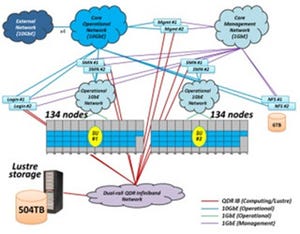
ピーク演算性能を引き上げたHPC-ACE
HPC-ACEでは、浮動小数点(Floating Point)レジスタの個数を、従来の32個から256個に拡張している。そして、第1の命令の演算(オレンジ)と第2の命令の演算(青)を偶数番レジスタと奇数番レジスタのペアについて並列に実行するようになっている。

|
|
通常のSPARC64プロセッサ(左)とHPC-ACEアーキテクチャ採用SPARC64プロセッサの浮動小数点演算器の比較 |
この偶数番と奇数番ペアに同じ演算を行うというやり方はIntelプロセサのSSEと同じ考えで、命令の処理機構はそのままで、ピーク演算性能を2倍に引き上げることができる。また、浮動小数点レジスタの個数を大幅に増やしたことにより、レジスタ不足のために中間結果をキャッシュに書き戻したり、再度、読み込んだりするロード、ストア命令を削減し、演算性能を高める効果がある。
また、HPC-ACEでは、繰り返し使われるデータと一過性のデータを格納するキャッシュ領域を分割し、繰り返し使われるデータが一過性のデータの格納で追い出されることが無いようにするセクターキャッシュなどの機構が追加されている。
そして、京コンピュータ用に開発されたSPARC64 VIIIfxチップは8個のコア、4チャネルのDDR3メモリインタフェースと計算ノード間を繋ぐICCチップとのインタフェース(HSIO)を1チップに集積している。

|
|
8コアのSPARC64 VIIIfxプロセサのチップ写真(Hot Chips21での発表資料から転載) |
SPARC64 VIIIfxプロセサの主要な諸元を次の表に示す。

|
CPUとペアになるICCチップは、CPUと接続する4つのポートと10個の外部接続ポートを持っている。各ポートは5GB/sの速度の送信と受信を並行して行うことができる。4個の通信エンジンはリモートDMA機能を持ち、CPUのメモリとICCを経由して他のノードのメインメモリとの間で送受それぞれ4系統のデータ転送を行うことができる。

|
|
ICCチップのブロックダイヤグラム |
クロスバを経由して通信エンジンは、10個の外部ポートからのデータを受信したり、CPUからのデータを外部ポートに送り出したりすることができる。また、クロスバは通信エンジンとは無関係に外部ポート間でデータを転送することができる。
京コンピュータの計算ノード間を繋ぐTofu(Torus fusion)インタコネクトは、物理的には隣接ノード間だけの接続であり、隣接していないノードとの通信は中間のノードをバケツリレー式にデータを転送していく必要がある。しかし、このバケツリレーはICCチップが自動的に行ってくれるので、CPUの介在は必要無い構造となっている。
また、ICCはPCI Expressポートを2ポート持っており、IOノードでは、グローバルIOネットワーク用のInfiniBandや制御・管理用のEthernetおよびローカルファイルシステム用のFibre ChannelはこのPCI Express経由で接続されている。

|
|
ICCのチップ写真に各機能をオーバレイで示している(Hot Chips 22での発表資料から転載) |
ICCは外部ポートのリンクやCPUとの接続ポートでチップのサイズが決まってしまうので、CPUより1世代古い65nmテクノロジで作られ、チップサイズは18.2mm×18.1mmである。クロックは312.5MHzで部分的に2倍の625MHzで動作している。ICCの消費電力は発表されていないが、水冷のヒートシンクの大きさから見て、CPUの1/2~1/3程度ではないかと思われる。
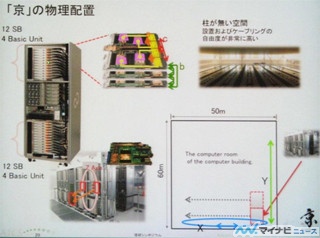
そして、次の写真のように、筐体の上側と下側にそれぞれ12枚のシステムボードが搭載され、中央の右側には6つのIOノードが搭載されている。

|
|
SC10で展示された京コンピュータの計算ノード筐体 |