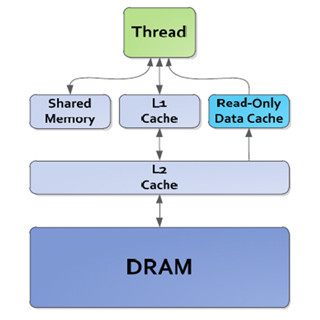
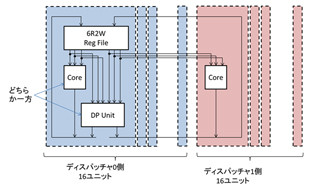
GPU DirectではRemote DMAをサポート
スパコンでは複数台のGPUを使うことが多い。この場合にはGPU間でデータを転送することが必要となる。Fermiでも同じPCI Expressに接続されたGPUとCPUのメモリ間のDMA転送を行うData Directは実現されていたが、GK110ではInfiniBandなどのネットワークを介して接続された計算ノードのGPU間でのRemote DMA(RDMA)がサポートされた。
転送経路のセットアップにはCPUが介入するものの、その後はGK110に内蔵したDMA機構が自分のGDDR5メモリからデータを読み、PCI Expressを経由してネットワークインタフェースカード(NIC)にDMA転送する。NICは、そのデータを相手方の計算ノードのNICに転送し、その計算ノードのGK110がNICからGDDR5メモリにDMA転送する。また、このDMA転送はNICだけでなく、ディスクなどの任意のPCI Expressデバイスとの間でデータをやり取りすることができる。

|
|
GK110ではネットワーク経由のリモートDMAがサポートされる |
FermiベースのTesla M2090を使う筑波大学のHA-PACSスパコンのTCAアクセラレータ部では、FPGAを使ってPEACH2というPCI Express間をブリッジしてリモートDMA転送を行う機構を開発しているが、GK110では同様な機能がネイティブでサポートされることになる。ただし、 PCI ExpressをブリッジするPEACH2の方がオーバヘッドが小さく、性能的には有利ではないかと思われる。
GK110で新たにサポートされたGPU利用率を改善するHyper-Q機構
Fermiでは、CPUからGPUに仕事を依頼し、それが終わると次の仕事を依頼するというコンセプトであり、1~4次元のスレッドの集合であるGrid単位で仕事を依頼するコマンドをバッファするキューは実質的に1本しかなかった。このため、CPU側のプロセスAからGPUに、Kernelと呼ぶCUDAプログラムのGridの実行を依頼するコマンドの列(これをStreamと呼ぶ)の実行が終わると、次のプロセスBからのStreamの実行が始まるという処理の流れになる。

|
|
1つのコマンドキューの場合のGPU使用率の時間変化の例 |
それぞれのKernelがGPUの全てのコアを有効に使用する場合は良いが、実際には上の図のように一部のコアだけを使用しているという場合が多い。
GK110で新設されたHyper-Qでは、このコマンドキューを32本に拡張している。そして、それぞれのキューの先頭から、コマンドを取り出し、必要な実行リソースがあれば並列に実行を開始する。その結果、次の図のように、最初にプロセスA、B、Cの最初のKernelが並列に実行でき、次にプロセスD、Eの最初のKernelが実行される。その次はAの2番目のKernelとFの最初のKernelというように実行されるので、それぞれのKernel単独のGPUコア利用率が低くても、全体としてGPUの利用率を高めて実行時間を短縮することができる。

|
|
Hyper-Qを持つGK110での実行状況の例 |
KernelからKernelを起動するDynamic Parallelism
GK110で新設された重要な機構がDynamic Parallelismである。これまでのGPUでは、CPUで1つのKernelを起動し、それが終わるとGPUから結果を受け取り、次のKernelを起動するという動作を行っていた。これはCUDAライブラリを呼び出す場合も同じで、CPUプログラムからしか呼び出しができなかった。
スパコンのベンチマークで有名なLINPACKの計算では、線形代数のcuBlasというライブラリの内の何個かの関数を順に呼び出す必要があるが、CPUが1つのライブラリの実行を指令し、それが終わったことを確認して次のライブラリを起動するのはオーバヘッドが大きい。これはライブラリの呼び出しだけでなく、一連のKernelを実行するStreamの場合でも同様である。

|
|
従来のCPUから個別にKernelの実行を指令するモデル(左)とGK110でサポートされたKernelから他のKernelやライブラリを呼び出すDynamic Parallelismのモデル(右) |
これに対して、GK110ではGPUで実行されるKernelから他のKernelやライブラリをCPUの介在なしに直接呼び出すDynamic Parallelismという機構を導入した。これにより、右側の図のようにCPUの介在なしに次々とKernelを実行することができるようになった。
このようにGPUで実行するKernelの中から次に実行するKernelがコントロールできるようになると大きなメリットがある。

|
|
マンデルブローの計算では、現在のCUDA(左)では各点を1スレッドとして計算する必要があるが、Dynamic Parallelismを使うと必要な部分だけを細かく計算できる(右) |
この図はマンデルブロー図形の計算の例であるが、従来のCUDAでは必要な解像度で画面の全ての部分を1スレッドとして計算を行う必要があり、右の図の一番細かいメッシュで全域を覆い全部の点を計算する2次元のGridを実行することになる。しかし、Dynamic ParallelismをサポートしたCUDAでは、先ず、粗い解像度のメッシュで計算するKernelを動かし、GPUがその結果を見て、図形のあるメッシュだけでその中を細分化したメッシュで計算するKernelを起動し、図形が無い部分では子供のKernelは起動しないということが可能になる。このような処理を繰り返すと、右側の図のように、細かい分割が必要な部分だけ細かく計算すればよく、均一な細かいメッシュでの処理と比べて計算する点の数を大幅に減らすことができる。
実際の科学技術計算でも良く使われるAdaptive Meshという方法では、高精度が必要な部分だけ分割を細かくしていくという計算法が使われており、Dynamic Parallelismを使うとデータ依存のKernel起動ができるので計算量を減らすことができる。また、CPUも、GPUとのやり取りの頻度が減少して負荷が軽くなり、他の仕事ができるようになる。
FermiではKernelを起動するのはCPUだけであったので、CPUからのStreamを見て、実行開始できるKernelを選択すればよかったが、GK110のDynamic Parallelismに対応するにはGPU内部から起動されるKernelにも対応が必要となる。このため、内部から発生するKernel実行要求を含めて、数1000のグリッドの管理を行うGrid Management Unitが追加されている。

|
|
Dynamic ParallelismではGPU内部からKernelが起動されるのでGrid Management Unitが追加された |
また、従来のCUDAではそれぞれのKernelプログラムを個別のファイルに書く必要があった。このため、本来、Streamとして実行される一連の処理でも多数のファイルに分かれてしまいプログラムの見通しが悪くなっていた。Dynamic Parallelism対応のCUDAでは一連のKernelを1つのファイルに書くことが可能になり、リンカー相当の機能がメモリ割り付けや相互参照を解決してくれるようになり、一般的なC言語のプログラムの記述性に近付いた。