データブリックス・ジャパンは9月14日、都内で「Data + AI World Tour Tokyo」を開催した。本稿では、同社 代表取締役社長である笹俊文氏の基調講演とソフトバンクの導入事例を紹介する。
これからの時代の勝者はData Foward企業
冒頭に、笹氏は昨年末から驚異的なスピードでユーザーを獲得したOpenAIの「ChatGPT」を引き合いに出し、以下のような見解を示した。
「本格的なAIの時代に突入した。第四次産業革命とも位置付けられており、AIだけでなく、データと一対で技術革命を起こすと想定されている。データとAIをどのように利用しながら革命を起こしていくかということが重要。データとAIをフル活用するポテンシャルは無限大であり、取引などの自社データ、需要予測といった予測型AI、LLM(大規模言語モデル)をはじめとした生成型AIがあり、自社データとAIを組み合わせて使う時代になりつつある」(笹氏)
-

データブリックス・ジャパン 代表取締役社長の笹俊文氏

ただ、サードパーティ製のLLMを活用する際には、知的財産や著作権、ハルシネーション(幻覚)、社内の専門用語、個人情報などを考慮する必要があるという。そのため、同氏は「これからの時代の勝者は、自社独自のデータ+AI基盤を構築・運用するData Forward企業だ。データブリックスではData Foward企業になってもらうべく、プラットフォームでデータとAIを実装していく世界を作っていきたいと考えている」と力を込めてた。
同氏が言及したData Foward企業とは、これまでBI(ビジネスインテリジェンス)が担っていたデータ加工やレポート、非定型クエリ、データ探索などに加え、そこから何が起きそうか(予測モデル)、何を対処すれば良いか(処方的アナリティクス)、最適な意思決定(意思決定の自動化)などをAIを用いて将来予測を実現する企業を指している。
“スマホライク”な次世代データ基盤「レイクハウスプラットフォーム」
笹氏は「ここまで行き着くには簡単なことではない。これまではBIにより、構造化データを用いれば過去のデータは把握できたが、将来の予測を試みる際は外部データの取り込みや画像・映像などが必要になる」との認識だ。
同氏によると、自社における過去・未来のデータ、外部データなどを取り込む場合、データレイクやDWH(データウェアハウス)、BI、ガバナンスに加え、高度な予測を行うデータサイエンス、ML(機械学習)が必要となり、さまざまなプラットフォームを組み合わせなければならないため、高価かつ複雑な環境を維持しなければならないという。
そのようなことから、同社では「データとAIの民主化」を推進しており、データ統合とデータ分析、AIの活用を可能とするSaaS(Software as a Service)型統合データ分析基盤として「レイクハウスプラットフォーム」を提供している。
-

Databricksでは「データとAIの民主化」を推進している

レイクハウスプラットフォームは“スマホライク”な次世代データ基盤と定義しており、BI、リアルタイムデータ処理、データサイエンス&機械学習、DWH、データ編集・加工を単一のプラットフォーム上で、一元化されたガバナンスを実現するという。つまり、構造化データのみならず、非構造化データとAIを含めた一元的なガバナンスモデルを提供するというわけだ。
具体的には、DWHとデータレイクの両機能をカバーするアーキテクチャとなり、クラウド上でApache Sparkでデータにアクセスし、Amazon S3、Azure Data Lake Storage(ADLS)、HDFS(Hadoop Distributed File System)など、既存のデータレイクファイルストレージ上に設置されるオープンソースストレージレイヤ「Delta Lake」、ML(機械学習)のライフサイクルを管理する「MLflow」、DWHである「Databricks SQL」などのサービスで構成している。
同氏は「マルチクラウド、オープンアーキテクチャであるレイクハウスプラットフォームを利用する際はデータをコピーする必要がなく、マスターデータのみで対応できる。例えば、AWS S3と契約していた場合、S3上にデータブリックスがデータを展開するため、お客さまのストレージ領域で多種多様なデータを一元化が可能だ。そのうえで、どのデータが誰にどのように使われるのかというガバナンス制御を行い、BIやデータエンジニアリング、データストリーミング、データサイエンス&機械学習を実現する」と説明した。
-
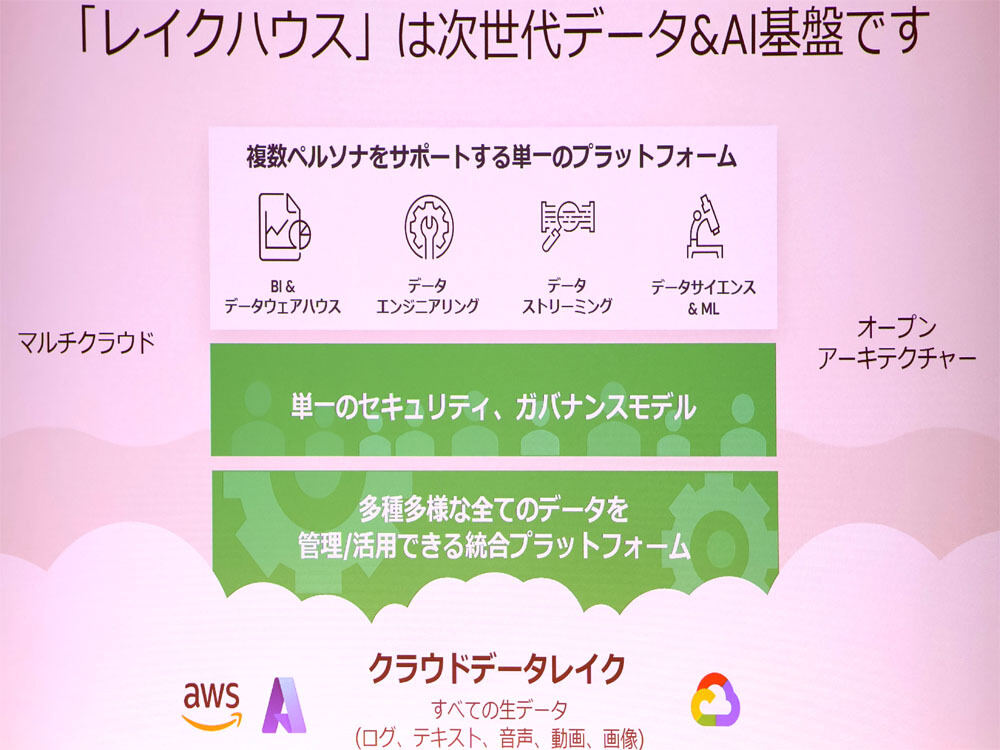
レイクハウスプラットフォームの概要



ソフトバンクの事例
現在、同社ではグローバルにおいて1万社以上の顧客を抱えており、ユースケースとしては金融サービスにおける不正検知や店舗需要予測、レコメンドエンジン/LTV(顧客生涯価値)、ゲノム解析/論文検索、ESG(環境・社会・ガバナンス)スコアリング、IoT故障検知/品質管理などがある。
国内企業においては、ソフトバンクやCCCMKホールディングス、AGC、コニカミノルタ、カルビー、マネーフォワードなどが導入しており、笹氏に続いて登壇したソフトバンク IT統括 IT&アーキテクト本部データ戦略部 部長の安芸洋一氏がDatabricks導入の経緯や現在の状況について解説した。
-

ソフトバンク IT統括 IT&アーキテクト本部データ戦略部 部長の安芸洋一氏

まず、同氏は「通信キャリアとして他社と比較して、ネットワークや機種、料金などはコモでティティ化が進んでおり、差別化ができない状況となっている。そのため、データを紐解き、ユーザーを知り、ニーズを理解することで接点を持つべきだと考えている。重要なコンセプトとしてはデータで何ができるかではなく、目的から入ることであり、データを紐解くことで、どのようなデータを準備し、分析結果を得てアクションにつなげるかというPDCAをいかに回せるかということがポイントになる。そして、データガバナンスを遵守し、安全に利用することが望ましい」と述べた。
確かに、安芸氏が話すようなことは理想的かつ現実的ではあるものの課題もあるという。例えば、業務視点ではExcelやAccessを利用したローカル作業では負荷が高いほか、大量のデータがローカルPCに存在するとなると情報漏えいのリスクもある。
一方、IT視点では約2000人の社内ユーザーがデータ検索するため、高頻度でのRPA(Robotic Process Automation)利用、同一クエリの実行、エラー放置といったシステム性能に問題を抱える。また、複数のデータ基盤を開発チームと運用チームが利用するため重複し、開発・運用の難易度が高くなるという。
Databricksにより高度化されたソフトバンクのデータ基盤
こうした経緯から、同社では2年前に方針としてデータについては「すべてのデータを一元管理」、基盤に関しては「分析&マーケティング業務を一気通貫」、ツールは「多様なツール/ソリューションと連携」と定めた。
-

ソフトバンクが定めた方針

同社の方針に沿ったデータ基盤は、一丁目一番地をDatabricksとし、DWHにはCRM、財務、人事など目的別に分析/レポート(可視化/経営判断)のデータマートを用意し、CDP(Customer Data Platform)に顧客の行動データを収集・統合・分析するデータ基盤としてマーケティング/顧客応対(アクション実践)を行う環境を構築した。
-
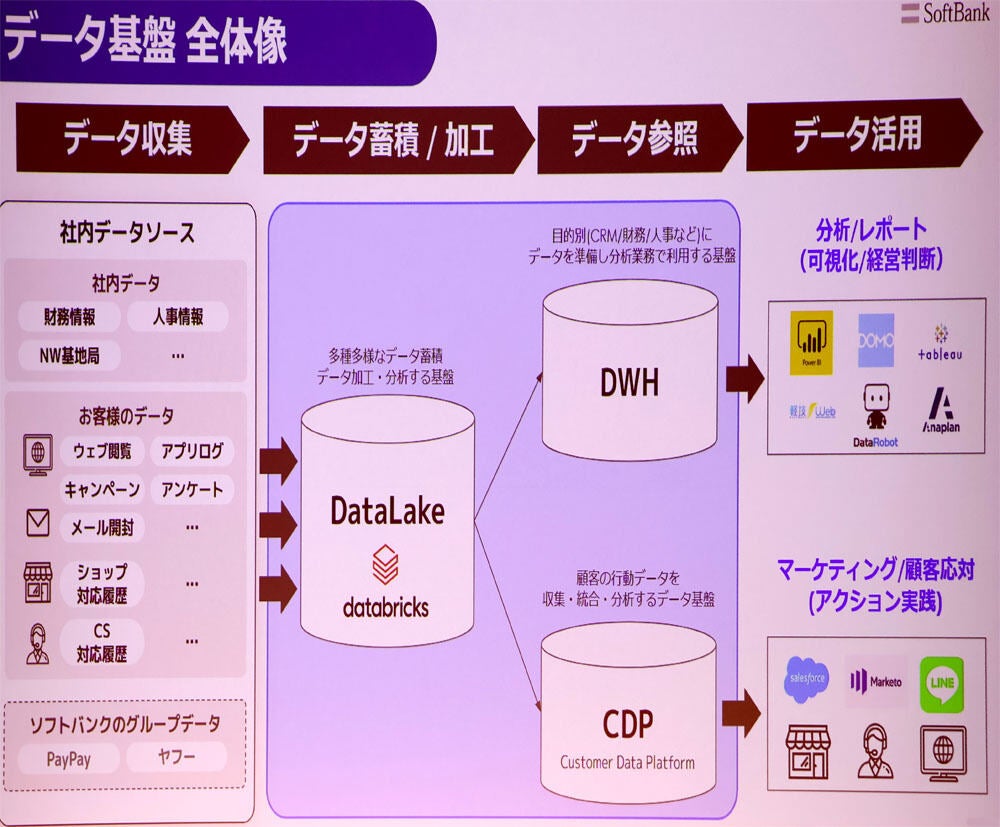
データ基盤の全体像

安芸氏は「大規模な環境を構築し、アプリケーション、データ、業務を移行したため、大変なプロジェクトだったが、これからはどんどんビジネスで活用していくというフェーズになっている」と振り返った。
足掛け2年でDatabricksをベースに構築したソフトバンクのデータ基盤は、データエンジニア向け、データサイエンティスト向け、データスチュワード(データを管理する人)向けの3つの役割を担っている。
データエンジニア向けにはETL(収集、加工、送出)処理などのデータ処理基盤として、データサイエンティスト向けにはモデル柵瀬処理といったAI/分析基盤として、データスチュワード向けにはデータプレパレーション(分析前のデータを分析できる形に変換する手法)処理として、それぞれ活用している。
-
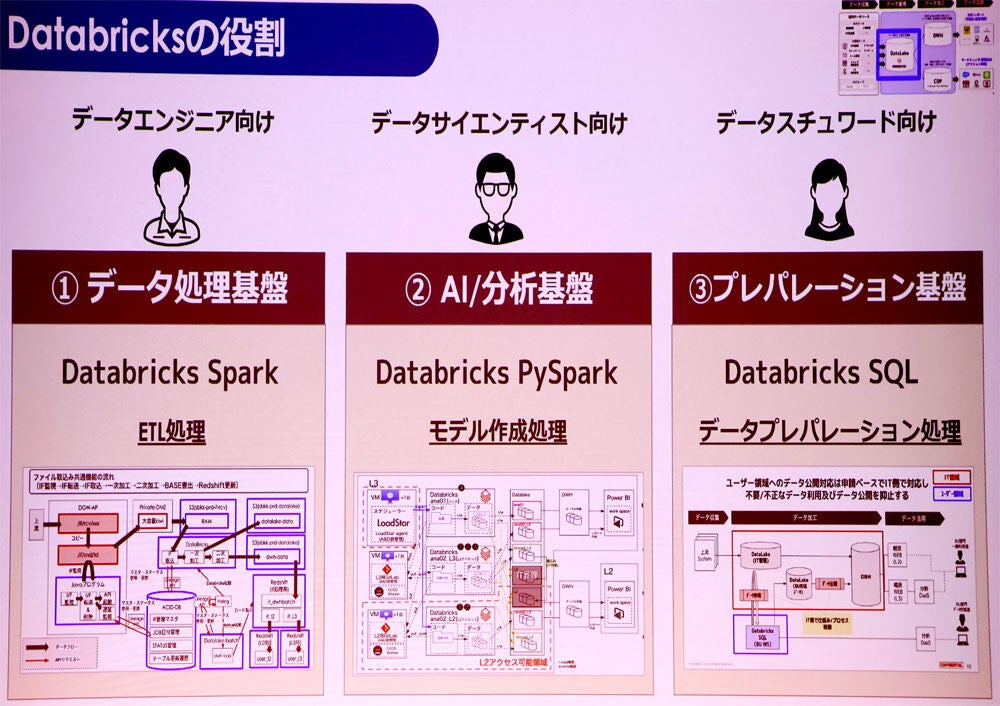
ソフトバンクのデータ基盤におけるDatabricksの役割

データスチュワード向けのデータプレパレーション処理については、ITが準備したデータの不足分を補うべく、社内のユーザーからローカル環境ではなく、マシンパワーを使い、ビジネスをよりクイックに行いたいというニーズがあったため構築したという。
そして、最後に安芸氏は「今後、トラフィックは確実に増加していくため簡単にスケールアウト・アップというよりは、最適なエンジンを適用し処理性能を向上していく。また、これまでさまざまなジョブ、ワークフローに伴い環境変更を行ってきたが、帯域を交通整理して運用効率、品質向上への取り組みも必要となり、引き続きデータ基盤の強化に取り組む。さらに、将来的には現状ではデータレイク、DWHが物理的、論理的にも存在しているため、これを一本化する。障害ポイントの低減やデータの提供時間を削減すれば、環境も縮小するためコスト削減につなげる」と展望を語っていた。