


MI250XをOAMボードに搭載してスパコン用の演算密度の高い計算ノードを作ることができる。
-
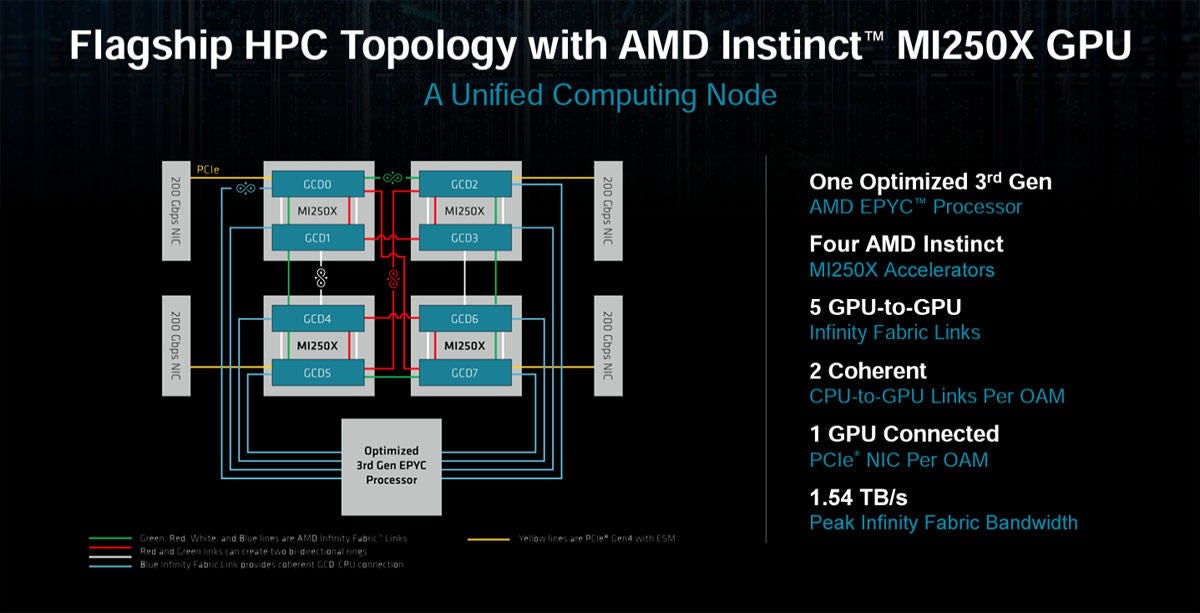
OAMモジュールに4個のMI250X GPUと1個のEPYCを接続すれば2ノードのHPC用のモジュールが作れる

HPE CRAYのEX235Aブレードは一枚のブレードに8個のMI250Xを搭載し、AMD EPYC CPUと合わせて、計算ブレードを2ノード分搭載できるようになっている。ただし、この構成ではGPUの発熱が大きいので、空冷での冷却は困難で水冷の冷却を行う必要がある。
-

1枚のOAMモジュールに2ノードを搭載するCRAYのEX235A。高密度であるので水冷する必要があるが、Frontierスパコンにも使用されている

もちろん、より大型のサーバも作られており、次の写真に載せたSupermicroのAS-4124GQサーバは8枚のI/Oスロットや10枚のストレージベイを持つ構成となっている。
-

4個のMI250Xに加えて8枚のPCIボード、10基のストレージベイを持つSuperMicroのAS-4124GQ-TNMIサーバは、I/Oやストレージをサーバに搭載できる

CRAYのEX235Aモジュールを使うFrontierスパコンはRmax性能が1.102.00PFflop/sで、2位の日本の富岳スパコンの442.01PFlopsを約2.5倍上回ってトップ性能のスパコンとなった。そして、Frontierは消費電力が21,100kWと29.899kWの富岳と比べて消費電力が2/3程度と少ない。
Frontierスパコンに次ぐTop500の2位は日本の富岳であるが、3位はFrontierと同じモジュールを使うフィンランドのLumiスパコンが獲得した。
-
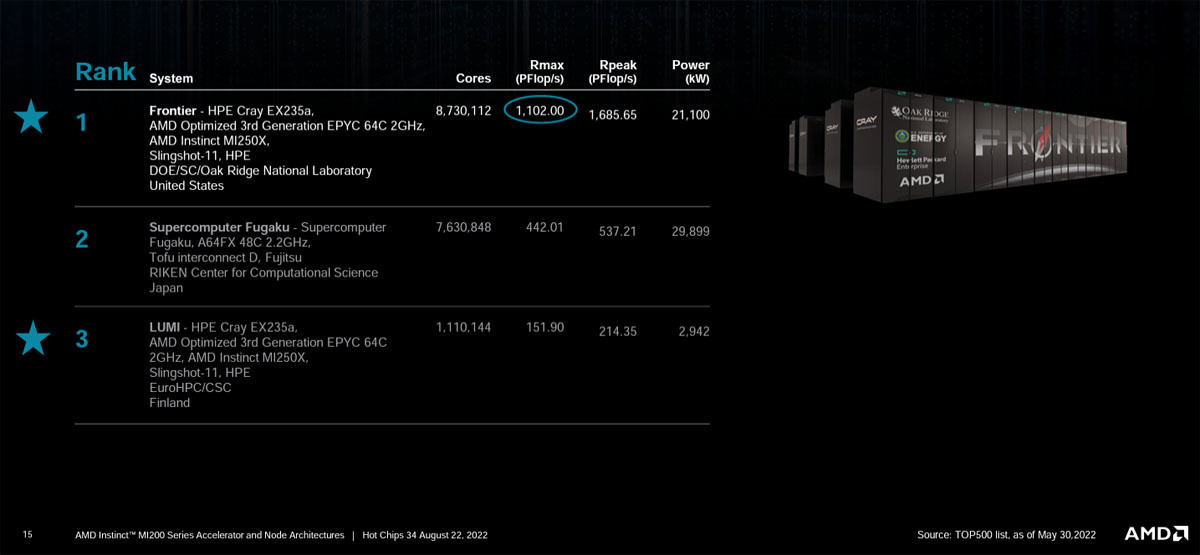
Top500の3位はフィンランドのLUMIスパコンで、Top500の1位と3位はAMDのMI250X GPUを使うCRAYのEX235Aスパコンとなった

次の図の右側の図に3つのグラフが描かれているが、CPUによる演算は広い範囲のアプリケーションの実行に適用できるが加速の程度は小さい。GPUアクセラレータはCPUに比べると加速できるアプリの種類は狭いが、加速の程度は大きい。そして、ドメインスペシフィックなアクセラレータは適用範囲は狭いが加速の程度は大きいと書かれている。
どのようなアクセラレータが良いかは、どのようなアプリを実行するかにもより、簡単には決められないが、Top500やGreen500で良い成績を上げているAMD/CRAYのアクセラレータが良いという主張であろうか?
-
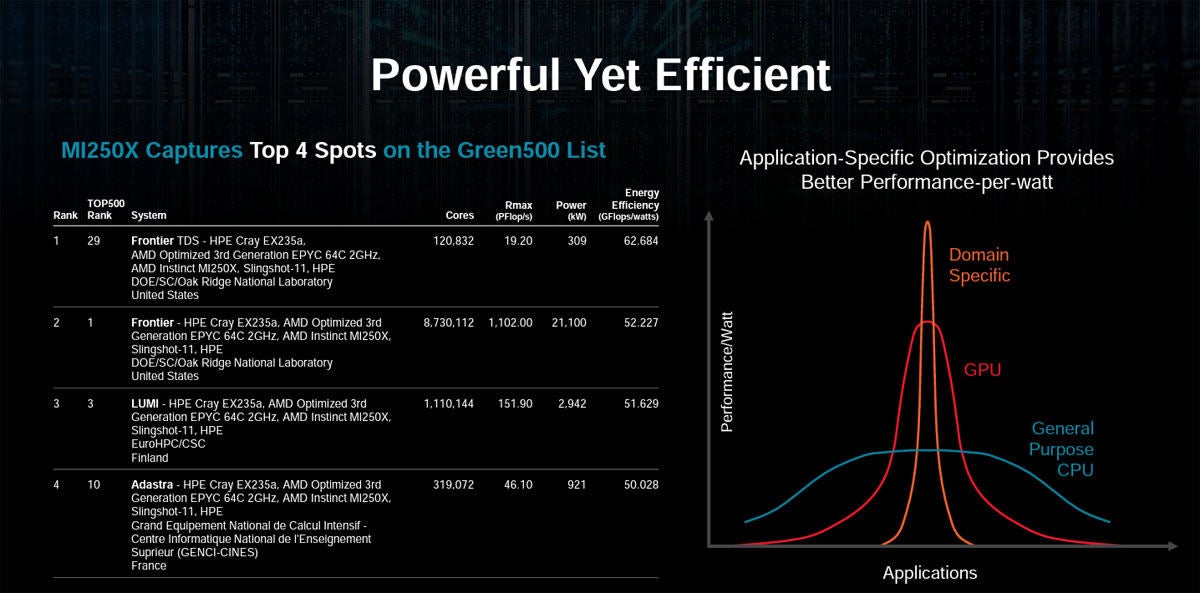
Green500の上位4システムはCRAY 235aを使うシステムが独占した

ここまではTop500やGreen500を性能指標として見てきたがマシンラーニングの場合は、指標の取り方が変わってくる。演算性能が重要であり、MI250Xを8個搭載する点は変わらないがネットワークを構成するためのNICやストレージが必要となる。
-

スパコンや大規模AI処理ではネットワークやストレージが欠かせない。ストレージ接続用のPCIeやネットワーク接続用のNICボードなどが用意されている

高い加速を実現するにはドメインスペシフィックな最適化が重要である。1個のGPUに128GBのメモリを持たせるにはHBM2eメモリが必要。そして、ユニファイドシェアードメモリの実現も使い勝手の点で重要である。
そのためにもAMDの第3世代のInfinity Architectureによるユニファイドシェアードメモリの提供が重要であるとしている。
-

高性能の実現にはドメインスペシフィックなアーキテクチャを取ることが重要である。そして演算性能を支えるメモリが重要であり、CRAY235AではHBM2eメモリを直結している。さらに大規模スパコンを作るネットワークが重要であり、AMDのInfinity Architectureを使っている









