情報通信研究機構(NICT)は、ニューラル機械翻訳での活用などに向けて、オール・ジャパンでさまざまな分野の翻訳データを集積する「翻訳バンク」の運用を開始したと発表した。

|
「翻訳バンク」のコンセプト |
「翻訳バンク」は、翻訳データを集積して自動翻訳技術に活用することで、自動翻訳技術で対応できる分野を広げるとともに、さらなる高精度化を実現するものだ。現在、総務省とNICTは、世界の「言葉の壁」をなくすことを目指すグローバルコミュニケーション計画を推進しており、その一環としてNICTは音声翻訳(VoiceTra)とテキスト翻訳(TexTra)の研究・開発・社会実装を進めている。
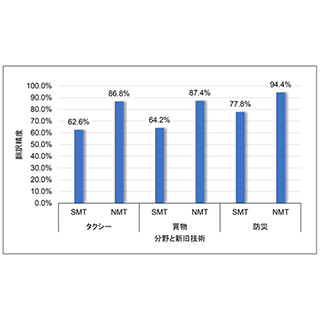
これまでNICTにおいては翻訳の高精度化に必要な翻訳データの集積に取り組むとともに、2017年6月からニューラル機械翻訳技術の導入などを進めているが、翻訳技術を活用する分野によっては翻訳データが足りないことが課題となっていた。
「翻訳バンク」の開始にあたり、データ提供者のメリットを明確化するため、NICTの自動翻訳技術の使用ライセンス料の算定の際に、提供が見込まれる翻訳データを勘案して負担を軽減する仕組みを導入することで、翻訳バンクにおける好循環モデルを構築し、皆で自動翻訳技術を育てながら、高性能な自動翻訳技術を活用していくサイクルを確立するという。2017年8月末現在は、29組織からデータ提供を受けており、当面の目標としては100万文×100社=1億文の翻訳データの集積を目指すということだ。