


日本IBMは10月13日・14日、日本科学未来館で最新テクノロジーやその応用について紹介するイベント「Science for the Future」を開催した。イベントでは、直近の研究成果や現在取り組んでいる研究開発の内容が展示されており、メディア向けに日本IBM 執行役員 IBM東京基礎研究所 所長の福田剛志氏によるラウンドテーブルが開かれた。
50年以上の歴史を持つ日本IBMの研究開発
IBMでは、事業部とは独立した研究機関としてIBM Researchがあり、グローバルで3000人以上がAIやブロックチェーン、量子コンピューティング、セキュリティ、クラウドコンピューティングをはじめとした研究開発に取り組んでいる。
福田氏は、IBM Researchについて「コンピュータサイエンスだけではなく、さまざまな領域の研究者が携わり、双方向的に取り組むことで新しいイノベーションが生まれる。つまり、専門分野ダイバーシティをもとにイノベーションを起こそうとしている」と説明した。
-

日本IBM 執行役員 IBM東京基礎研究所 所長の福田剛志氏



日本では科学に関する研究開発部門は東京基礎研究所が担っており、その前進となるジャパン・サイエンス・インスティチュートが設立されたのは40年前の1982年。1971年に設立した同社の製品開発研究所も含めると50年が経過している。
現在、拠点は同社の本社が所在する箱崎事業所と新川崎に構えており、量子コンピュータやAI、ハイブリッドクラウドのセキュリティモダナイゼーションなどに取り組んでいる。
2つの新たな潮流とは
同氏は科学界の新しい潮流として「科学的発見の加速(Accelerated Discovery)」と「基盤モデル(Foundation Model)」の2つを挙げる。
科学的発見の加速(Accelerated Discovery)
科学的発見の加速について、まず福田氏は科学の難しさについて説明した。同氏によると、年間250万件の科学論文が出版され1、665年以来の累計では5000万件の論文が存在するほか、スイスの素粒子研究所「CERN」で生成される大型ハドロン衝突型加速器などが生み出すデータは1月あたり100PB(ペタバイト)にものぼるという。
また、医薬品となる、さまざまな病気に活性がある化合物候補数は10の63乗と地球上にあるすべての原子数の10億倍より多く、新薬や新材料を開発までに要する時間は10~20年、費用は数億~数千億円かかる。このように膨大な量と可能性に加え、調査・検証に時間、コストを要し、計算の限界もあると、同氏は指摘する。
そこで、同社は“科学的発見の加速”を材料分野に焦点を当てた「Accelerated Material Discovery(材料発見の加速)」の研究を進めている。
Accelerated Material Discoveryは、非構造化データから関連を見出す「ディープサーチ」、シミュレーションによる数値データを取得する「AI強化シミュレーション」、材料構造デザインにおける創造性を拡張する「生成モデル」、クラウド上で完結する実験プロセスの「ロボット自動実験」の4つのプロセスが互いに補完し、材料発見までのプロセスを加速させるというわけだ。
-
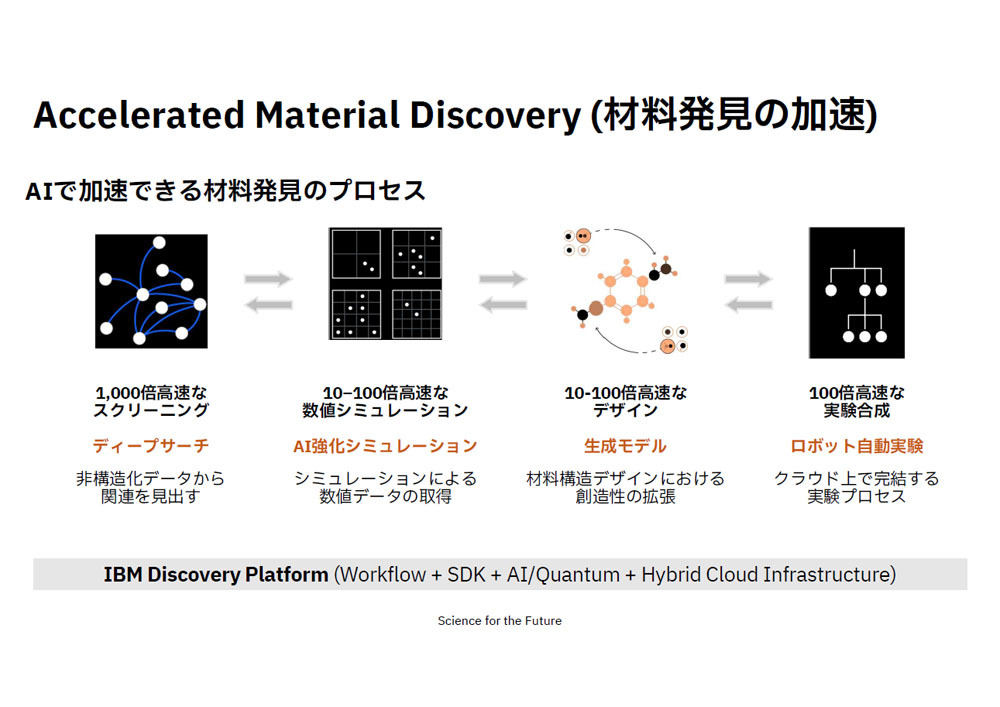
Accelerated Material Discoveryの概要

これら、4つのプロセスに共通した要素を持ち合わせたプラットフォームとして「IBM Discovery Platform」を構想している。
同プラットフォームは、パブリッククラウドやプライベートクラウド、量子コンピュータ、AIシステム、データストレジージといった「インフラストラクチャ(主にエコシステムの技術)」のうえに、複数のクラウドとオンプレミスシステムを制御する「コントロール層」を持つ。
コントロール層の上位レイヤはデータやカタログ・自署、イベント記録、サービス・ファブリック、IoT、管理サービスをはじめとした「コアサービス」、そして4つのプロセスの「アプリ&ライブラリ」において科学者やアプリ開発者が材料、医薬品の発見に利用する。すでに、コアサービスは今年6月、またインフラストラクチャは10月にそれぞれβ版を発表している。
-
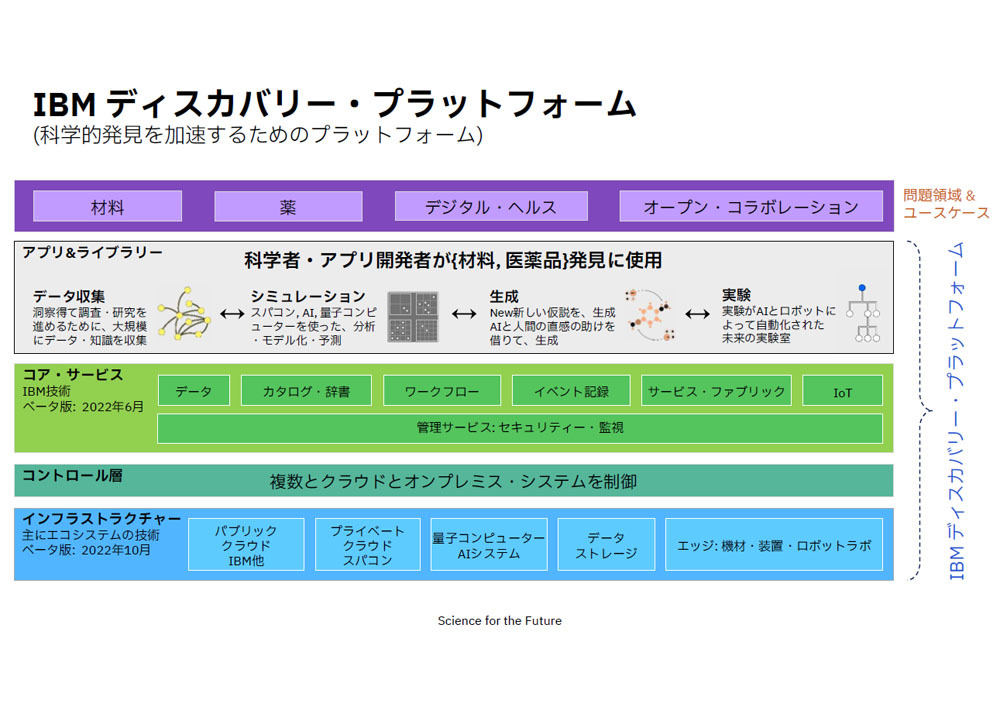
IBM Discovery Platformの概要

福田氏は「IBM Researchがグローバルで取り組み、日本では多くの材料メーカーが世界をリードしていることから、このリードをより大きくするとともに保ってもらいたいと考え、パートナーシップを構築している」と胸を張っていた。
基盤モデル(Foundation Model)
一方、基盤モデルはAIに関することだ。これまでAIは、1980年代は人手で作成したIF/THEルールの「エキスパートシステム」、2000年代半ばころからタスクごとに人手で作成した特徴表現の「機械学習」、2010年以降はタスクごとに学習されたニューラルネットワーク表現の「深層学習」という変遷をたどってきた。
そして、2018年以降に生成的・高適応性のニューラルネットワーク表現として基礎モデルが昨今では注目されている。
-
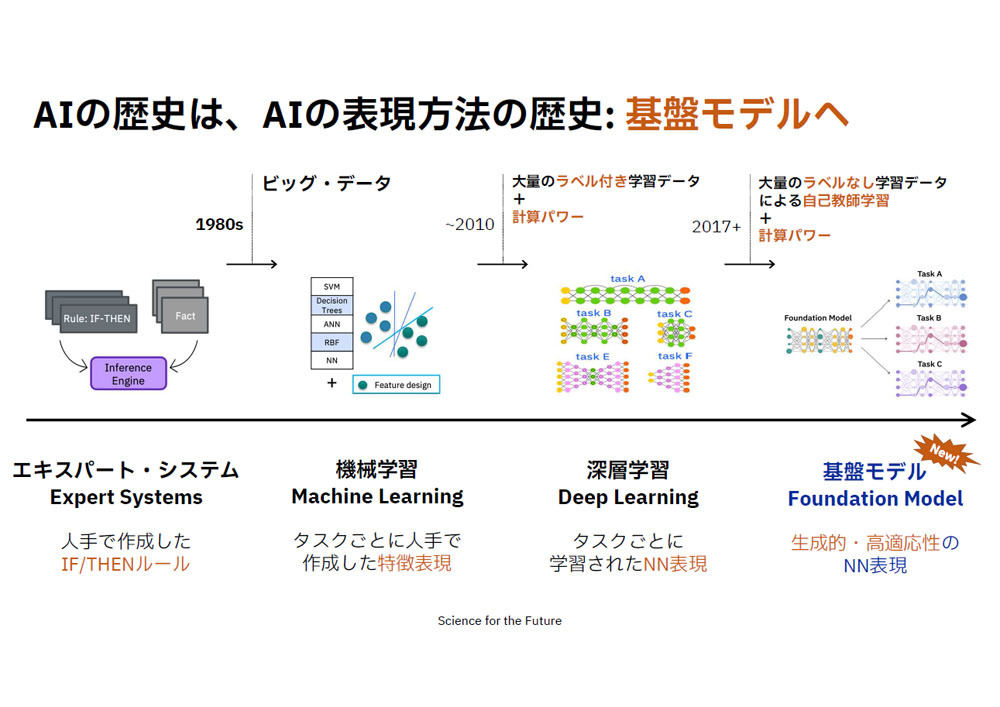
AIの歴史

特徴としては、大量の多様なラベルなしデータでの事前学習(Unsupervised learning)、自己教師学習(Self supervised learning)、比較的少量のラベル付きデータで下流タスク(自然言語の例では要約、文章生成、機械翻訳など)の学習を可能としている。
-
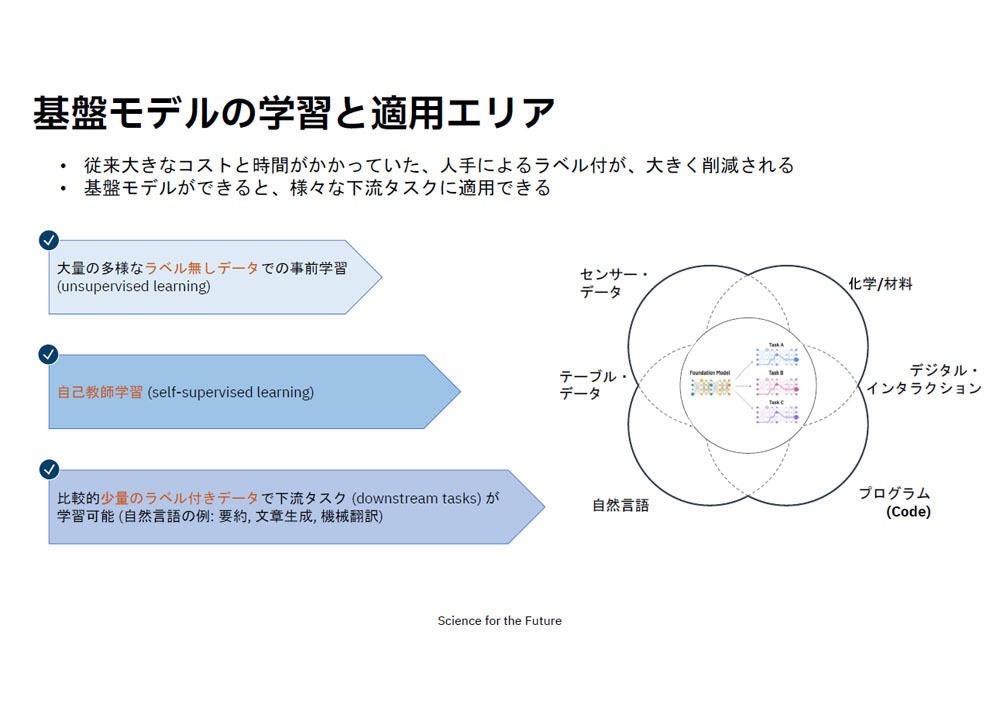
基盤モデルの学習と適用エリア

この基礎モデルを応用したものとして、同社では「Foundation Model for Material Discovery(材料発見のための基盤モデル)」の研究を東京を含めて、世界4カ所で取り組んでいる。普遍的な材料の表現により、分野やデータのモダリティに寄らない複数なタスクが可能な包括的なモデルだという。
-

Foundation Model for Material Discoveryの概要

福田氏は「今後、科学的発見の加速と基盤モデルは活用されていくだろう。将来の科学にテクノロジーを活用できるように、パートナーとともに取り組む」と力を込めていた。














