先日、シンガポールで「Possible」を開催した米Teradata。今回は同社のCPO(最高製品責任者)であるHillary Ashton(ヒラリー・アシュトン)氏の基調講演を紹介するとともに、基調講演後に行ったインタビューの内容をお伝えする。
「Teradata VantageCloud」のアップデート内容
まず、基調講演においてアシュトン氏は「Teradata VantageCloud」を中心としたサービスに関するアップデートを説明した。
同氏はTeradata VantageCloudについて「より早く・スマートにスケールアップ・ダウンでき、高度なアナリティクスを実現できます。近年では、アーキテクチャをクラウドに適用させており、フレキシブルでモダンなアーキテクチャです。さまざまなストレージオプションに対応し、データから得られる成果をデータがどこにあろうが出せるようにしたいと常に考えています。この新しいアーキテクチャはゲームチェンジャーです」と述べた。
-

米Teradata CPO(最高製品責任者)のHillary Ashton(ヒラリー・アシュトン)氏

データレイク、DWH(データウェアハウス)に加え、レイクハウスとマルチクラウドに対応したデータ&アナリティクスプラットフォームとして、VantageCloudを位置づけている。


アシュトン氏は「データへのアクセスを簡単にすることに注力し、どのような環境だろうと活用できるようにしています。また、大規模なデータベースのワークロードマネジメントを可能とする並列処理の技術に加え、責任あるガバナンスで運用を可能としており、AI/ML(機械学習)にも対応しています」と強調した。
-
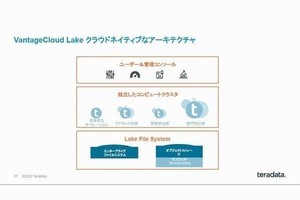
「Teradata VantageCloud」の概要

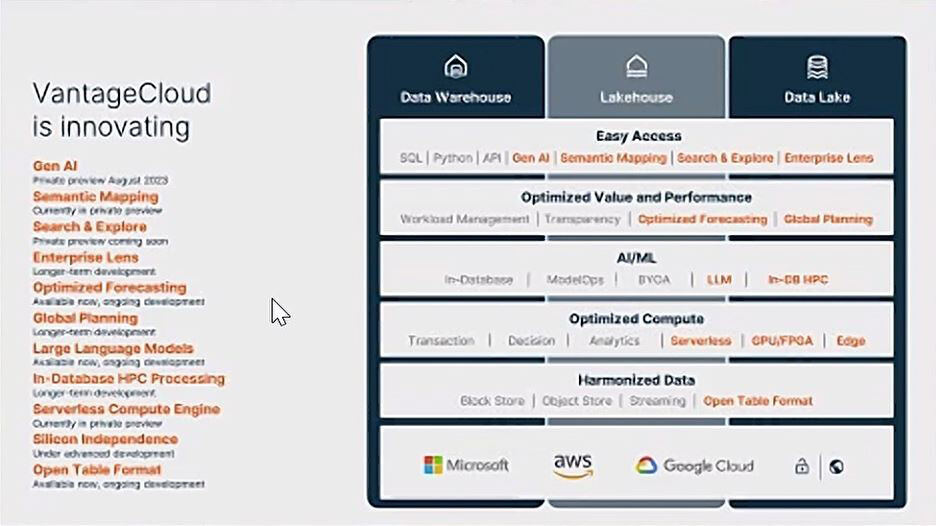
基調講演ではVantageCloudのアップデートが紹介された。VantageCloudは、OpenAIのGPTを活用したチャットボットや、セマンティックマッピングとしてデータは保持しているものの、どのようなデータか把握できていないものを発見することができ、いずれもプライベートプレビュー版で提供している。
-

セマンティックマッピングの概要

今年8月に買収したデータカタログソリューションを提供するStemma TechnologiesのサービスをAIで強化し、開発者向けのデータ検索・探索に加え、データリネージュなどを可能としている。
-
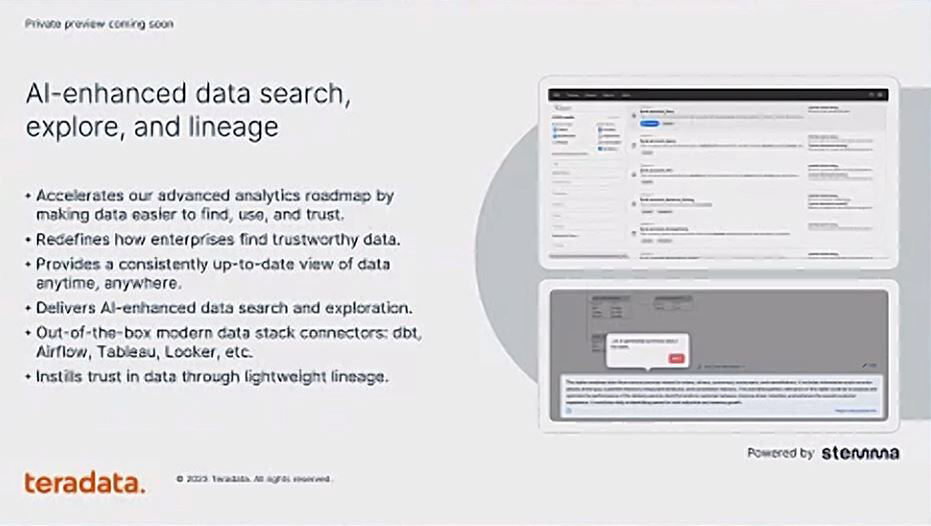
StemmaのサービスをAIで強化する

さらには、LLM(大規模言語モデル)を活用した予測も可能となり、ユーザーのカスタマージャーニーに向けて、イベントシーケンス最適化のための生成AIも活用できるという。
-
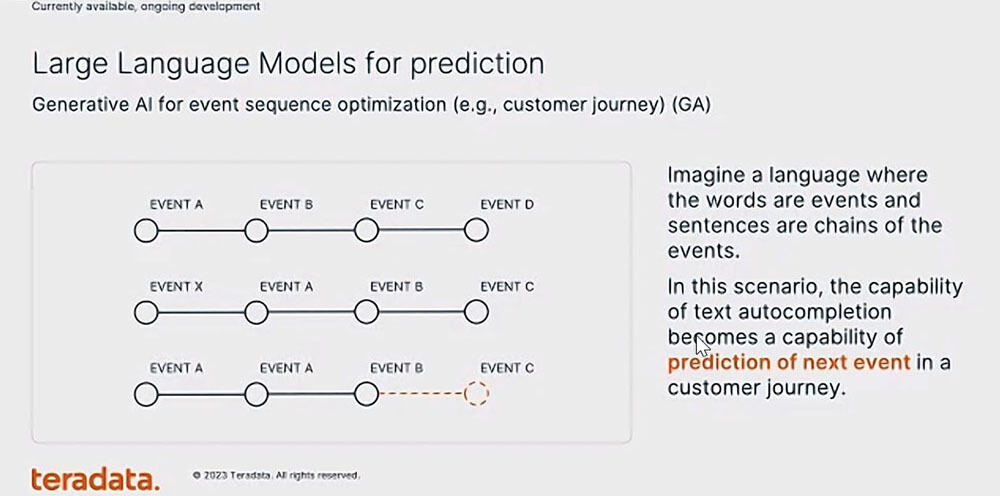
LLM(大規模言語モデル)を活用した予測も可能

また、プレイベートプレビュー版として、VantageCloudにセルフサービスのサーバレスのコンピュートエンジンを提供。同氏は「数分でインストールとプロビジョニングが完了し、データベースのようなデータ管理を必要とせず、データを分析・解析するためだけのエンジンです。アドホックなワークロードやアナリティクスのために、簡単にスピンアップ・ダウンが可能で、低コストのオブジェクト・ストレージ用に設計しており、AWSとAzureのマーケットプレイスで利用が可能です」と説明していた。
-
サーバレスのコンピュートエンジンを提供するという
アシュトン氏へのインタビュー
基調講演後には同氏へのインタビューを行い、提供中の注目製品や製品のロードマップについて話を聞いた。
--マクミランCEOも基調講演の中で言及していた、昨年に提供開始したクラウドアナリティクス機能「ClearScape Analytics」について、どのようなサービスなのか改めて教えてください。
アシュトン氏(以下、敬称略):ClearScape Analyticsは、VantageCloudプラットフォームの一部です。その特徴の1つとしてインデータ分析を行う点です。これまでは、DWHからデータをコピーして別の環境で分析を行う必要がありました。
しかし、ClearScape AnalyticsはDWH、データレイク、レイクハウスをはじめ、さまざまなデータフォーマットに対応し、最適化されたパフォーマンスで大容量データに対する分析を行います。
また、ModelOpsであり、何十万もの分析モデルを管理することで最新のデータを用いた精度の高いモデルの活用を支援しています。そのほか、パトーナーのソリューションとも連携を可能としています。
クラウドサービスプロバイダとの入スケールなモデルのトレーニングもできますし、Azure ML、Google CloudのVertex AI、Amazon SageMakerなどをネイティブでモデルトレーニングできます。
--生成AIの考え方について教えてください。
アシュトン:生成AIはブレイクスルー的なものを感じています。テクノロジーとしては、まだ氷山の一角ですが、インターネットと同規模の影響を与え、世の中をガラッと変えるものだと思います。
われわれでは「社内での活用」「サービス自体への取り込み」「サービスを利用する顧客の生産性向上」という3つの観点で考えていますが、IP(知的財産)の保護をはじめセキュアな形で実施することが前提です。
生成AIを活用したサービスを提供するときはセキュリティも伴わなければならなものの、専門家のみならずビジネスユーザーも利用できることから、“新しいアナリティクス”が形成されるかもしれません。
--直近で取り組みたいと考えている顧客のペインポイント(悩みの種)について教えてください。
アシュトン:お客さまは、データベースに対する意思決定の民主化を求めています。皆がデータベースへ自由にアクセスでき、最良の意思決定を行い、成果につなげることです。
どのようなビジネスであっても、お客さまの体験とともに製品の価値を向上させることが重要です。そのうえで新しいアナリティクスの成果につなげます。
これまでアナリティクスは専門的でしたが、生成AIの登場で新しいアナリティクスを誰でも作り、イノベーションを加速させることができます。そのため、高度なアナリティクスを活用して競争優位性を獲得してもらいたいと考えています。
--Teradataの技術的な強みは並列処理アーキテクチャにあると思います。ただ一方で、分散処理を強みとするベンダーも存在します。改めて、御社の技術的な強みについて現在の市場環境をふまえて教えてください。
アシュトン:われわれの考え方としては、最高のパフォーマンスを一定のリソースやシステムから引き出すことを重要視しています。
常に、最高の価値を引き出したいと考えており、それにはリソースを上手に管理して、最適化することで弾力性を備えていることが重要であり、実現できます。
また、われわれのプラットフォームはお客さまに対して、迅速に付加価値を提供できていると感じています。オープンでコネクティビティを有しており、インテグレーションをクラウドネイティブにさまざまな機能と組み合わせ、拡張のエコシステムを形成しています。
--今後の製品ポートフォリオ戦略、ロードマップを教えてください。
アシュトン:お客さまが一気に競合他社を追い抜けるようにしていきたいと考えていますが、生成AIは非常に重要です。
クラウドには多くのデータが存在しており、お客さまは必ずしもデータから有益性を引き出せているわけではないため、どのようなデータで既知のデータとの関連性などを表すセマンティックマッピングは、組織に眠るデータを迅速かつ利便性のあるものにすることが可能です。
また、サーバレスのコンピュートエンジンについては、ステートレスコンピューティングを実現します。これはデータベースなしでもデータベースの機能を有し、大規模なクラウドインフラストラクチャは必要ありません。
例えば、GitHubとのインテグレーションではステートレスエンジンのため、セルフサービス、セルフプロビジョニングができるようになっています。これを生成AIと組み合わせると、学生でも高度なアナリティクスをすぐに利用することが可能になると思います。