広島大学は8月31日、富士通研究所と共同で、多くのデータ圧縮方式で採用されている「ハフマン符号」の並列展開処理を高速化する新しいデータ構造「ギャップ配列」を考案したことを発表した。NVIDAのGPU「Tesla V100」を用いて実験した結果、従来の最速展開プログラムと比較して、2.5倍から1万1000倍の高速化を達成できたとしている。
同成果は、同大学大学院先進理工系科学研究科の中野浩嗣教授らの共同研究チームによるもの。詳細は、2020年8月に開催された国際会議「International Conference on Parallel Processing (ICPP)」において発表され、269件の投稿論文の中から最優秀論文賞に選ばれた。
インターネットを介して多数の画像ファイルや動画ファイルなどを転送したり、また記録メディアに保存したりする際、データの圧縮は誰でも日常的に行っている。そうした多くのデータ圧縮方式に組み込まれているのが、ハフマン符号である。
ハフマン符号とは、1バイト(8ビット)の記号を可変長のビット列の符号に置き換える変換表(コードテーブル)を用いて、バイト記号列をビット列(可変長符号列)に変換するデータの符号化方法である。頻繁に出てくるバイトに対して短いビット列を割り当てることにより、変換後のビット列の長さを短くできることが特徴だ。圧縮方式のgzipやzip、またjpegやpngなどの画像形式にも組み込まれており、誰でも知らないうちにその恩恵に授かっているのである。
しかし現在はデータの容量は増大する一方で、ハフマン符号の圧縮・展開処理のさらなる高速化が望まれている。近年のプロセッサは単体での高速化が頭打ちとなっているため、複数のコアを搭載して処理を同時に行う並列処理が採用されている。ハフマン符号は、圧縮する際は並列処理は比較的容易だが、展開処理を行う際は並列化が困難だった。そのため、これまで高速化が進んでこなかったのである。
なぜ圧縮する際は容易なのかは、例を見ればわかりやすい。たとえばA、B、C、D、Eというバイト記号5文字の可変長符号がそれぞれ00、01、10、110、111として、「ABDEABDCBCBDCE」というバイト記号列を圧縮するときは、バイト記号ごとに複数のコアに処理を割り振り、最終的に連結すれば済むからだ。その結果、圧縮された可変長符号列は「000111011100011101001100111010111」となる。
この可変長符号列を展開して元のバイト記号列に戻そうとする場合、どうだろうか。適当なところで区切って複数のコアに処理をさせるわけにもいかず、元のバイト記号列に戻すには頭から順に変換していく必要がある。これが、ハフマン符号の展開処理が並列処理に向かない理由だ。
そんな適当なところで区切って並列処理を行えるようにしたのが、ギャップ配列である。まず可変長符号列を同じ大きさのセグメント(256ビット程度)で分割する。当然この場合、ひとつの可変長符号がふたつのセグメントにまたがってしまう可能性があり、セグメントを構成するビット列からでは、そのまたがっている可変長符号を認識することはできない。
そこで、またがってしまう可変長符号の次の符号のビット位置(ギャップ)をあらかじめ圧縮時に保存しておくことで、そのセグメントの本来の先頭の符号を識別するようにしたのだ。すべてのセグメントのギャップ値を並べたものがギャップ配列であり、その値を用いれば各セグメントを並列化して展開することも容易となる。
ギャップ配列を圧縮処理時に生成するため、それだけ処理に時間を要するのは事実。しかし、処理時間の増加は4~18%程度であるという。たとえばこれまで5秒かかっていたものが、5.2~5.9秒程度になるということだ。同様に、ギャップ配列の分だけ圧縮データのサイズも増加してしまうが、増加量は0.4~1.5%。デメリットと呼ぶほどでもない増加である。
実際に中野教授らは、並列処理での高速化を実際に確かめるため、GPU「Tesla V100」を用いて用いて10個のさまざまなタイプのファイルを対象に性能評価を実施。その結果、ギャップ配列のない従来のハフマン符号の圧縮処理における既知の最速プログラムと比較して、2.5~7.4倍の処理時間の高速化が確認された。そして展開処理については、2018年に発表された並列展開処理を行う方法と比較したところ、2.5~1万1000倍の高速化を達成したという。
今後は、gzipやzipなど、処理の一部にハフマン符号を含んでいる圧縮方式に今回開発したギャップ配列を組み込んで、これまではできなかったGPUによる圧縮・展開処理の高速化を実現するとしている。さらに、ビッグデータ、機械学習、クラウドコンピューティングなどの実際のアプリケーションにギャップ配列付きハフマン符号によるデータ圧縮を利用して、処理時間の短縮を目指すとしている。
-
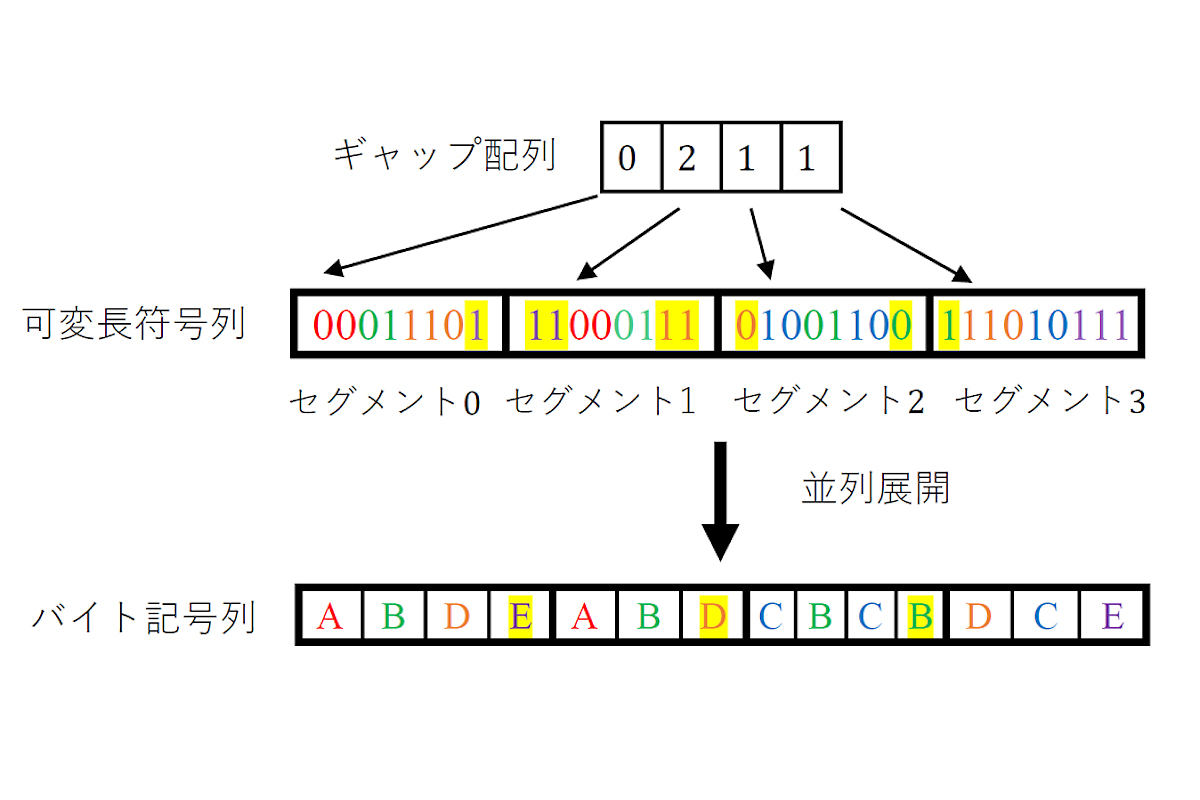
ギャップ配列の考え。可変長符号列を同程度の長さのビット列に区切ると、ひとつの可変長符号がふたつのセグメントにまたがってしまう。そこでギャップ配列では、ふたつ目以降のセグメントにおいては、先頭から何文字目までが、ひとつ前のセグメントの最後にある可変長符号の続きであることがわかるようにしてある (出所:広島大学Webサイト)