しかし、このハードウェアの動きを見てみると、命令のフェッチを行っている間は、演算器は休んでいる。また、演算を行っている間は、命令のフェッチを行う部分は休んでいる。これはもったいないので、最初のLD命令のフェッチが終わり、(2)の命令の解釈にはいったら次のADD命令をフェッチし、というように流れ作業的に処理を行えば良いという考えが出てきた。命令のフェッチ、解釈、実行というそれぞれの処理を行う作業ステーションが並んでおり、命令がベルトコンベヤーに乗って、進みながら処理されて行くというイメージである。しかし、これを考えた人は、ベルトコンベヤーではなく、パイプラインに命令を流し込んで行くという処理をイメージしたようで、パイプライン処理という名前が付けられている。
図2.6の処理では、1命令を処理するのに平均4サイクル掛かっていたが、仮に、このようにパイプライン的に処理ができたとすると図3.1のように、1サイクルごとに次の命令を処理できることになる。ここで取り上げたプロセサでは、順次に命令を処理すると4サイクル/命令程度の性能であるが、これが1サイクル/命令になれば、おおよそ4倍に性能が向上する。
 |
図3.1:パイプライン的な処理の状況 |
しかし、本当に、このようにうまく行くのであろうか?
構造的ハザード
次の図3.2は、上記の3命令の後にもう一つADD命令をつけて、4命令をパイプライン的に実行する場合に、それぞれの命令が、各サイクルで必要とする資源を書いたものである。
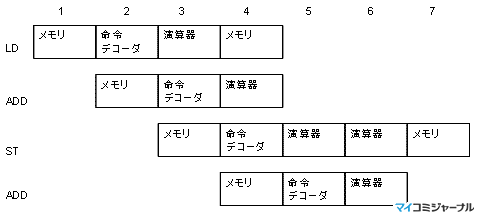 |
| 図3.2:4命令をパイプライン的に実行する場合、それぞれに命令が必要とする資源 |
図3.2を見ると、3サイクルまでは複数の命令で同じ資源が必要とされていないので、パイプライン的な実行が可能であるが、第4サイクルでは、最初のLD命令と4番目のADD命令がメモリを使うことになる。また、第6サイクルには、3番目のST命令と4番目のADD命令が演算器を必要とする。しかし、これらの資源は1個づつしか無いので、実は、図3.2のような実行はできない。
このような、パイプライン実行の障害となる必要資源の競合を構造的ハザード(Structural Hazard)と言う。つまり、パイプライン実行を行うには、構造的ハザードが生じないようにしなければならない。この例では、次の図3.3のように、4番目のADD命令の開始を1サイクル遅らせてやると、資源は競合しなくなりパイプライン実行が可能になる。
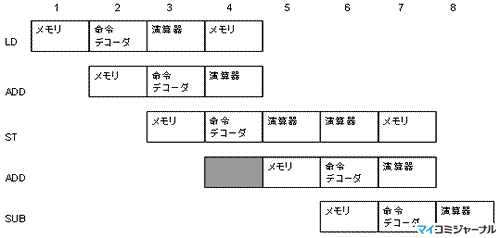 |
図3.3:空きサイクル(グレーの部分)を入れ、資源競合を解消 |
パイプラインは、理想的には途切れなく命令を処理すべきであるが、このような空きサイクルが入ると処理が途切れることからパイプライン ストール(Stall)、また、すべて命令が詰まっているべきところに空きサイクルの泡が入るので、この空きサイクルをパイプライン バブル(Bubble)などと呼ぶ。
パイプラインバブルを入れて構造的ハザードを解消するのは一つの手であるが、空きサイクルの分だけ性能は低下する。一方、性能を低下させないで構造的ハザードを解消するには、競合しないように資源を増やせば良い。次の図3.4に一例を示す。この図で、ピンクのブロックが追加された部分で、第4サイクルのメモリの競合に関しては、命令メモリとデータメモリに分割することでハザードを解消している。実際のプロセサでは、何らかの方法で命令メモリに命令を書き込むためにメモリデータレジスタが必要であるが、ここでの説明には必要ないので、この図では省略している。また、第6サイクルの演算器の競合は一般の演算とストア命令でのレジスタ値の格納のためのレジスタ読み出しの競合であり、この例では、ストアデータをメモリデータレジスタに格納する専用のレジスタとメモリデータレジスタへのパスを設けることでハザードを解消している。なお、図3.4のレジスタファイル1と2は同じ内容を保持する必要があり、書き込みは、両方のレジスタファイルの同一エントリに並列に書き込み、読み出しの場合は、レジスタファイル1はADD命令の演算のオペランドを読み出し、レジスタファイル2はST命令のストアデータを(一般的にはADD命令のオペランドとは異なる番号のレジスタから)読み出すというように動作させる。
 |
図3.4:資源追加で構造的ハザードを解消 |
図3.5に、図3.4の資源追加で競合を解消したパイプラインの実行状況を示す。
 |
図3.5:資源の増強で構造的ハザードを解消した図3.4のプロセサの実行状況 |
なお、このようにレジスタファイル2からのストアデータの転送専用パスを設けると、ST命令のアドレス計算の演算器1のステージとストアデータ転送を別々のサイクルで実行する必要はない。従って、ST命令は、第3サイクルでアドレス計算とストアデータの転送を行い、第4サイクルでメモリに書き込むという制御とするほうが効率が良い。