日本ディープラーニング協会(以下、JDLA)はこのほど、東京都内で同協会が実施するG検定およびE資格の合格者が一堂に会する交流イベント「合格者の会 2022」を開催した。本稿では同イベントにおいて、JDLAの理事長である松尾豊教授が「ディープラーニングの進展と未来」と題して語った特別公演の様子をお届けしたい。
G(ジェネラリスト)検定では、ディープラーニングの基礎的な知識を有し、ビジネスにおいて適切な活用方針を決定してAI(Artificial Intelligence:人工知能)を活用できる知識を持つかを検定する。一方のE(エンジニア)資格は、ディープラーニングの理論を理解して適切な手法で実装するための能力や知識を持つかを認定するものだ。


新しい資本主義において「AI」は重要な柱になる
松尾氏は内閣が立ち上げた「新しい資本主義実現会議」の有識者にも選定されており、先般実施された同会議にて岸田首相らを前に行ったプレゼンテーションのスライドなどを交えながら講演を進めた。
-

JDLA 理事長 松尾豊氏

岸田内閣は、「成長と分配の好循環」と「コロナ後の新しい社会の開拓」をコンセプトとした「新しい資本主義」を標榜している。その実現にあたっては、「成長と分配」「人への投資」「スタートアップ」が重要だとして、これらを軸に据えている。また、科学技術については、AIと量子分野を主戦略としている。
AIの発展と聞くと、米DeepMindのAlphaGoが人間のプロ囲碁棋士を破った2016年のニュースを思い浮かべる方も多いのではないだろうか。本件は扇情的な出来事として世界を賑わせた。
そのほか、自然言語処理を行うGPT-3などのFoundation Modelsも進展が目覚ましい。Foundation Modelsとは、大規模データで学習した幅広いタスクに汎用的に適用できるモデルを指す。質疑応答のみならず、知識による補完や、文章の生成なども非常に高い水準で実行できる。
-

AIの発展が急速に進んでいる

さらに近年では、自動でプログラミング可能なAIであるAlphaCodeも発表された。このAIは414憶の膨大なパラメータを保持しており、競技プログラミングの平均的なコーダーと同程度のアルゴリズムを生成可能だ。
このように近年急速に発展するAI技術ではあるが、松尾氏は「現在のAI技術やディープラーニングには一定の限界があるはず」と指摘した。例えば、自動運転技術は地図がない状態で自由に走行はできないし、対話AIも人間の日常会話を完全には再現できていない。現在のAIはタスクを内包したタスクの学習が苦手なのだそうだ。
一方で、「今後こうした課題が解決されると、さらに大きな範囲でイノベーションが起こる可能性があり、さらに何段階かの飛躍もあるだろう。AIは今後の戦略の柱になり得る重要な領域だ」とも同氏は述べていた。
-

現状は、AIにも限界はあるようだ

特に欧米諸国でAI技術の進歩が先行している中で、日本のAIは国の政策として勝ち目はあるのだろうか。松尾氏が示すポイントは「実践で逆転」「人材育成とスタートアップで逆転」「融合領域で逆転」の3つだ。
研究から逆転するのではなく、実践段階の試行錯誤の回数を増やすことが日本のAIの発展につながるのだという。そのためにも、多くのビジネスパーソンがAIを使いこなせる必要がある。人材育成については、特に実践型の人材育成が重要とのこと。
融合領域の例としては、元々日本が強みとしている物理化学などとAIの融合を松尾氏は勧めていた。ロボットや脳科学も相性が良いそう。研究は20代の若手研究者を重点的に支援すべきとしている。
新しい資本主義実現会議でこうした松尾氏のプレゼンテーションを聞いた岸田総理は「AIについてはディープラーニングを重要分野として位置づけ、企業による実装を念頭において国家戦略の立案を進める」との見方を示していたとのことだ。
これに対し、松尾氏は「私からすれば7年くらい遅い」と述べて会場の笑いを誘いながらも、「国の総理がこうした発言をするのは実はすごいこと」とコメントしていた。
-

松尾氏が示すAIで日本が勝つための3ポイント

これからのAIはどこまで賢くなるのか
近年は、特に自然言語処理の分野でAI技術の発展が著しい。そのきっかけとなったのがトランスフォーマーと呼ばれるモデルで、マルチヘッドのセルフアテンション(自己注意機構)を多層に重ねたものだ。従来のニューラルネットワークの仕組みとは異なり、重みだけでなく注意の当て方も学習できるため、さまざまな条件に応じて柔軟な処理が可能だ。
-
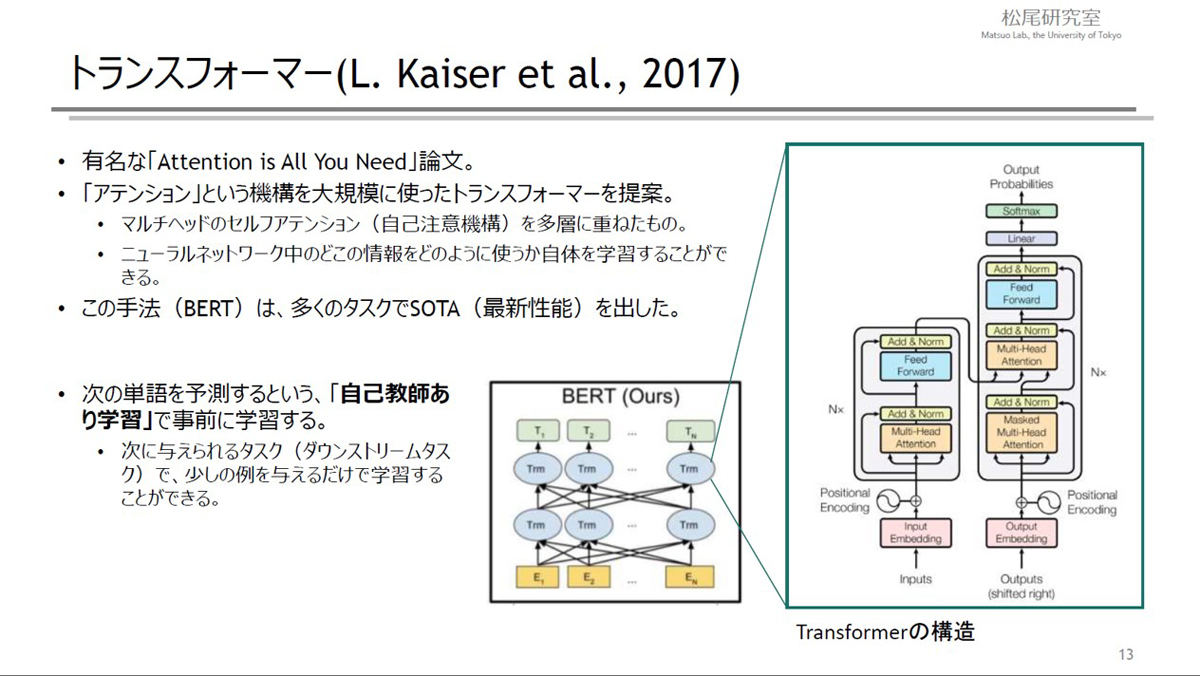
自然言語処理モデル「トランスフォーマー」の概要

2017年に発表されたBERT(Bidirectional Encoder Representations from Transformers)以降、これの性能を上回る自然言語処理モデルが次々と発表されている。BERTは3億4000万程度のパラメータを持つが、2020年にリリースされたGPT-3は1750憶ものパラメータを持つというから驚きだ。
-
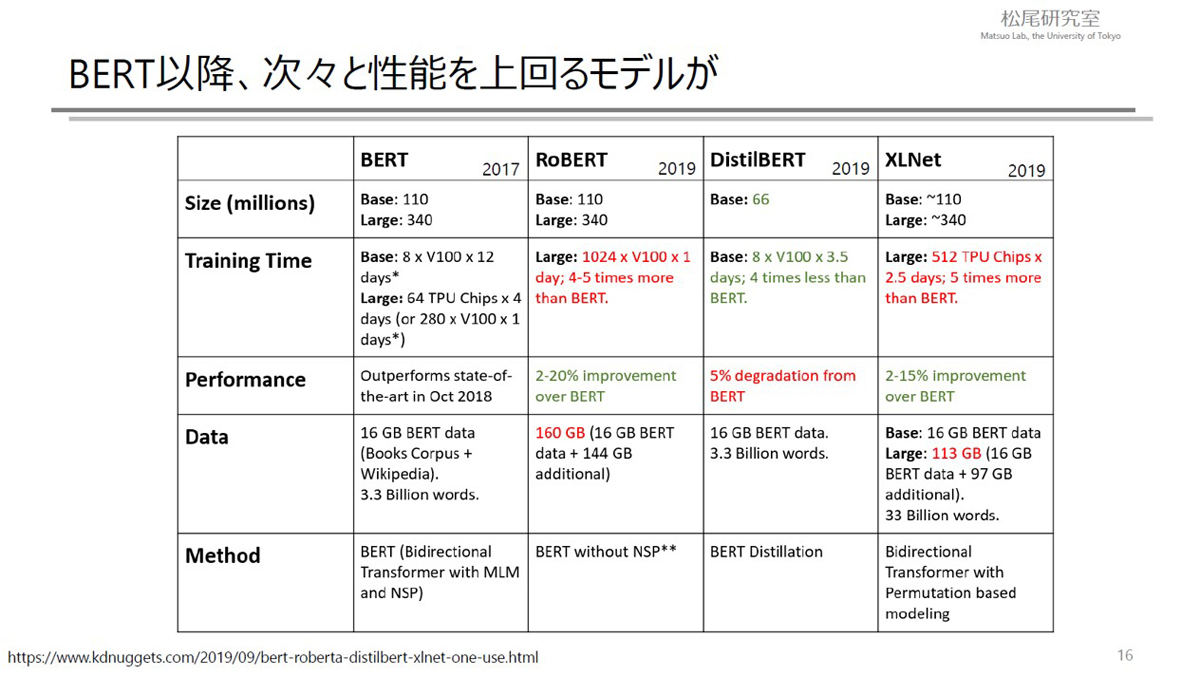
次々と高性能なモデルが発表されている

ここで、松尾氏は「スケール則」を紹介した。データセットのサイズ、計算能力、パラメータのいずれを増やしても、テストロスが単調に低下する、つまり精度が向上するという法則だ。このことは、AIの性能がいわば「数・規模の勝負」になっていることを示している。GAFAM(Google、Amazon、Facebook、Apple、Microsoft)などの巨大テック企業が加速度的に高性能なAIを開発し得るような状態だ。
-

スケール則

一見すると、日進月歩でこのままどこまでも賢く高性能になりそうなAI技術だが、松尾氏は「やはりAI技術やディープラーニングにはおそらく一定の限界があるだろう」と再度強調した。というのも、現行のAIにはあるアクションをフィードバックする系列を備えていないという課題があるからだ。そのため、ロボットAIの研究は画像処理や自然言語処理などと比較してあまり進んではいないという。
AI技術の発展の突破口となりうる3つの注目技術
「従来とはまた何か違った技術的な突破口があるのかもしれない」と松尾氏は述べていた。そして、この突破口のヒントとして、松尾氏の研究室で注目している技術の中から「リザバーコンピューティング」「宝くじ仮説」「強い宝くじ仮説」の3つを挙げた。
リザバーコンピューティングはディープラーニングよりも前から知られていた技術で、リザバーとは「ため池」を意味する。入力層と出力層の間のリザバー層ではランダムなネットワークをつなげて最後に線形回帰法を用いて学習する手法。
-
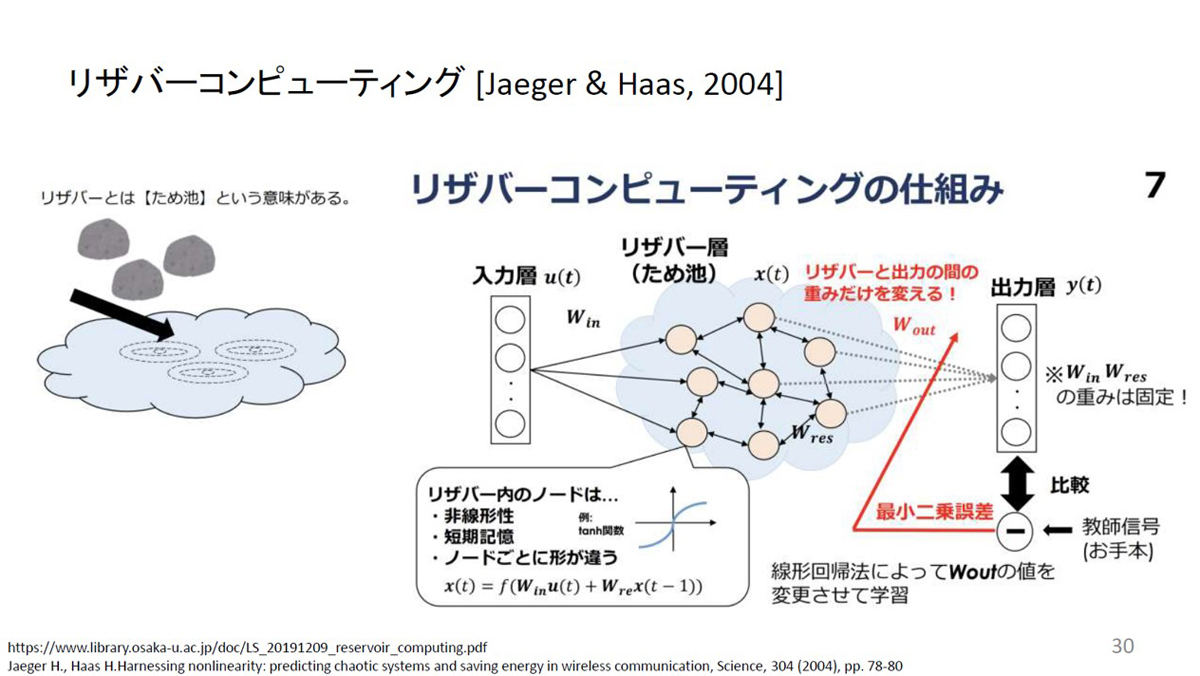
リザバーコンピューティングの概要

宝くじ仮説は、「ディープラーニングはなぜパラメータが多すぎるのに汎化するのか」という疑問を解決するヒントにもなっているという。実は、ディープラーニングでは、学習データと同程度かそれ以上のパラメータを持ちながらなぜ過学習せずに汎化するのかは明らかになっていない。
ディープラーニングでは、学習済みのネットワークで重みが小さいコネクションを刈り取って(=プルーニング)再学習させても精度が下がらないことが以前から知られていた。しかし、刈り取ったネットワークの初期値をリセットしてから再学習すると精度が上がらず、プルーニング前の初期値を使うと精度が上がることが明らかになった。多くのコネクションを持つネットワークの方が、結果的に最良の部分構造を持つ確率が高いので、構造と初期値の組み合わせを「宝くじ」になぞらえた仮説だ。
-
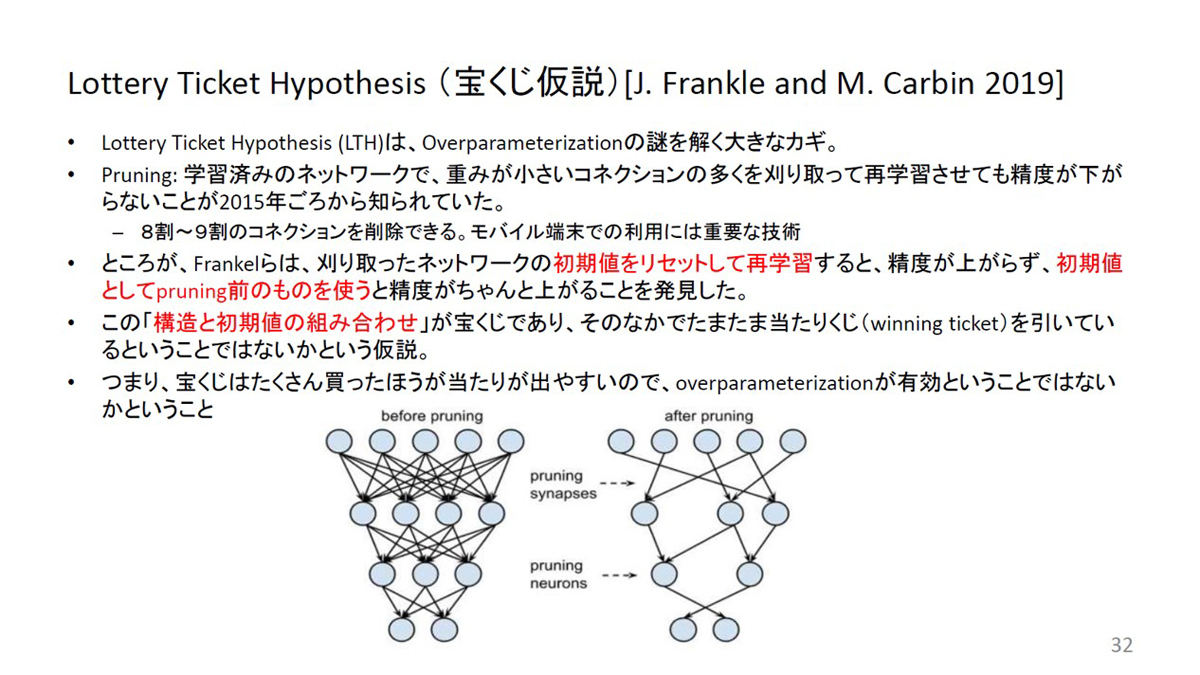
宝くじ仮説の概要

強い宝くじ仮説は、この宝くじ仮説をさらに一歩進めたもので、「十分に深く十分な幅を持つランダムなネットワークは、任意のターゲットネットワークを持つサブネットワークを持つ」という仮説。十分な幅と深さを持つランダムなネットワークであれば、適切な初期値と構造を取り出すだけで精度が上がるため、そもそも学習すら不要なのだという。
-
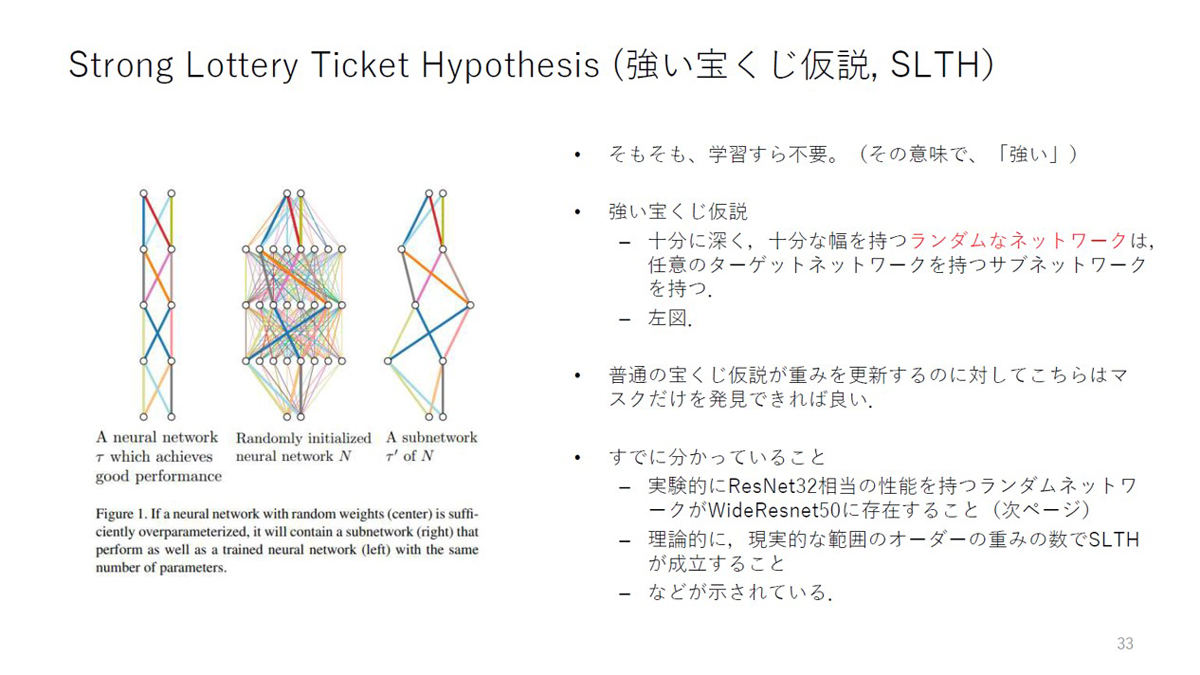
強い宝くじ仮説の概要

これらの3つの仮説は、「あるニューラルネットワークの構造における重みの調整(=学習)は従来から知られている現象なのだが、それ以外にも構造の探索が重要である」ということを示唆している。
実際に、学習を進める過程でモデルを大きくしていくと、学習データに過剰に適合してしまい検証データの予測がうまくいかない段階(=過学習)を越えて、再度予測精度が向上するという「Double Descent」が示されているとのこと。「与えられた構造のなかで重みを調整する」段階と「良い構造を探索する」段階があるのではないかと考えられる。
-
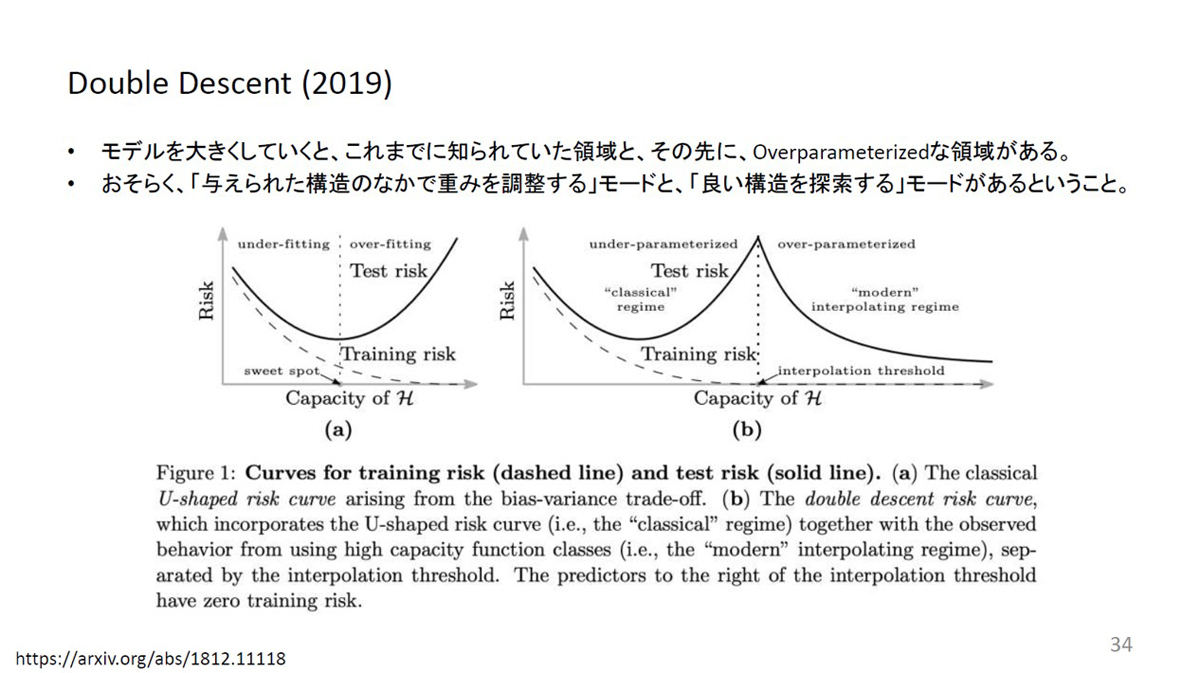
強い宝くじ仮説の概要

松尾氏は、この2つの段階の違いこそが、従来の機械学習の知見と深層学習を分ける決定的な違いかもしれないと主張している。ニューラルネットワークは、人間の脳内のニューロンのようなネットワーク構造を模しているモデルだ。しかし、ニューラルネットワークで主流となっている誤差逆伝播法は人間の脳では見られない。おそらく人間の脳では学習時に重みを調整しているのではなく、適切なネットワーク構造が成立しているのだろう。今後さらにこうした研究が進むことで、新しい技術進化も期待できる。