産総研は6月13日、数式から自動生成した大規模画像データセットを用いて人工知能(AI)の画像認識モデル(学習済みモデル)を構築する手法を開発したことを発表した。
同手法は、AIが学習で使用する大量の実画像やそのプライバシーの確保、ラベル付けコストなど商業利用の際の課題を解消するとともに、実画像や人の判断を経た教師ラベルを用いる現在の手法と同程度以上の画像認識精度を実現しているという。今後、自動運転や医療、物流などさまざまな環境のAI構築で応用が期待できるとのことだ。
-

実画像や人の判断による教師ラベルを必要とせず、数式から生成した教師ラベルで学習された画像理解AIの概念図

具体的には、数式から自動生成した大規模画像データと自動で割り当てられる教師ラベルからなるデータセットを用い、AIの一手法である深層学習によって物体形状の基礎的な視覚特徴を学習することで、画像を認識するAIを容易に構築可能とする学習済みモデルを開発した。
はじめに、汎用的な数式の一つであるというフラクタル幾何によって自動生成した画像データセットを画像認識AIの学習に用いると、実画像と人間が与えた教師ラベルを用いた従来の学習と近い認識精度が出ることを明らかにした。
さらに、フラクタル幾何の画像データで学習した画像認識AIの学習の仕方を調べたところ、主に輪郭成分に着目して物体を識別することが判明したという。
そこで、画像の主要成分が輪郭となるよう、放射状に輪郭を生成する関数を数式に設定した画像データセット(輪郭形状による画像データセット)も構築。これらの画像データセットで学習させた結果、物体を識別するための基礎的かつ良好な視覚特徴を得ることができたという。
識別検証には、画像認識のベンチマークとされるImageNetを使用。ImageNetは1000個のカテゴリに分類された一般物体画像のデータセットだ。インターネット上の画像データとして頻出するさまざまな画像タイプを含んでいるため、ImageNet画像を認識問題(タスク)として与えて認識精度を見ることで、実利用レベルを測ることができるという。
-

学習済みモデルを生成するために用いた画像例。図の上部は従来用いられていた標準的な実画像、図の中央および下部は今回提案の数式(フラクタル幾何・輪郭形状)から生成した画像

検証ではまず、従来の人が教師ラベルを付与した標準的な実画像データセットと、今回開発したフラクタル幾何による画像データセット、輪郭形状による画像データセットのそれぞれで学習済みモデルを生成し、画像認識AIを構築した。
この画像認識AIにImageNetの一般的な物体の画像をタスクとして与えた結果、フラクタル幾何および輪郭形状による画像データセットで構築した画像認識AIの精度は、実画像によるものより高い水準(フラクタル幾何:82.7%、輪郭形状:82.4%、実画像81.8%)を記録したとのことだ。
さらに、フラクタル幾何による数式は拡張できる。例えば、下図の左は3D空間における物体検出を目的とした数式から生成された3Dフラクタルデータだ。この拡張したデータセットを実空間の3Dデータを用いた学習済みモデルに追加学習させることができるという。下図右は部屋内の3Dスキャンデータからの家具検出の例であり、ロボットが部屋内を移動する際などに使用できるとのことだ。
-
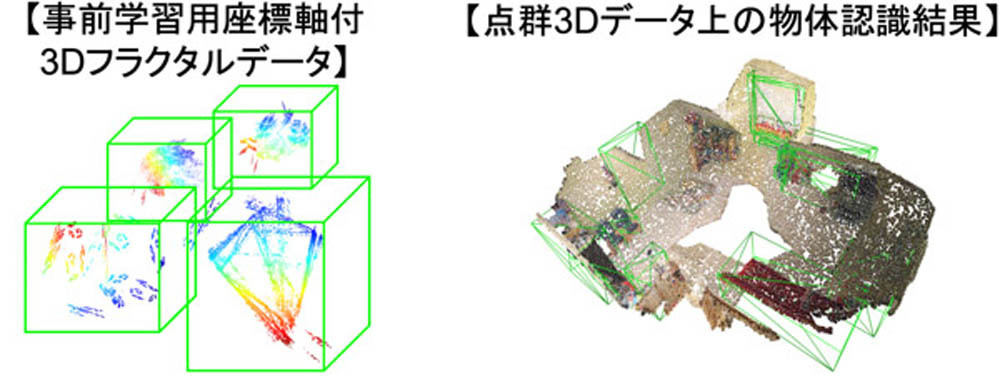
3D空間における物体検出のために拡張したデータセット

以上の結果から、数式からフラクタル幾何や輪郭形状の画像データセットを用いて学習済みモデルを構築する手法は、さまざまな物体が存在する実空間での実用化が必要となる自動運転やロボットの視覚能力への応用が期待できると産総研は見込んでいる。