
Photo05がVega 20の構造図だ。これそのものは従来のVega 10と全く違いがない。NCUが16個ずつ組になってGraphics Pipelineを構成し、これが4組あるので合計64NCUとなる。さらに各々のNCUは、64個のSP(Stream Processor:Vector ALU)から構成されるので、トータルでは4096SPとなる。これもVega 10と全く同じである。
-
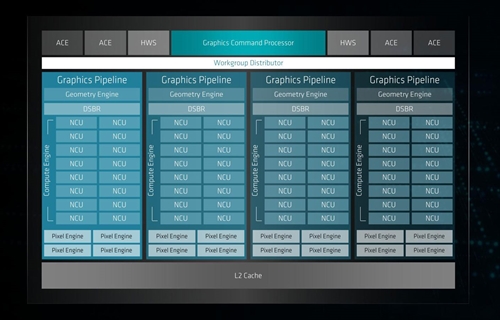
Photo05:ACEの数とかPixel Engineの数などもVega 10から変更なし

構成が変わらないので、ピーク性能そのものも、実はあまり変わらない。実際、Radeon Instinct MI25とMI60のページからスペック及び性能を抜き出すと
| GPU | Radeon Instinct MI25 | Radeon Instinct MI60 |
|---|---|---|
| 動作周波数 | 未公開(1500MHz) | 1800MHz |
| INT4 | N/A | 118TOPS |
| INT8 | N/A | 58.9TFLOPS |
| FP16 | 24.6TFLOPS | 29.5TFLOPS |
| FP32 | 12.29TFLOPS | 14.7TFLOPS |
| FP64 | 0.768TFLOPS | 7.4TFLOPS |
となっている(Int8の性能がTFLOPSになってるのは、本当にAMDのサイトでそう表記されているから、一応そのままとしたがTOPSが正しいと思う)。
-

Photo06:これはDGEMM(64bitのGEMM)での実測値なので、ピーク性能からやや数字が下がっている

Radeon Instinct MI25の公式ページでは、動作周波数が公表されていないが、定格:1,400MHz/Turbo:1,500MHzということで、1,500MHzとしている。
表を見てもらえばわかるが、要するにFP16とFP32に関しては、動作周波数の差がそのまま性能差になっている形だ。その意味では7nmプロセスを利用したことで消費電力を上げずに20%ほど動作周波数を引き上げられたといえる。逆に言えば、ことFP16/FP32に関しては動作周波数による性能差しかない。
大きく異なるのはFP64の扱いである。もともとVega 10のNCUはPhoto07の様に、各々のSPは32bitベースのVector ALUであるが、16bit×2という動作も可能である。ただし64bitは扱えないので、これはソフトウェアでエミュレーション動作を掛けることとなり、結果としてFP64では異様に性能が落ちていた。
-

Photo07:これはVega64のSPの構造

これがVega 20では、恐らくであるが2つのSPで1つのFP64を直接扱えるような改良が施された模様で、この結果としてFP64の性能がFP32の半分まで引き上げられることになった。
加えて言えば、ResNet50の画像認識速度は2.8倍になった(Photo08)とされるが、これは演算性能というよりも、HBM2の帯域と容量が倍になった効果の方が大きいと思われる。メモリ帯域がボトルネックになるような用途では、帯域の倍増がそのまま性能アップにつながる。
-

Photo08:テストはFP16で実施されている

INT8に関しては、Radeon Instinct MI25(というか、Vega 10)での数字が未公表だが、Vega 10の世代でQSAD/MQSAD(Quad Sum of aboslute differences)は、1CUあたり最大512個の8bit演算が可能となっている。この数字を使うと1500MHz駆動のVega 10なら49.2TOPS、1800MHz駆動のVega 20なら58.9TOPSのピーク性能を持つことになり、ここでの差はないと考えてよい。
より広範なINT8命令のサポート、という話はいまのところ出てきていない(やっても良さそうな気はするが)。ただしVega 20では新たにINT 4(4bit Integer)もサポートされることになった。こちらはINT 8を半分にすることで、1CUあたり1024個の演算が可能になる模様だ。さらにこのINT4/INT8/FP16/FP32/FP64を混在させての演算も可能(つまり型変換命令を大幅に増やした)という。
またHBCC(High Bandwidth Cache Controller)の構造も同じなので、例えばVega 20をベースにPCIe Switchを外付けして、Radeon SSDの様な構成を取る事も可能という話であった。








