



A64FXとSPARC64 XIfxの性能比較
A64FX CPUの性能であるが、京コンピュータに使われたSPARC64 XIfx CPUと比較すると、倍精度で行列積を計算するDGEMMでは2.5倍の性能、メモリバンド幅はStream Triadで840GB/s、流体力学計算で使われるCombined Gatherでは3倍、気象計算で性能に効くL1キャッシュのバンド幅では2.8倍、地震計算で効くL2キャッシュのバンド幅で3.4倍、マシンラーニングで使われる32bit浮動小数点数を使った畳み込み計算では2.5倍の性能になっている。
そして、京コンピュータのCPUは8bit 整数(INT8)の計算をサポートしていなかったので公平な比較ではないが、INT8で畳み込み計算を行う場合は9.4倍の性能が得られる。なお、これらの数値はA64FX CPUのクロックは1.8GHzで測定したものであり、クロックが上がればさらに性能が上がると思われる。
-

京コンピュータのSPARC64 XIfx CPUからの性能向上。DGEMMやStream Triadなどのベンチマークと流体、気象、地震などのアプリケーションで比較。上に付けた矢印で性能向上の主因を示している

A64FXの性能はどれくらいなのか?
次の図は姫野ベンチマークという非圧縮流体計算のカーネルの計算性能を比較したもので、京コンピュータの1CPUでは、20GFlopsの性能、24コア、2.7GHzクロックのXeon CPUの2ソケットサーバでは85GFlopsの性能であるが、2.2GHzクロックのA64FXは1CPUで385GFlopsと京コンピュータのCPUの約20倍の性能となっている。また、競合するNECのSX-Auroraは286GFlops、Tesla V100 GPUは305GFlopsであり、FX1000は、それらよりも3割程度高い性能を持っている。
-
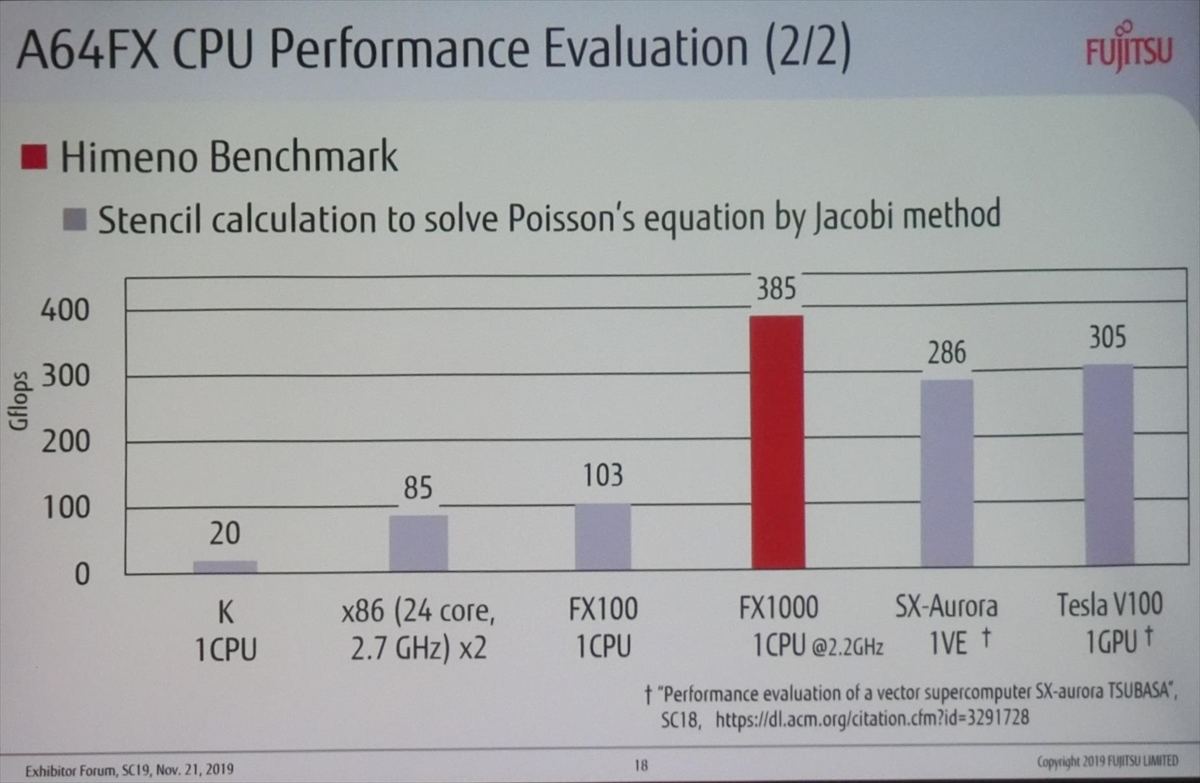
姫野ベンチマークによる各種のスパコンの計算エンジンの性能比較。FX1000のCPUは385GFlopsで、京コンピュータの約20倍。SX-AuroraやTesla V100 GPUと比較しても3割程度高い性能を持っている

次のグラフは、ToFu DインタコネクトでMPI_Send/Receiveを行った場合のレーテンシとバンド幅を示す。下の2本の折れ線グラフはスループットを示すグラフで、横軸はメッセージサイズである。富岳はメッセージサイズが小さい領域では京コンピュータの2倍程度のスループットを示し、1MBの大きなメッセージでは京コンピュータが4.8GB/s程度であるのに対して富岳は6.4GB/s程度となっている。
上の2本の折れ線グラフはMPIでピンポン通信を行ったときのレーテンシを示すもので小さいメッセージサイズでは、京コンピュータは1.3μs程度であるのに対して、富岳では1μs程度に短縮されている。そして、メッセージサイズが大きくなると、富岳の優位は増大していく。
-

ToFu DインタコネクトでMPI_Send/Receiveでピンポン通信を行った場合のレーテンシと通信バンド幅。京コンピュータと富岳の測定値が書かれている。上の2本の折れ線グラフはレーテンシ、下の2本の折れ線グラフはバンド幅で右側の縦軸を使う

次の図はMPIでブロードキャストを行った場合のバンド幅を示すグラフである。京コンピュータのToFuインタコネクトではデッドロックを避けるため+X、+Y、+Zの3方向に同時にデータを送っており、この3方向への通信の繰り返しで全ノードに同一データをブロードキャストしていた。これに対して、富岳のToFu Dでは同時に±X、±Y、±Zの6方向にデータを送るアルゴリズムを考案し、バンド幅を改善した。
右下の3つのグラフは、上から順に、富岳での6方向同時送信アルゴリズムを使った場合の性能、富岳のToFu Dインタコネクトで京コンピュータの3方向同時送信アルゴリズムを使った場合、京コンピュータのToFuインタコネクトのブロードキャストのバンド幅を示す。なお、ブロードキャストする範囲は384ノードとした測定の結果である。
100MBという大きいデータのブロードキャストでは、京コンピュータの場合は10GB/sを少し上回る程度であったが、富岳で6方向同時送信アルゴリズムを使った場合は36GB/sと3倍以上に性能が向上している。
-

富岳では6方向同時に送信してもデッドロックしないアルゴリズムを考案して、京コンピュータの場合の3倍以上のブロードキャストバンド幅を実現した

次の図は、各ノードの計算結果の合計を計算して、その結果を全ノードに送るMPI_Allreduceを384ノードで行った場合の所要時間を示すグラフである。右側のプロットの横軸はAllreduceを行うベクタの長さである。京コンピュータでベクタ長が2以上の場合は、Allreduceに50μs~60μsかかっているが、富岳ではToFu Barrier Interfaceを使った場合は、倍精度のFP64の場合は最大でも35μs程度で、ベクトル長が30以下の領域ではほぼベクトル長1当たり1μs程度の傾きになっている。ベクトル長が短い場合のAllreduce時間が大幅に短くなっており、性能に大きく効きそうである。
-

ToFu DのAllreduce性能。富岳と京コンピュータのインタコネクトでToFu Barrier Interface(TBI)の使用の有無の条件で測定を行っている。京コンピュータではTBIが1個であるので、ベクトル長が2以上になると50~60μsかかるが、富岳ではベクトル長が1増加すると1μs程度時間が増加し、最大でも30~40μs程度でAllreduceができる

OS Jitterを減らすため、Tickを使って処理を開始するやり方を使わないようにし、不必要なデーモンやサービスを止める。加えて富岳ではアシスタントコアにOSの割り込みやデーモンの実行をオフロードした。x86で普通のOSを使った場合はジッタ(タイミングノイズ)の観測された最大値は873μsであるが、京コンピュータの場合は85μsに減少させた。富岳ではこれをアシスタントコアの使用などで37μsに減少させている。これは観測されたジッタの最大値であるが、平均のノイズ比では、x86が3.7E-03であるのに対して、京コンピュータの場合は6.6E-5と2桁あまり減少しており、富岳では7.1E-7と京コンピュータからさらに2桁小さくなっている。
図の右側の散布図はオレンジがx86システムのノイズを示し、水色が富岳のジッタを示している。
-

多数のコアで並列実行する場合は、一番遅いコアの実行が終わるまで次の処理は開始できない。1つのコアにタイマ割り込みなどが入ると、そのコアだけ処理時間が長くなってしまう。これがジッタである。京コンピュータでは不要なデーモンなどを止めて、割り込みを減らしジッタを2桁あまり小さくした。富岳では、割り込みなどはアシスタントコアにオフロードして、計算コアの処理が影響されないようにして、ジッタを京コンピュータからさらに2桁低減した















