe.columns[1]] == billing_month)
]
#=========================================================================
# 請求データを出力
#=========================================================================
print(f"{billing_company_name} {billing_month}分請求内容")
for index, row in billing_data.iterrows():
print(f"{index}: {row['項目名']} - {row['単価']} x {row['数']}"
まず、次のようにスクリプトを書き換えて請求書データをデータフレームとして読み込む。
「請求データ.xlsx」をデータフレームに読み込む
#=========================================================================
# 請求データファイルの読み込み
#=========================================================================
dataframe = pandas.read_excel(billing_data_xlsx_file_path, dtype={'対象月': str})
注目したいのはread_excel()でファイルを読み込む際に「dtype={'対象月': str}」と指定して、2列目のデータを文字列として取得している点だ。そのまま読み込むと整数として処理されてしまうので、明示的に文字列として読み込むように指定している。
Microsoft Excelのデータを読み込む際にはこのようにデータの型を指定しないと想定している通りに機能しないことがある点に注意しよう。
そして次の処理で「会社名」と「対象月」でデータの絞り込みを行っている。得られる結果は同じくデータフレームだ。
「会社名」と「対象月」でデータの絞り込み
#=========================================================================
# 指定された会社の指定された月の請求データを取得
#=========================================================================
billing_data = dataframe[
(dataframe[dataframe.columns[0]] == billing_company_name) &
(dataframe[dataframe.columns[1]] == billing_month)
]
これで目的とするデータが得られることになる。次に編集中の様子と実行結果を示す。
-

read_billing_data_1.py編集中

-
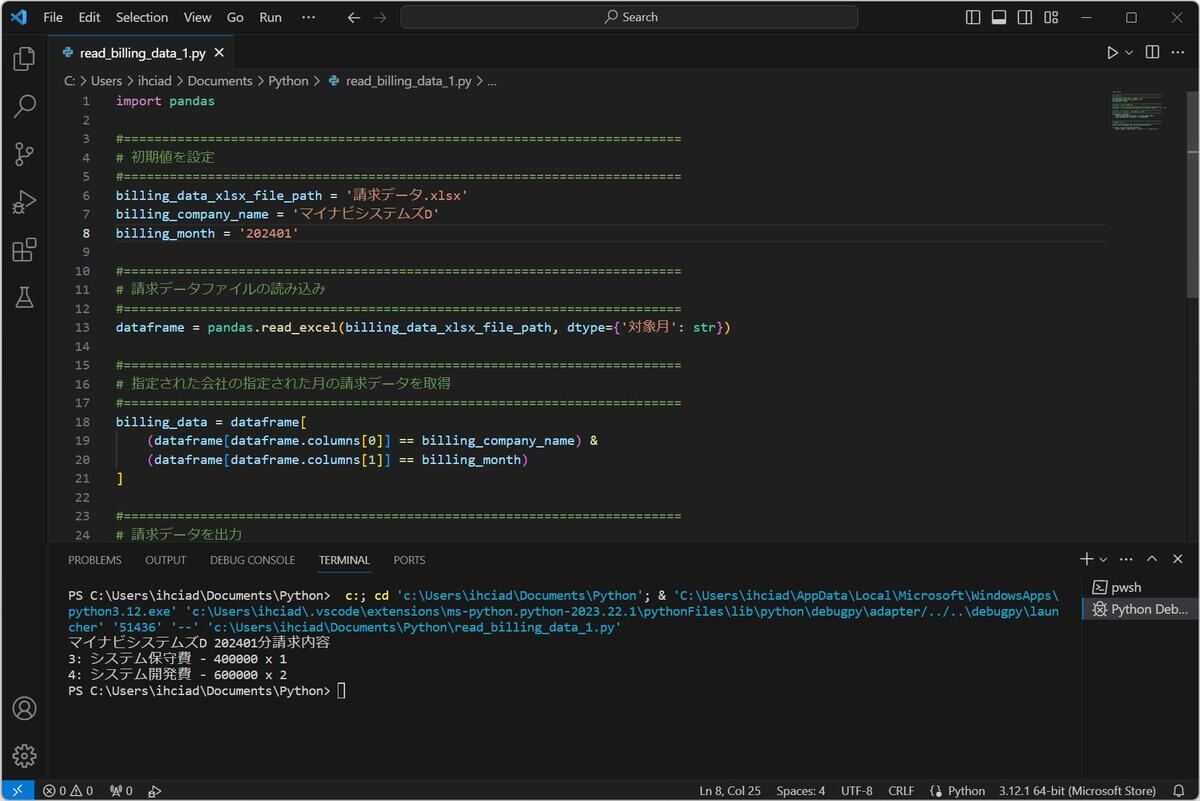
実行結果

「read_billing_data_1.py」では会社名として「マイナビシステムズD」、対象月として「202401」を固定で指定している。そして指定したデータが得られていることがわかる。