


「Delta Lake 2.0」と「Databricks SQL Serverless」
その進化を裏付ける証として今回多くの新ソリューションと機能がアナウンスされた。まずは「Delta Lake 2.0」とサーバーレスDWHである「Databricks SQL Serverless」の2つだ。
Delta LakeはLakehouseの中でも最も広く利用されているフォーマットであり、これまではDatabricks上でしか提供していなかったコンパクションやインデクシング、データスキッピングなどの最適化機能をDelta Lake 2.0では完全にOSS化した。
今後も継続的な機能拡充が計画されており、例えばテーブルへの小さい変更(特定レコードの削除など)の際に、従来(大部分は変更なしのデータを含む)は元のオープンソースファイルフォーマットのParquetを再度作成する実装となっていた部分の改善などが次期リリースで予定されている。
-

Delta Lake 2.0の概要

また、Databricks SQL Serverlessは、従来SQLエンドポイントの起動が必要だったSQL処理に関して、サーバレスモードで提供し、ユーザーがクエリをリクエストしてから2秒以内にエンドポイントが利用可能となり、AWS(Amazon Web Services)でパブリックプレビュー、Microsoft Azureでプライベートプレビューが公開されている。
従来は生のデータを取得、クリーニングを経て、レポート作成、クエリを実行するBIと、その先の未来を予測するAIを繋ぎ合わせることはデータやシステム、セキュリティ、分析ツール、カタログをはじめ、すべてサイロ化していたことから苦労していたという。しかし、Lakehouseではこうした課題の解決を可能としている。
Apache Sparkの月間ダウンロード数が4500万回
続いて、米Databricks Co-founder and Chief Architect(共同創業者兼チーフアーキテクト)のReynold Xin(レイノルド・シン)氏が登壇。同氏はApache Sparkのトップコミッターでもあり、Apache Sparkコミュニティの近況と「Spark Connect」を発表した。
シン氏は「パンデミック以降、Apache Sparkの月間ダウンロード数は右肩上がりで上昇し、2020年5月に1323万回、2021年5月が2435万回、2022年5月は4570万回と驚異的な数値を叩き出しています。また、2020年のHackerRankによる開発者サーベイにおいてApache Sparkのスキルを持つ人の賃金は30%近く上昇しているほか、2022年におけるStack Overflowの調査ではトップの給料を払う技術となっているのです」と振り返る。
-

米Databricks Co-founder and Chief ArchitectのReynold Xin氏

同氏は、Apche Sparkというと大規模計算、何千台ものマシン、大きなアプリケーションと多くの人は連想しがちであり、IDをカバーするインタラクティブな環境、Webアプリケーション、エッジデバイス、Raspberry Pi、iPhoneなどに存在しているとは思わないという。
Sparkの設計自体がモノリシックであり、組み込むことを困難にしていることから、Spark Connectを発表。レイノルド氏は「Sparkのパワーをフル活用するために、どこでもアプリケーションを利用できるようにするものです」と説く。
従来はSparkのAPIとしてSQLやPySpark、Scalaなど限定的だったものを、新しくサーバクライアントモデルとして設計。プログラミング言語のGoやIDE(Integrated Drive Electronics)などからネイティブにSpark実行を制御できるようになり、さまざまなアプリケーションからSparkの利用がスムーズになるというものだ。
-

Spark Connectの概要

同氏は「7年前にモバイルでSparkを動かすなんて、とんでもないと思っていましたが、Spark Connectなら実現できるかもしれません。次期リリースはPythonからスタートし、最終的には他のすべてのプログラミング言語のサポートを計画しています」と今後の展望について述べていた。
データにセキュリティとガバナンスを効かせる「Unity Catalog」
次に、米Databricks Co-founder and Chief Technologist(共同創業者兼チーフテクノロジスト)のMatei Zaharia(マテイ・ザハリア)氏が昨年のカンファレンスで発表された「Unity Catalog」、新機能の「Delta Sharing」などの説明を行った。同氏はApache SparkとMLFlowのオリジナルクリエイターでもある。
はじめにザハリア氏は「組織によっては、多くの異なるテクノロジーが存在し、ガバナンスの方法も異なります。例えばAmazon S3のようなデータレイクに多くのデータが保管されている。このようなデータに対してパーミッションを設定する場合、ファイルやディレクトリレベルでパーミッションを設定することができますが、行や列のパーミッションを細かく設定できるということを意味しています。また、データ整理のモデル変更に際してもディレクトリ構造を変更する場合は、すべてのファイルを移動させなければならないほか、データをテーブルやビューとして考えたい場合もあります」との認識を示す。
-

米Databricks Co-founder and Chief TechnologistのMatei Zaharia氏

Unity Catalogは、昨年のData AI Summitで発表されており、あらゆるクラウド上のレイクハウスにあるファイル、テーブル、機械学習モデルなど、すべてのデータ資産に対する統一されたセキュリティとガバナンスを効かせることが可能なソリューションだ。
また、データカタログ、リソースの検索機能、データリネージ機能も同時に提供し、数週間以内に一般提供のリリースを予定している。
ザハリア氏は「Unity Catalogのアイデアは実にシンプルなものです。データベースで作成できるあらゆる種類のデータアセットに対して、パーミッションや監査の管理などのために、単一のインタフェースを用意しています」と説明する。
-
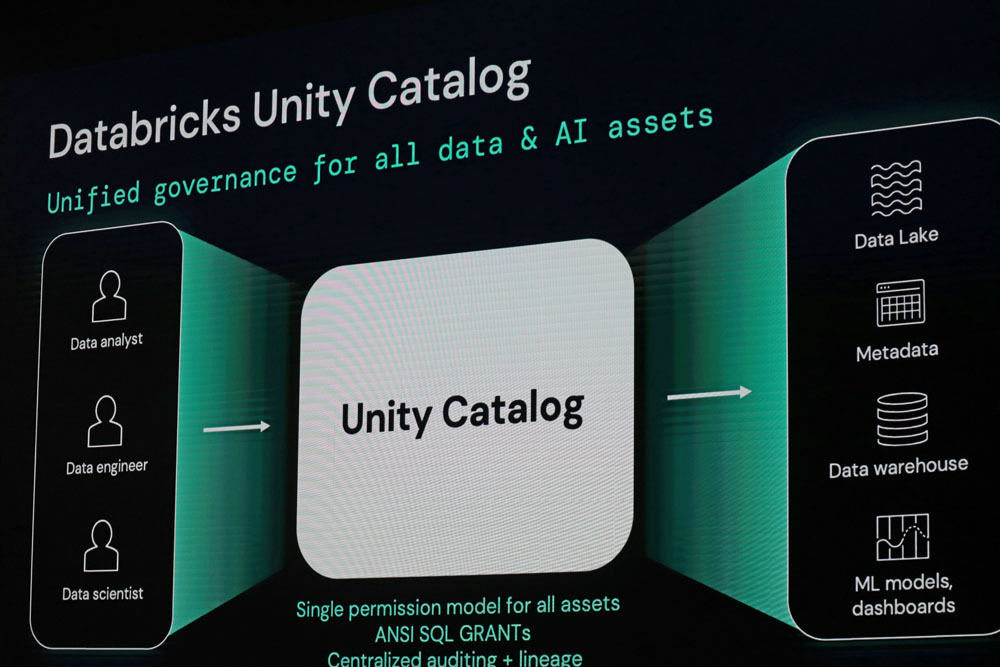
Unity Catalogの概要

一方、昨今のDWHを中心とした多くの独自プラットフォームでデータ共有を行うことが可能になっているが、1つのテクノロジープラットフォーム内のみでしかデータ共有ができないことが課題だという。同氏は「誰かとデータを共有したいと考えたときにベンダーが固定化されているため、5~20もの異なるシステムを使わなければなりません」と指摘。
そのため、Delta Sharingはベンダーロックインなしのオープンなデータ共有のフレームワークを提供。オープンな規格のため組織間、ツール間、クラウドサービス間でデータの共有を可能とし、Unity Catalogと同じく、今後数週間以内の一般提供を予定している。
同氏は「非常にシンプルなREST APIで、どんなプラットフォームでも実装でき、基本的にParquetを処理できるシステムであれば、Delta Sharingを通じてデータを読み込むことができます。プロバイダーはクラウドストレージを構築、サーバを実行し、ユーザーは任意のクライアントで接続できるようになります」と述べている。
-
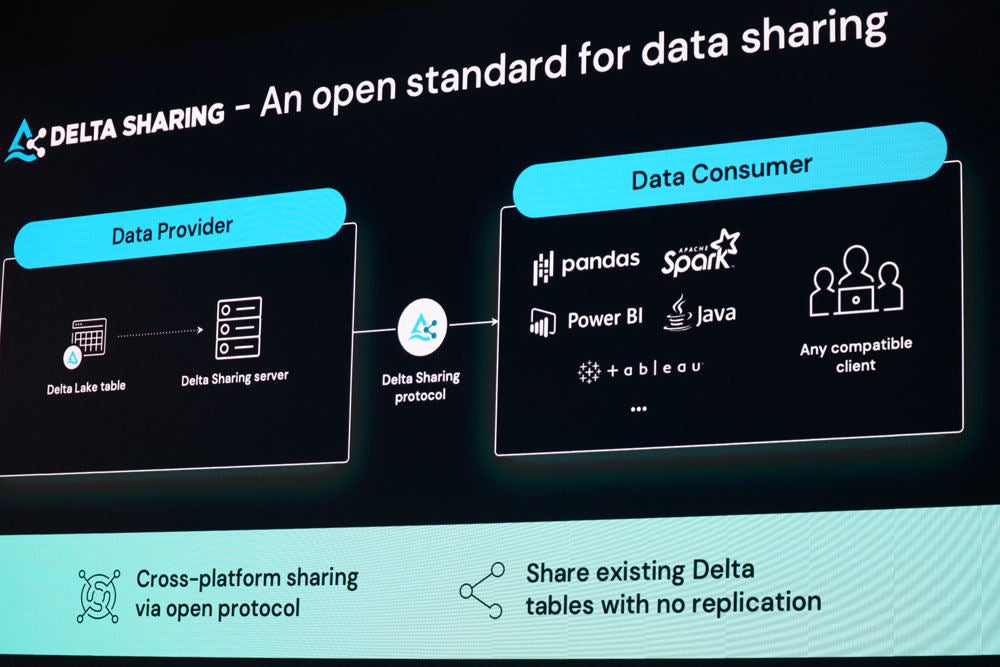
Delta Sharingの概要

さらに、Delta Sharingの技術をベースにデータ以外のnotebookや機械学習モデル、ダッシュボードなどのリソース共有をオープンな形式で可能とする「Databricks Marketplace」を発表。データの販売に限らず、機械学習モデルの販売なども可能となり、ポータルサイトを開設し、一般にアクセス可能なサイトとして運用され、機械学習で使うデータなどをnotebook上からマーケットプレイス経由でクイック連携を可能としている。
-
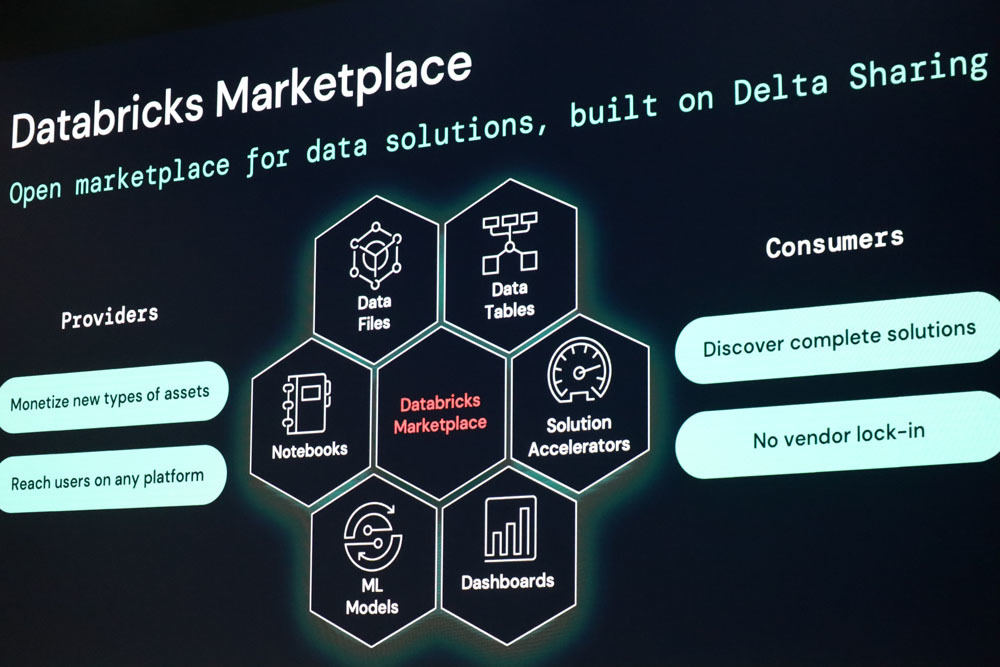
Databricks Marketplaceの概要

また、「Cleanroom」はプライベートデータをセキュリティ保証された環境においてデータ共有、コンピューティングを提供。Delta Sharing(複製なしのデータ共有)、アクセス管理、サーバレスなど、すべてのタイプのデータをサポートするとともに、すべての種類のデータ処理(notebook、SQLなど)などをまとめた機能となる。
-
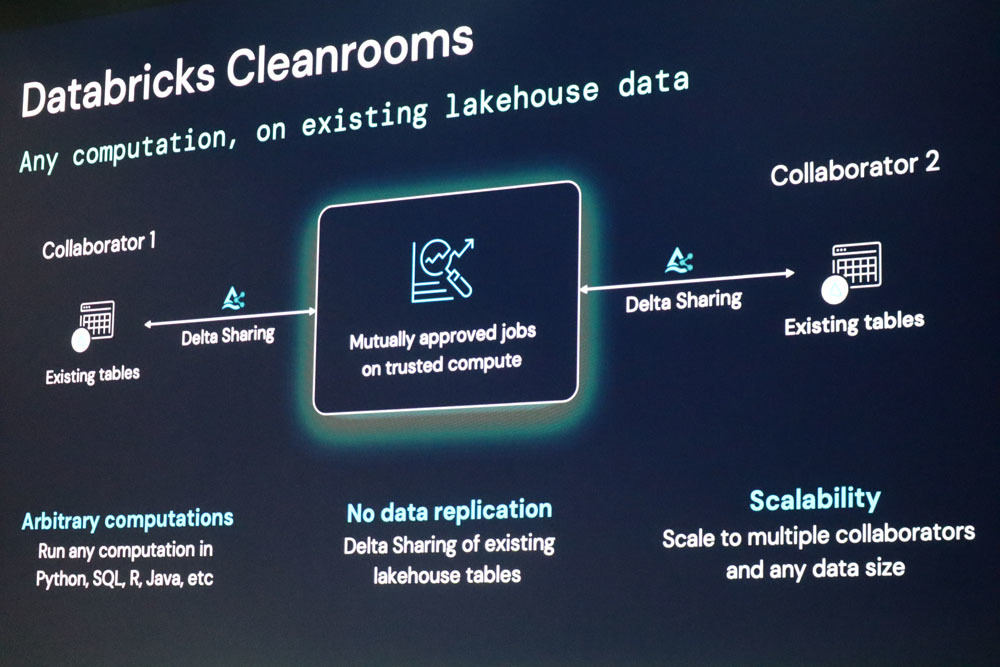
Databricks Cleanroomの概要

このほかにも会期中には「MLFlow 2.0」「MLFlow Pipelines」など機械学習関連のソリューションも発表されている。
これまでMLFlowは、MLの実験環境におけるMLOps(ML運用)の色合いが強かったが、大規模な本番運用をサポート。MLモデルのアルゴリズムを入れ替えた場合でも前処理を共通化する機能など、大規模な本番環境での利用を想定した機能性を提供し、モデルサービングについてはマルチホストでのサービング機能が可能となっている。
加えて、MLFlow PipelinesYAML形式でパイプラインのテンプレート、オーケストレーションを定義してコードベースでの運用を可能としており、リアルモニタリング機能やドリフト検知もDatabricks上のUIベースで可能になっている。














