
前回はP-CoreとE-Coreの話に終始してしまったので、今回はもう少し広範な話をしたい。
謎のMemory Side Cache
Photo01は基調講演のスライドから切り出して、ついでに複数のスライドの情報を重ね合わせたものである。上側がCompute Tileであるが、向かって右端にP-Core×4+12MB L3 Cache、その下にIPU(Image Processing Unit:通常ならISPと呼ばれるが、要するにカメラ入力に対応した画像処理エンジン)、右にNoCが入り、そのNoCの上にMedia EngineとMemory Side Cache、NOCの下にE-Core×4+4MB L2 CacheとDisplay Engine、その左がNPUとなり、一番左端がGPUとなっている。ちなみにCompute Tile右下の青い部分はD2D(Die to Die Interface)で、ここでPlatform Controller Tileと接続する形になる。
そこまでは良いとして、このMemory Side Cacheとは何者か? という話になる。実はこのMemory Side Cache、Technical Sessionでは一切説明が無かった。ただ基調講演のスライド(Photo02)の中にヒントが示されていた。このMemory Side Cache、容量は8MBとの事であるが、これを利用できるのはCPU(と一部I/O Device)のみで、少なくともGPUからは扱えない事は質疑応答の結果として判明している。要するにGPUでRay Tracingを行う時のWork Areaだったり、解像度を上げたときのWork BufferあるいはTexture Cache的な使い方は一切出来ない事になっているそうだ。
-
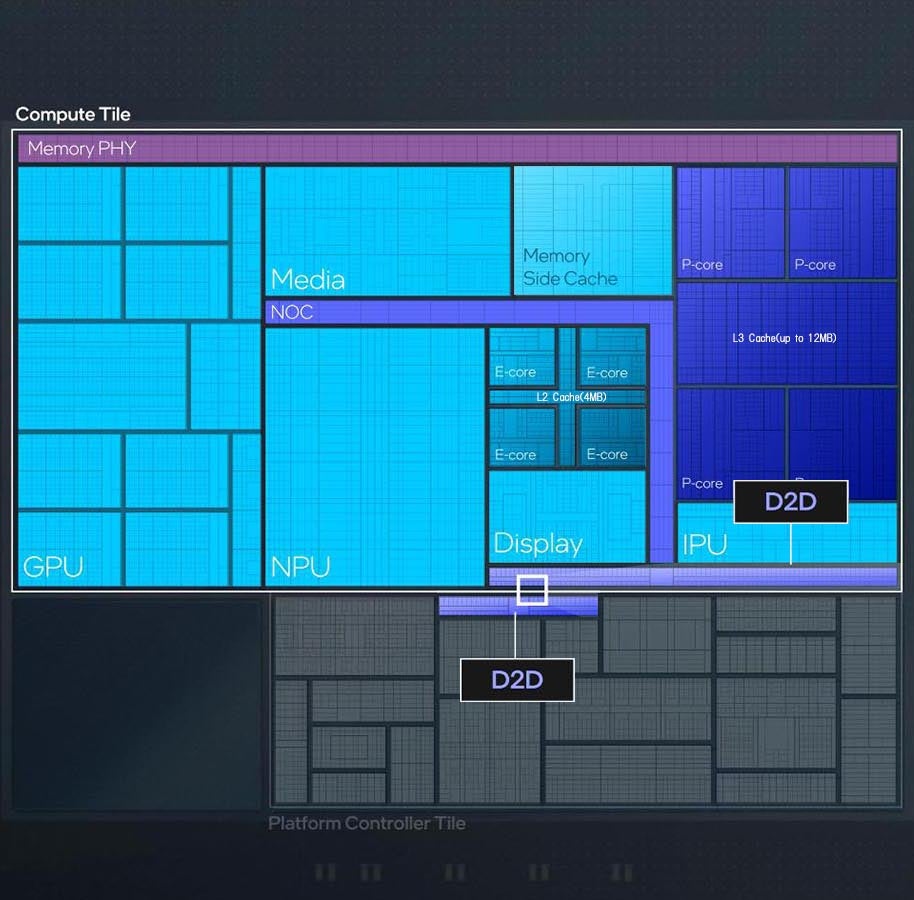
Photo01: NoCはNetwork on Chipで、要するに内部のエンジンやCPUコア、GPUなど同士を相互に接続する格好。Memory I/FはMemory Side Cacheの先に置かれているものと想像される。

-
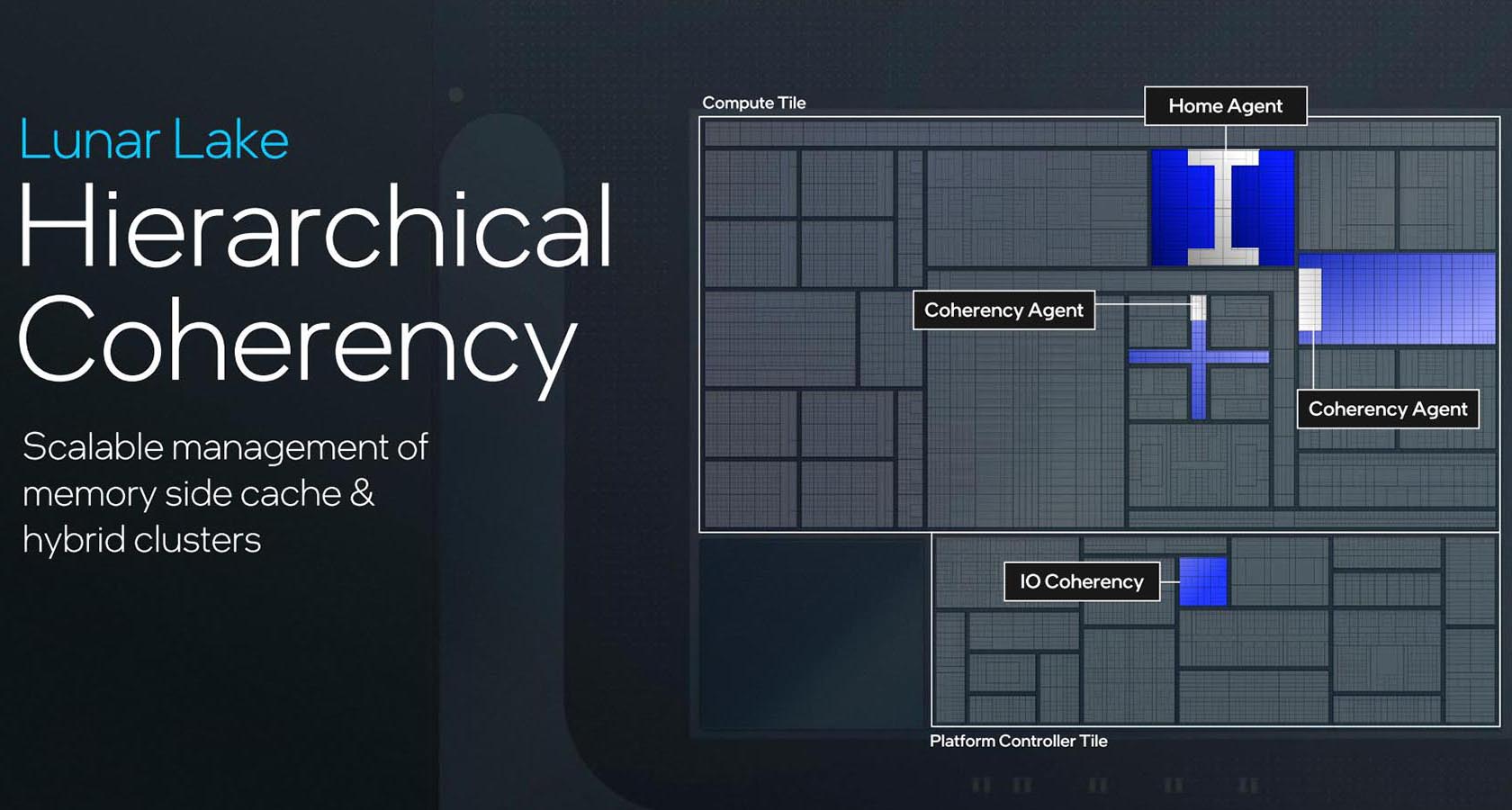
Photo02: Memory Side Cacheの中にHome Agentがあり、P-Core/E-Core側にはCoherency Agentが置かれているというのがポイント。

さて基調講演でも詳しい話は一切出なかったのだが、このMemory Side CacheがHome Agent、つまり全体のCache Coherencyの管理を行っており、P-CoreのL3やE-CoreのL2にはCoherency Agentのみが置かれている(あとはPlatform Controller TileにもI/O Coherency Agentが置かれる)という事は、このMemory Side CacheはP-CoreのL3、あるいはE-CoreのL2のBackside Cacheとしてだけ働くことになる形だ。ただこれがL4にならないところがポイントである(L4として働くのであれば、その旨がP-CoreやE-Coreの説明に当然あってしかるべきだからだ)。
ここからは4.以外筆者の推定だが、Memory Side Cacheは大きく4つの働きを行っていると考えられる。
(1) P-CoreとE-CoreのCache Coherencyを取る
これはまぁPhoto02に出て来た内容そのものであるが、これを馬鹿正直に実施すると、P-CoreとE-Coreの間のトラフィックが馬鹿にならない。加えると、P-CoreとE-Coreでは後述するように別々の処理を割り当てる事が多い「筈」(これはThread Directorの采配次第)なので、実際にCoherencyを取る場面は少ないと考えられる。これを確実に行おうとしたら、「P-CoreのL3及びE-CoreのL2が、どのアドレスをキャッシュしているか」の一覧を持っておき、Cacheの変更があった場合はこの一覧を参照するのが便利である。いわゆるSnoop Filterである。最初にこれを搭載したのはIntel 5000Xチップセットであるが、この時は実装に問題があったのかSnoop Filterを有効化するとむしろ遅くなるとかいう騒ぎだったが、その後も普通に利用されており、Xeon Scalableでは標準でCHA(Cache and Home Agent)にSnoop Filterが実装されている。Memory Side Cacheの一部は、このSnoop Filterのために利用されているのではないかと思う。
(2) (真の意味での)Memory Cache
Lunar Lakeは、LPDDR5X-8533が搭載されており、一見DDR5-5600止まりのRaptor Lake/Raptor Lake Refreshなどより高速に思えるのだが、実は構成が32bit×2の64bit幅(Raptor Lakeなどは128bit幅)なので、メモリ帯域は68.3GB/secでしかなく、LPDDR5X-7467を利用できるMeteor Lake(119.5GB/sec)は元よりDDR5-5600利用時のRaptor Lake(89.6GB/sec)にも及ばない程度である。この帯域の低さを少しでも補うためには、より長時間Burst Accessを行うのが効果的であり、その際のRead Cacheとして利用できるほか、P-CoreとE-Coreが各々勝手にWriteを行うと書き込み効率が落ちるので、Write Back Cacheを用意して多少なりともまとめてWriteが出来れば効率改善に役立つ。そうした使い方は当然考えられる。
(3) Low Power Modeからの復帰の高速化
Meteor LakeではSoC TileにLP E-Coreが搭載されており、なのでCompute Tile全体をシャットダウンしてもLP Tileが生きていれば高速復帰が可能だった。ところがLunar Lakeではこのあたりが完全に変わっており、Platform Controller TileにはE-Coreが存在しないので、復帰はCompute Tileを動かす必要がある。といっても、省電力のために待機時は恐らくP-Coreのブロックは完全にシャットダウンされているだろうし、E-Coreも怪しい。問題はここでP-CoreやE-Coreを完全にシャットダウンする場合、Processor Statusとか直近のキャッシュの内容もメモリに書き戻すしかない訳で、その場合復帰には時間が掛かる。そこでこうした情報をMemory Side Cacheに保持しておき、P-CoreやE-Coreを落とした状態でもMemory Side CacheのRetentionだけ維持しておけば、立ち上げの高速化につながる事になる。勿論Suspendの場合にはMemory Side Cacheも電源が落とされることになるから内容の保持は不可能だが、比較的軽い待機状態であればこの方法で迅速な立ち上げが可能になると思われる。
(4) Media Engine用キャッシュ
唯一Intelが明確に用途(の一つ)として示したのがこちら(Photo03)。要するに動画再生に当たって、Memory Side Cacheをその動画コンテンツのキャッシュに使えるので、煩雑にMemory Accessを行わずに済むため、帯域と消費電力両方の削減になる、というものだ。
-
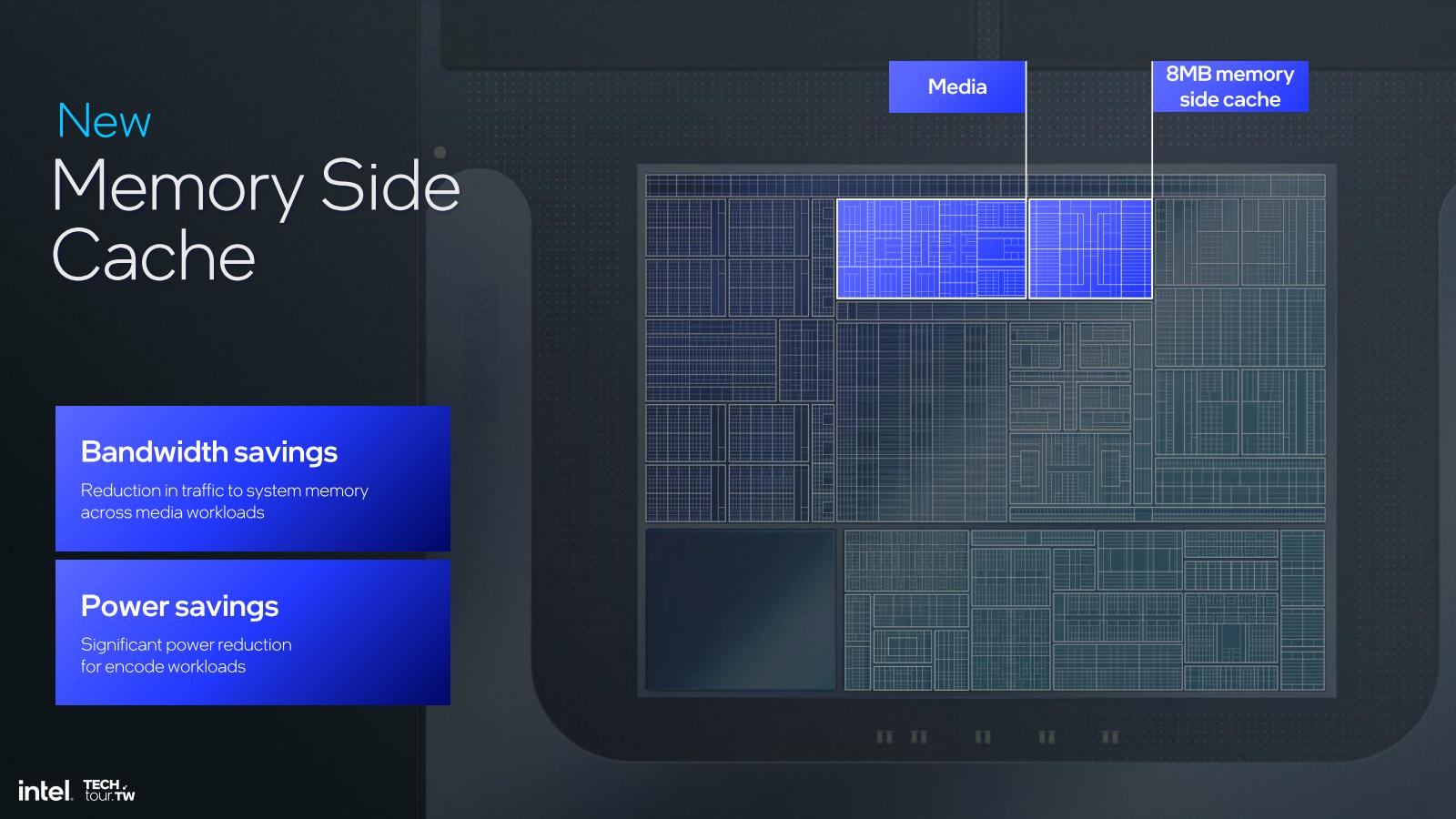
Photo03: Media EngineはMemory Side Cacheから読み出しが可能であり、これでMemory Accessの頻度が減らせるとする。

というあたりだ。最初の3つについては、本当かどうかはまだ不明だが、一応辻褄が合うのではないかと思う(流石にMedia EngineのためだけにMemory Side Cacheを設けたとは思い難い)。
Memory
ついでにMemoryについても説明しておきたい。こちらにもある様に、Lunar Lakeはパッケージ上に2つのLPDDR5Xを搭載するが、外部への拡張は不可能である。そしてバス幅は16bit×4channelとなっている。まずこの64bitというのが不可解である。こちらの記事にもある様に、COMPUTEXで公開されたサンプルにはSamsungのLPDDR5XのES品が搭載されていた訳だが、そのSamsungのLPDDR5X一覧を見ると、チップあたりx64の製品もラインナップされており、128Gbit(チップあたり16GB)で8533MHz動作の製品も2つある。おまけに量産中になっており、これを利用すれば128bit幅が実装できた筈である。にも拘わらずx64構成で良しとしたのは
- 消費電力的にx128だと大きくなりすぎる
- パッケージ側の問題でx128が実装出来ない
- 十分な数の供給が望めない、あるいは価格面で折り合いがつかない
あたりがぱっと思いつくのだが、どれも説得力のある答えとは言えない。競合製品であるSnapdragon X Eliteは128bit(16bit×8ch)構成で、LPDDR5X-8448をサポートし、最大帯域が135GB/secであることを考えると、これは大きなビハインドである。ちなみにテクニカルセッションでは、より大容量のメモリとか高い帯域についての質問が投げかけられ、「そのうちより大容量、あるいは高速なLPDDR5Xが出てくる事に期待したい」的な返答があったらしいのだが、確かにSamsungは今年4月に10.7GbpsのLPDDR5Xを発表、量産は今年後半で最大32GBの容量になるとしている。もしこれを利用出来れば85.6GB/secまで帯域は高まるし、メモリの合計容量は64GBになる訳だが、可能性としては極めて低いと言わざるを得ない。そもそもLunar Lakeがずっと販売され続ける製品であれば、あるいは途中でメモリのUpgradeが入る可能性はあるが、今年中にArrow Lake、更にその後にはPanther Lakeが投入されることが既に予告されている以上、Lunar Lakeの製品ラインが長期間に渡って提供される可能性は低く、そうなると多分途中でLPDDR5Xのスペックが変わる事は考えにくい。
GPU
次にGPUの話を。Meteor Lakeの時にはXe LPGが利用されていたが、Lunar LakeではXe2になった(Photo04)。主な違いは効率向上と処理分散効率の向上、S/Wのオーバーヘッド削減であるとしているが、このレベルでは具体的な方法論は見えてこない。Xe世代と比較しての要素別の効率比較(Photo05)では最大12.5倍とされるが、Xeのどの世代との比較なのかは不明である。ちなみに同種のグラフはMeteor Lakeの時も示された。
さてそんなXe2ではスケーラビリティを重視した、としている(Photo06)。具体的にはRender Sliceの数だけでなく、Render Slice内のXeコアの数も変更できるようにしたよう(Photo07)。Xe-LPGだとSliceあたりXe-Core×4だったから、多少構成変更ができる事になる。ただLunar Lakeに関して言えば2 Render Sliceで個々のRender SliceあたりXe-Core×4と、Meteor Lakeと同じ構成になっている模様だ(Photo07)。
-

Photo04: XeにはHPC/HP/HPG/LPが当初あり、HPが途中で消えて代わりにLPGが入った。Xe2はLPGとHPGのみがある、という情報はあるのだが、してみるとLunar Lakeに搭載されるのはLPGであろうか?

-
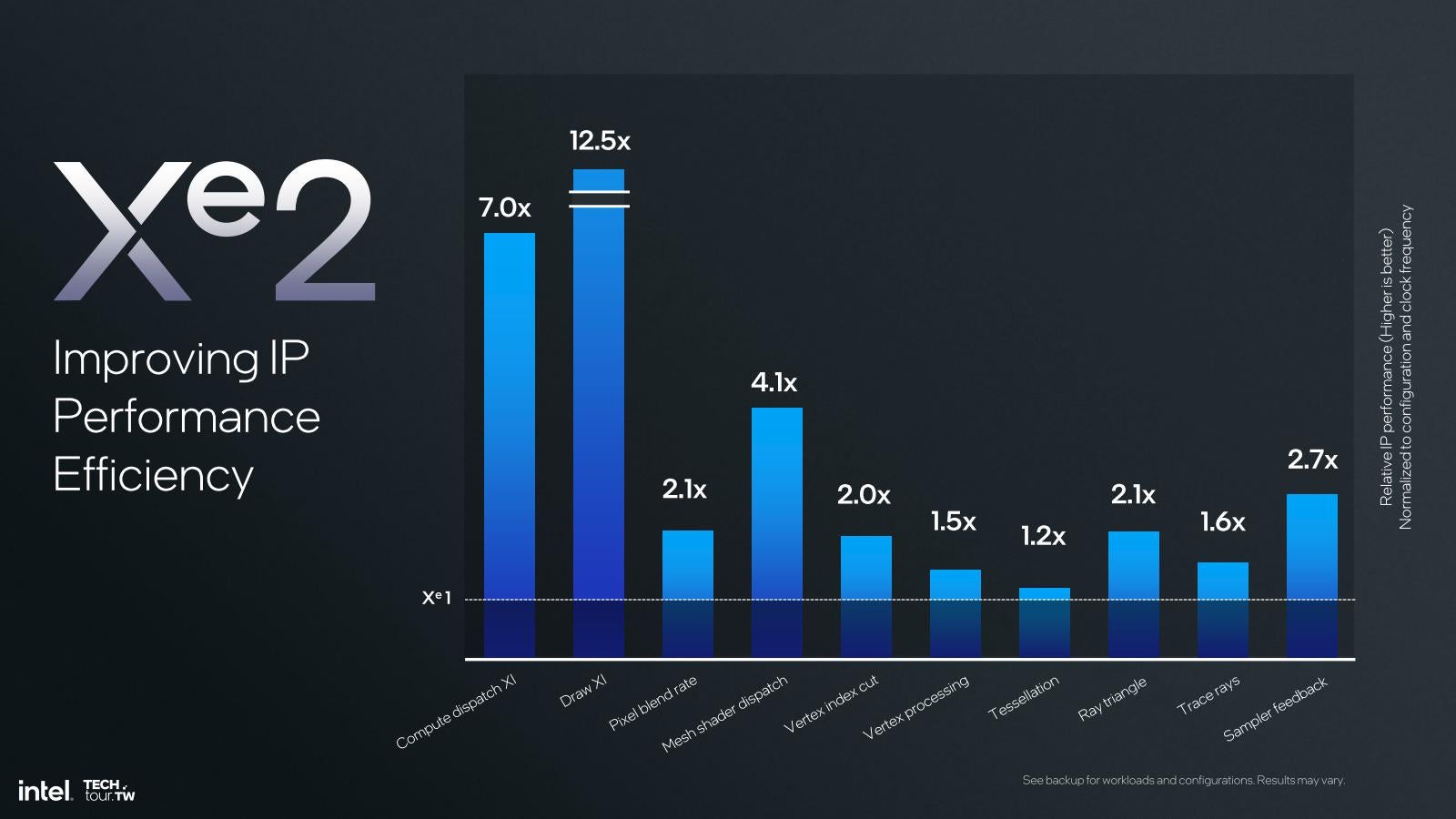
Photo05: あくまで効率であって絶対性能では無いことに注意。あと比較対象、脚注にもXe-coreとしか書いてないあたり、Xe-LPあたりとの比較だろうか?

-

Photo06: これはあくまでもXe2全般の話で、Lunar Lakeはもっとこじんまりしている。

-

Photo07: Meteor Lakeの構成はこちら。Vector Unitの数の相違は後述。実のところこのレベルでの違いは、L2の容量(4MB→8MB)しかない。

個々のXe-Coreの構造だが、Meteor LakeというかXe-HPGと比較した場合
- XVE(Vector Engine)の幅が256bit→512bitになり、その代わり16個→8個になった
- 2048bitのXMX(Matrix Engine)が復活した
- 64bitのAtomic命令が追加された
という形になる(Photo08)。Vector Engineの数はXe世代から半減したが、その分各々のVector Engineの性能が2倍になったので、トータルすると性能は変わらない格好だ。また個々のVector Engine、Xe世代では2つのVector Engineが1つのThread Controlから制御される形になった(Photo09)。ただ結果として、Thread Controlが512bit幅のSIMDエンジンを制御する、という部分は変化が無いことになる。一方XMXであるが、こちらはXe-HPGに搭載されているものと基本同じである(Photo10)。このXe2でXMXが復活した理由であるが、AI処理である。この後説明するNPUは勿論AI処理が可能であるが、Copilot+は兎も角として世の中のアプリケーションの中には、まだGPUのみを使ってAI処理を行うもの(例:Adobe Photoshop)が少なくない。AI PCを名乗る以上はこうしたものへの対処が必要であり、そのためにはXMXを実装しておく方が効果的と判断された様だ。実際IntelによればLunar LakeのGPUは67TOPSとされているが、その大半をXMXが担っているという訳だ(Photo11)。
-

Photo08: ひょっとしてPhoto04に出て来た"Less SW overhead"というのは、Vectorの幅を256bit→512bitにしたことで、同じ処理をより少ない命令で実行できる(可能性がある)という事だろうか?

-
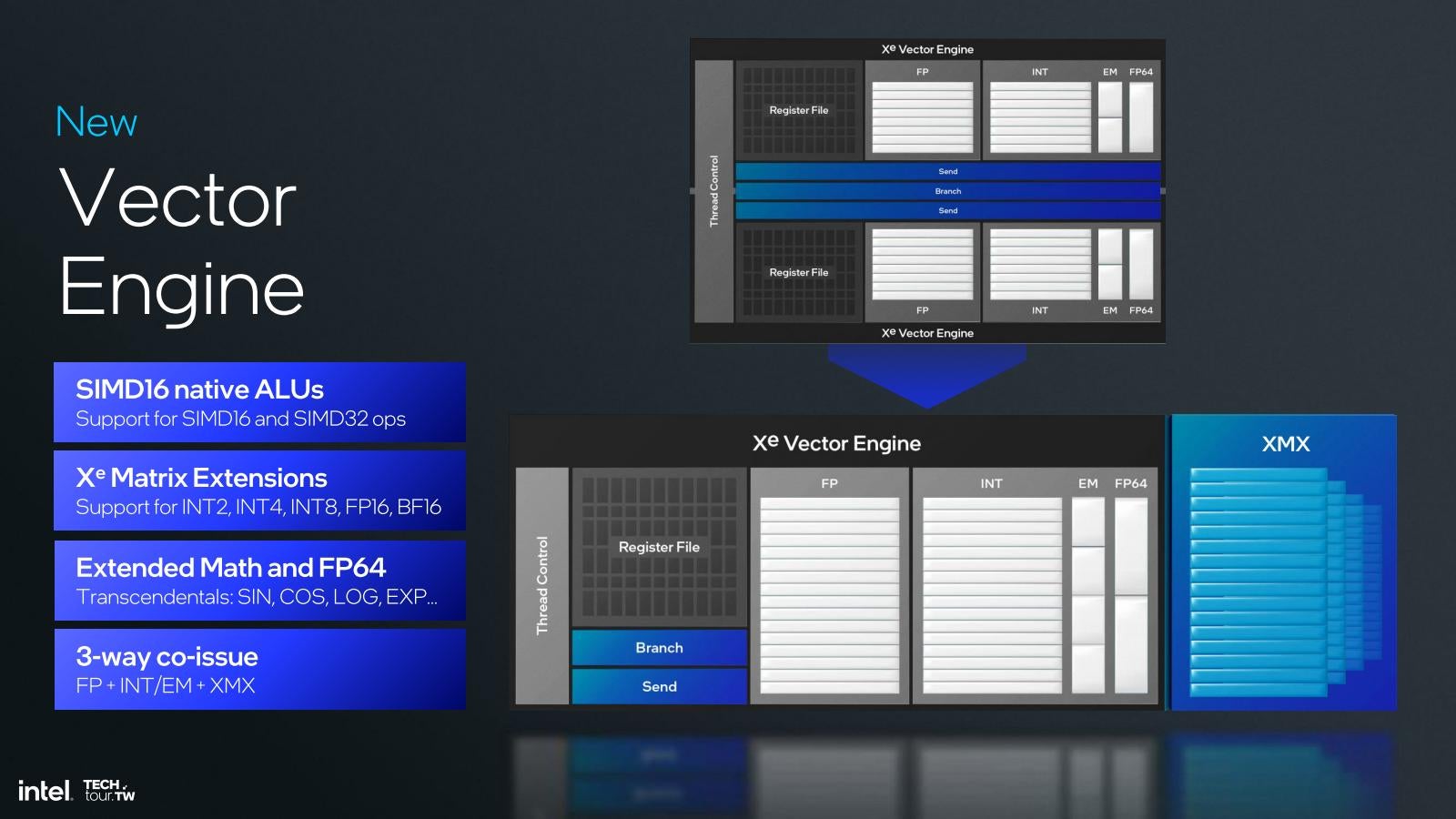
Photo09: ことVector Engineのサポートするデータ型などはXeと特に変わらない。3-way co-issueも従来でも可能だった。なので最大の違いは構造である。

-

Photo10: Xe-HPC、つまりPonte VecchioのXMXはこの倍のスループットであるが、流石に規模を考えるとそれを搭載するのは無理と判断されたようだ。

-
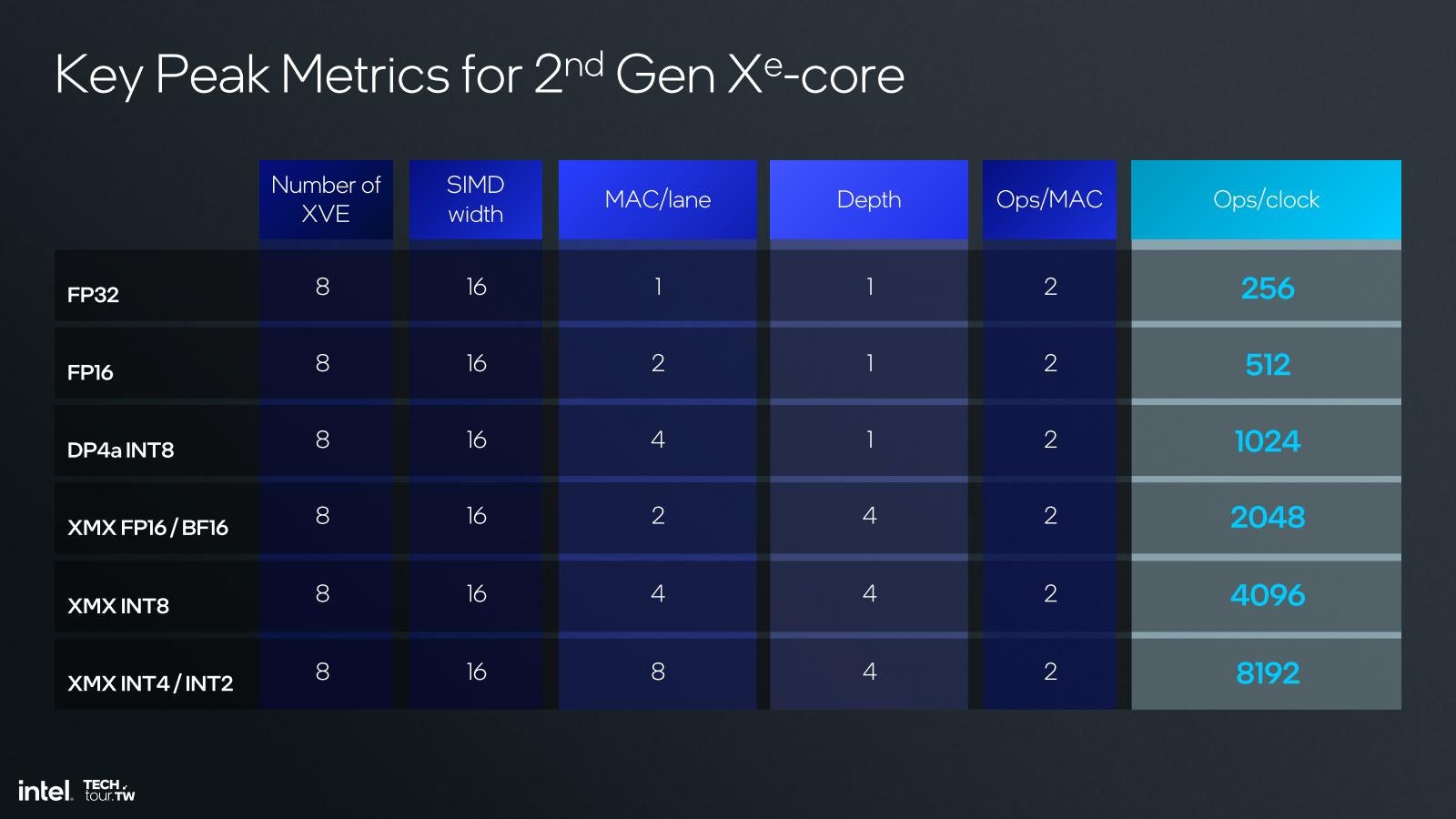
Photo11: INT 8の場合、1個のXe CoreあたりXMXが4096 Ops/cycle、Vector側がDP4aを1024 Ops/cycle、合計で5120 Ops/cycleとなり、これが1.63GHzほどで動作すると67TOPSとなる計算だ。

話を戻すとそんな訳でAI性能そのものはともかく描画性能の方の理論性能はXe-LPGから基本的には変化がないのがLunar LakeのXe2であるが、性能/消費電力比は大幅に向上しているとされる(Photo12)。ただ実際には、Meteor Lakeほどに動作周波数を上げる(TDP 45WのCore Ultra 9 185Hで2.35GHz、TDP 15WのCore Ultra 7 165ULで2GHz)だと、消費電力的に厳しい可能性がある。Photo11の脚注でも書いたが、動作周波数はIntelのAI性能の数字から考えると1.6GHz程度に抑えられているものと考えるのが妥当だろう。理由の一つは、仮にGPU性能を引き上げてもメモリ帯域が追い付かない事だ。ここでもまた、Memoryが64bitである事の制約が付きまとう格好になる。Core Ultra 9 185Hなみに動作周波数を上げることは不可能ではないだろうし、その際にも消費電力は低く抑えられるではあろうが、性能そのものはメモリネックになって期待できないだろう。だったら、メモリ帯域とバランスする辺りまで動作周波数を落とした方が賢明、という判断が下されたものと考えられる。
-
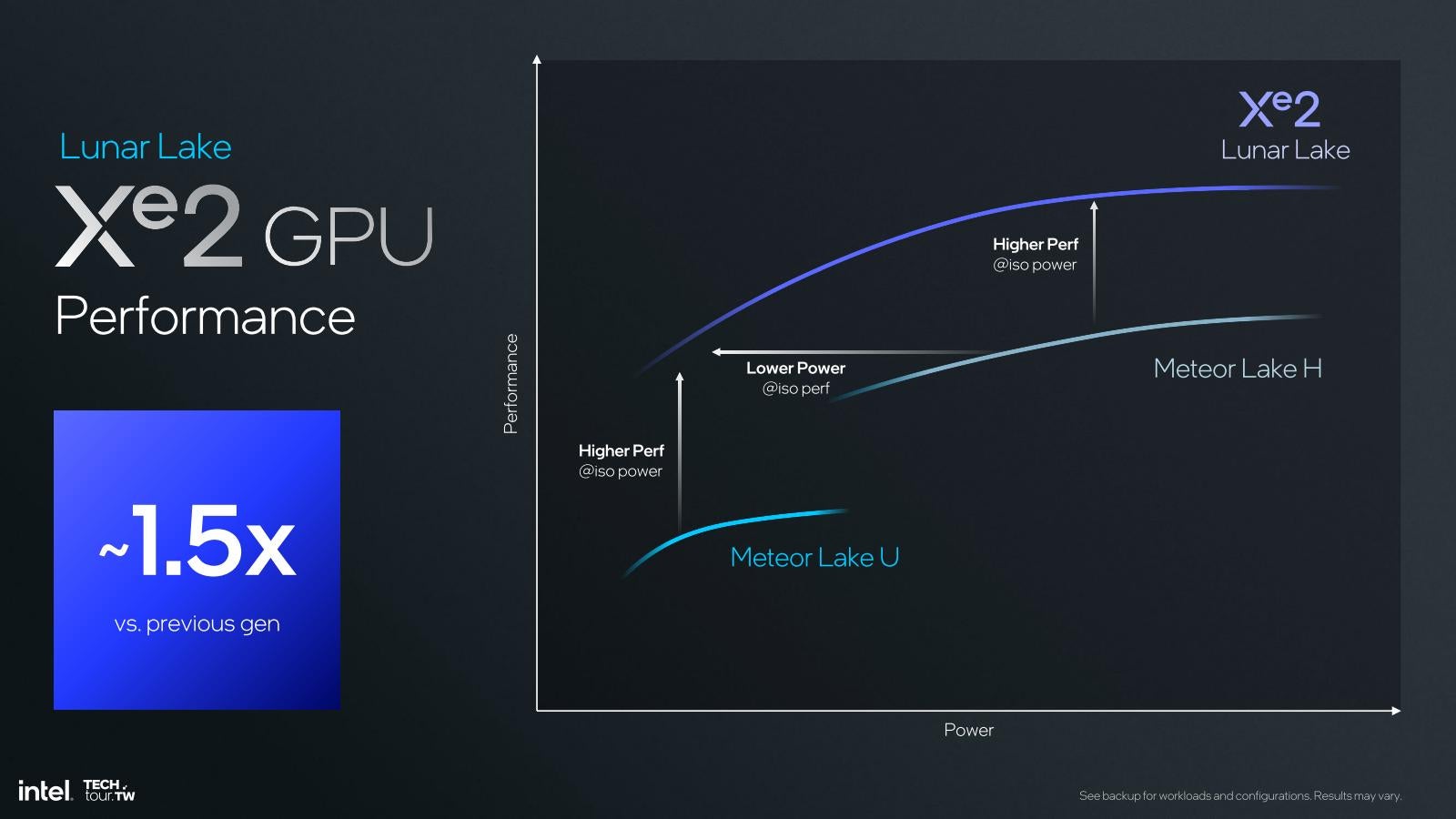
Photo12: ただこれは主にプロセスの微細化に起因するところが大きい様に思われる。Meteor LakeはTSMCのN5だったから、これをN3Bに変えたことが大きな比率を占めるだろう。

その他の改良点としては、Ray Tracing Unitの強化(Photo13)が挙げられる。Meteor LakeというかXe世代との構造の比較が無かったので、「どう強化されたのか」が今一つ説明しにくい(筆者の記憶ではTraversal Pipelineは1つだった気がする)のだが、COMPUTEXの会場ではF1 24を2Kで実行できる(F1 24はデフォルトでRay Tracingが有効化される)事が示された。もっともこれもよく聞いてみるとXeSSをフルに使っての話で、XeSS無しで2KはRay Tracing以前に描画が追い付かないようだ。
-

Photo13: BVHはBounding Volume Hierarchyの意味で、Ray Tracingの交差判定を高速化するための階層的なデータ構造を指す。この下でBox(右図で、ウサギの周囲を細かなBoxに分割しているのが判る)を処理できるTraversal Pipelineを3つ搭載しているのがわかる。

Media Engine周りではVVCのサポート(Photo14,15)が主な変更事項となる。またDisplay出力ではeDP 1.5への対応(Photo16)が追加事項となる。eDP 1.5ではPSR(Panel Side Refresh)の機能が搭載されており、これを利用して更なる省電力化が図れる、とする(Photo17)。
-

Photo14: VVCはH.266として標準化が完了しては居るのだが、こちらは特許が必要という事もあり、またAV1と比較してもそれほど大きな圧縮効率改善が期待できないという事もあってか、今のところ動きは鈍い。

-

Photo15: VVCをH/WとS/WそれぞれでDecodeしての比較。圧倒的にH/W Decodeの効率は良い。

-
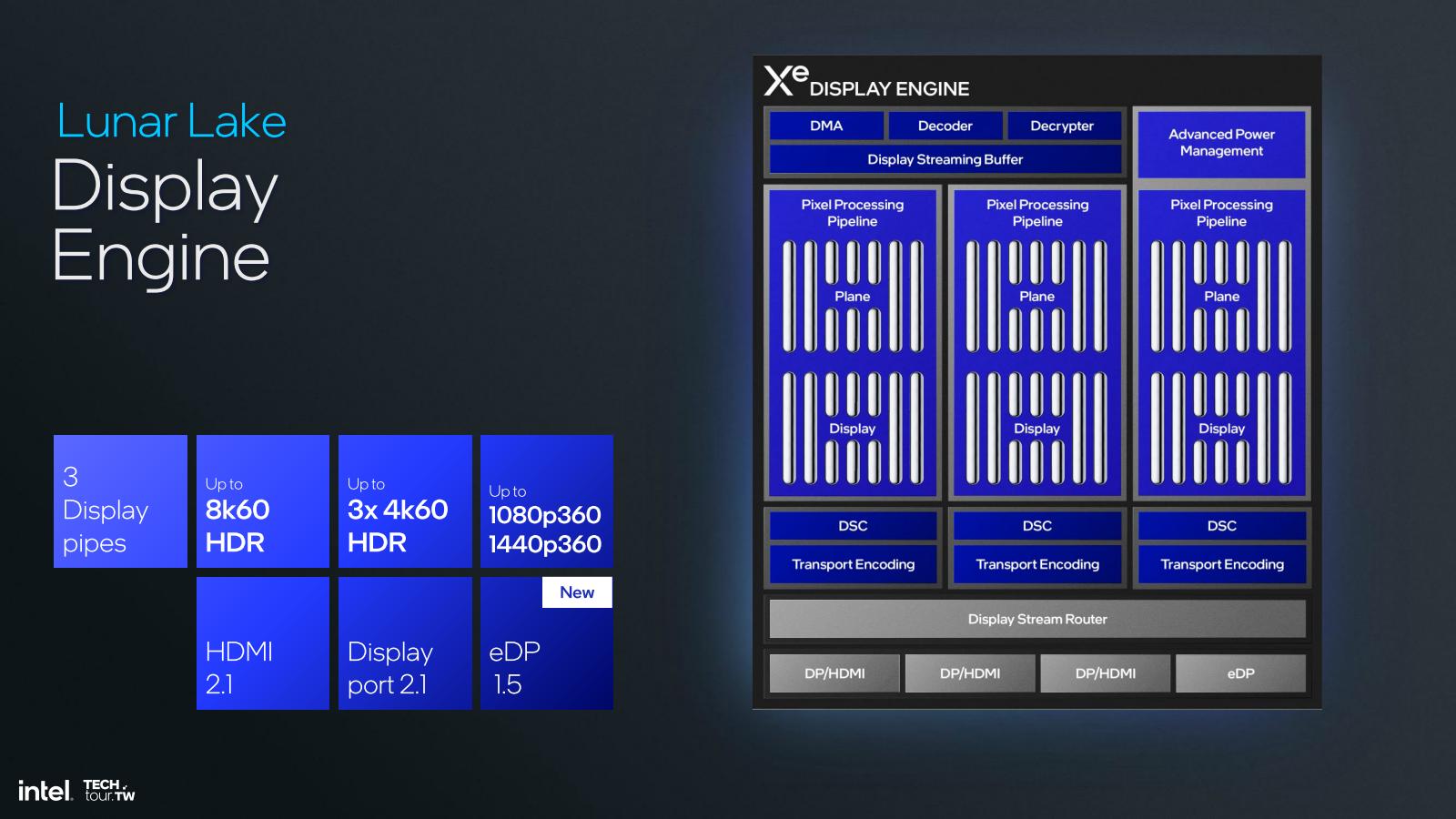
Photo16: 基本的なところはMeteor Lake世代と変わらない。

-
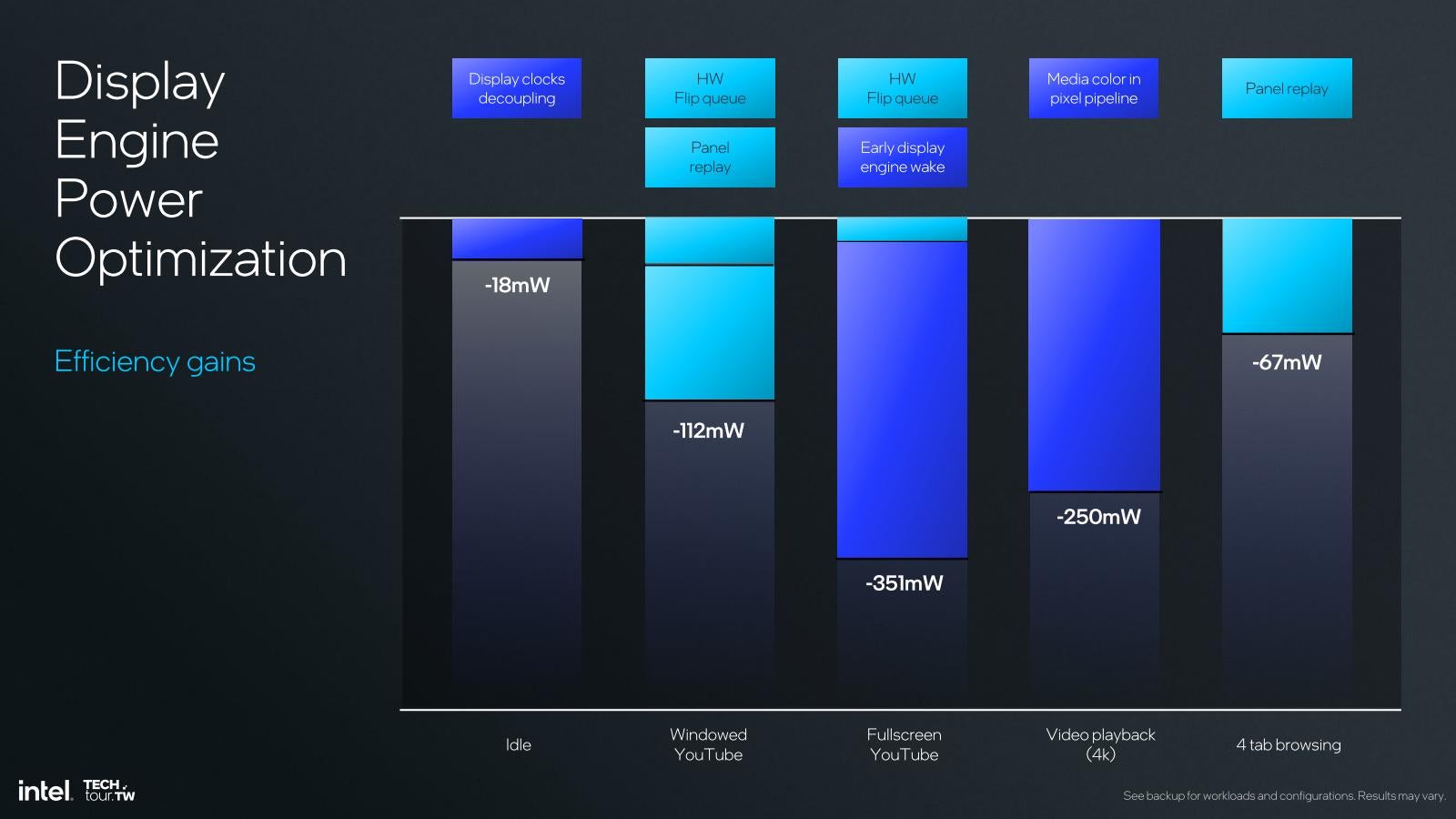
Photo17: 主要なUsage Modelにおける省電力の効果。You Tubeの全画面視聴なら351mWの削減というのは中々大きい数字である。

NPU
最後にNPUについて。IntelではMeteor Lake世代をNPU 3、Lunar Lake世代をNPU 4とする事にした様だが(Photo18)、まず大きな違いは内部のNCE(Neural Compute Engine)が3倍になった(Photo19)。また動作周波数の引き上げも行われている(Photo20)。後述するが、NPU 4では内部構造の改良もなされているが、これは性能向上というよりは効率改善がメインであり、大きく性能を引き上げるような工夫は特に見当たらない。なので純粋にコア数と動作周波数向上で、4倍の性能を実現したことになる。
-

Photo18: もとになったMovidiusのMyriadをGen 1、Myriad XをGen 2とすれば、確かにMeteor Lakeに入ったのはGen 3だし、今回はGen 4になる。

-

Photo19: これだとL2の容量が増えていない様に見えなくも無いが、正確な数字はまだ示されていない。とはいえ、恐らくL2も増量されているとは思う。

-
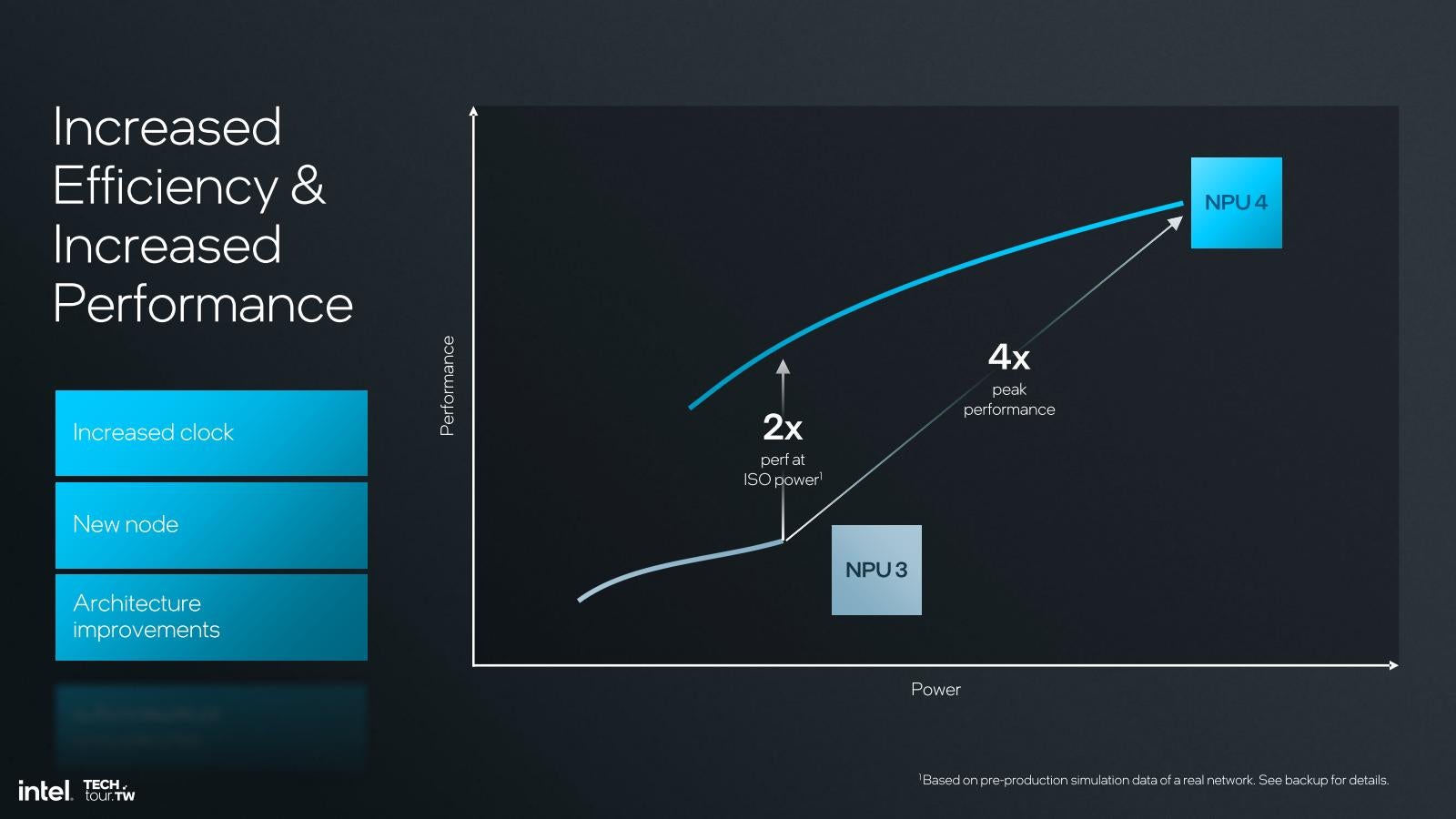
Photo20: NPU 3では1.4GHz駆動で11.5TOPS(理論性能)とされていた。NPU 4では48TOPSでほぼ4倍の性能ということになる。

Intel 3の11.5TOPSの根拠は、
2(Ops/MAC)×2048(MAC/Cycle/NCE)×2(NCE)×1.4GHz=11.4688TOPS≒11.5TOPS
というもので、同じように2048 MAC/cycleで2 Ops/MAC構成のNPU 4で48TOPSを実現しようとすると、動作周波数は1.709GHzほどになる。丸めて1.7GHzと仮定すると47.78TOPS程だが、これならまぁ48TOPSを名乗っても間違いとは言えないだろう。要するに動作周波数を1.4GHz→1.7GHzと21%ほど引き上げた格好だ。これが実現出来たのは、プロセスをGPU同様にN5からN3Bに移行した事が大きいだろう(3倍の規模の回路を押し込むことが出来たのも、同様にN3Bの効果があったものと思われる)。
内部構造に関しては、性能は兎も角MACユニットは(恐らくNPU 3と比較して)2倍の効率を実現したとしており(Photo22)、またShave DSPもVector Lengthが4倍に拡張されたそうだ(Photo23)。もっともShave DSPはMACユニットで扱えない処理をメインにしているので、ここが4倍高速になっても、全体の性能への寄与分はそれほど大きくないのだが。細かいところではDMA Engineの改良(帯域2倍)とか、Activate Functionの機能追加/改良(例えばReLUでFPをサポートできる様になったとか)などがある。こうした蓄積により、例えばStable Diffusionを実行した場合だとMeteor Lake比で性能が3.6倍、効率2.9倍になるとしている(Photo24)。
-

Photo21: こちらは実測ではなくシミュレーション上でのデータとの事。

-

Photo22: 12倍というのは、Shave DSPの数が3倍×Shave DSPの性能そのものが4倍なので、トータル12倍ということだそうだ。

-

Photo23: Tokenizationの機能はこれまでなかったもの。ただNCEの数が3倍という事を考えると、帯域2倍では足りないのでは? という気もする。

-
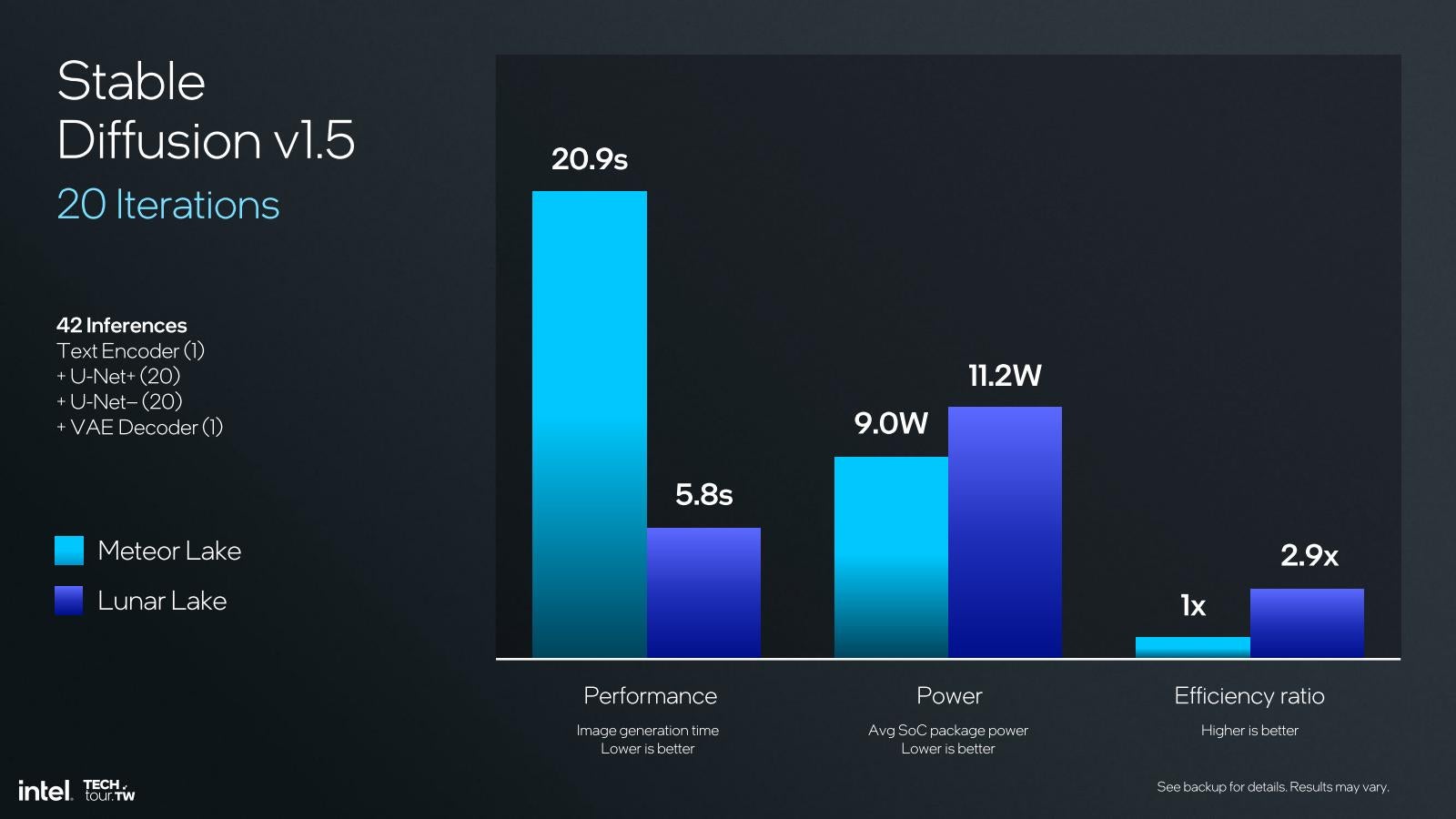
Photo24: 流石に効率化したとはいえ、回路規模3倍、動作周波数1.2倍だから消費電力が多少増えるのは仕方がない。むしろこの程度の増分で3.6倍の処理性能を発揮しているのは大したものだとも見れる。

ということで、ここまででCompute Tileの説明は終わり。Platform Controller Tileの話は別記事にて。









{kind=link}