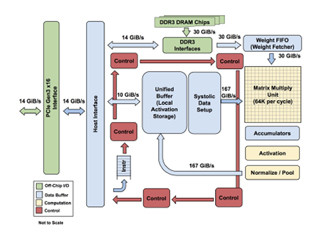
1台のサーバに4台のTPUで圧倒的処理性能を達成
AlphaGo Zeroは、まったく白紙の乱数で設定された重みの状態からスタートし、人間の介在なしで約3日間学習を行い、490万回の自己対局を行った。それぞれのMCTSでは1600回のシミュレーションを行い、一手の評価時間は約0.4秒である。
次の図は学習の様子を示すものである。aは、縦軸はElo Rating(イロレーティング)と呼ばれるプレーヤーの強さを表す数字である。イロレーティングは、200の差があるプレーヤーが対局した場合、レーティングの高い側のプレーヤーの勝率が約76%になるように作られている。
左端の図は、AlphaGo Zeroの自己対局だけの学習と棋譜を学ぶ学習を行った場合のイロレーティングの変化を示している。そして、破線の横線はAlphaGo Leeのイロレーティングである。
棋譜を学ぶ学習は短時間で急速に強くなっているが、イロレーティング3500程度で頭打ちになっている。AlphaGo Leeは数か月に渡って学習した結果であるが、自己対局による学習は36時間の自己対局学習でAlphaGo Leeに追いつき、それ以降は逆転している。
また、プレイにおいては、AlphaGo Leeは48台のTPUで分散処理を行っていたが、AlphaGo Zeroは1台のサーバに4台のTPUを接続した構成で処理できている。そして、AlphaGo ZeroとAlphaGo Leeは100回対局して、AlphaGo Zeroが100戦0敗という結果になっている。
図bはプロの選択した手との一致度を示すグラフで、棋譜を学習した場合は、立ち上がりが早く、到達度も高いが、自己対局による学習の場合は、プロの手との一致度は低いレベルである。図cはプロ棋士の対局の結果との誤差の二乗平均をプロットしたもので、棋譜学習を行った場合は、誤差は急速に小さくなるが、10数時間の学習で逆転し、自己対局学習のほうが誤差が小さくなっている。

|
|
横軸は学習時間で、自己対局による強化学習と棋譜の学習を行った場合の結果を比較している。図aは強さを表すイロレーティング、図bはプロ棋士の選んだ手との一致度、図cはプロ棋士の結果との二乗平均誤差をプロットしたものである |
次の図は、何が強さに効いているのかを分析するものであり、Value NetworkとPolicy Networkを独立に設けるAlphaGo Leeの構造と両者を一体にしたAlphaGo Zeroのネットワーク構造、そして、ネットワークをAlphaGo LeeのConvolutionネットワークとした場合とAlphaGo Zeroで採用したResidualネットワークにした場合を比較している。それぞれの図の4つの棒グラフは、左から、一体型Residualネットワーク、分離型Residualネットワーク、一体型Convolutionネットワーク、分離型Convolutionネットワークの結果である。
3つの図は、左から順にイロレーティング、プロ棋士の手との一致度、プロ棋士のプレイの結果との二乗平均誤差を示すものである。
図aを見ると、AlphaGo Leeで使った分離型Convolutionネットワークに比べて、一体型への変更とResidualネットワーク化の改善効果はほぼ同等で、イロレーティングを600程度改善している。そしてAlphaGo Zeroの一体型Residualネットワークにすることにより、さらに600程度イロレーティングを上げている。

|
|
どの変更が性能向上に効いているのかを調べるため、Policy NetworkとValue Networkを一体型としたものと分離型としたもの、さらにネットワークをConvolution型とResidual型としたものを作って比較した。aがイロレーティングで、一体化とResidual化が同程度の性能改善効果があることが分かる |
AlphaGo Zeroは、自己対局学習の過程で多くの定石を再発見したが、それに加えて多くのこれまでに知られていない定石となり得るものも発見しているのは興味深い。これはAlphaGo ZeroのMCTSのほうが、より棋譜を残したプロ棋士より広範にサーチしていることを示している。
AlphaGo Zeroの最終的な性能を求めるため、2900万回の自己対局を約40日間掛けて実行して学習を行った。この時のAlphaGo Zeroは40 Residual Blockを持つより精度の高い構成のものである。
次の図の左側のグラフは学習期間に対するイロレーティングの改善を示している。AlphaGo Zeroは5000イロレーティングを超え、40日間の学習でも、まだ、飽和していないようにみえる。
右側のグラフは、40日間の学習を行ったAlphaGo Zeroと他のバージョンのAlphaGoやその他の囲碁プログラムのイロレーティング性能を比較したものである。左から2番目の棒グラフがAlphaGo Zeroのイロレーティングで、5000を超えている。その右が順にAlphaGo Master、AlphaGo Lee、AlphaGo Fanで、その右がCrazy Stone、Pachi、GnuGoである

|
|
左のグラフは、40 Residual Blockのネットワークを持つAlphaGo Zeroの40日間の学習に伴うイロレーティングの改善を示す。右の棒グラフは、AlphaGo Zeroと、他の版のAlphaGoと代表的な囲碁ソフトのイロレーティングを示す |
同じ0.4秒の探索時間で手を求めるのに、AlphaGo Leeは48台のTPUを必要としたが、AlphaGo Zeroは4台のTPUでプレイができるようになっており、計算量がおおよそ1/12になっている。その原因をこの論文では論じていないが、イロレーティングの改善に貢献したPolicy NetworkとValue Networkの一体化とConvolution型からResidual型にネットワーク構造を変更することにより予測精度が改善し、MCTSの計算量が大幅に減っているのではないかと思われる。