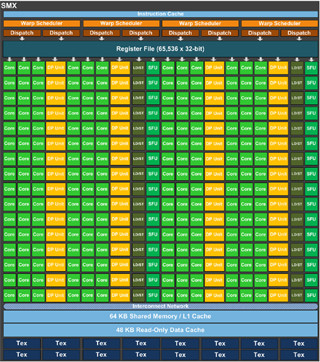
GK110のメモリ階層
GK110のメモリ階層は次の図のようになっている。このメモリ階層は従来のFermiとほぼ同じであるが、Read Only Data Cacheが追加されている点が新しい。

|
|
Keplerのメモリ階層 |
テクスチャキャッシュをRead Only Data Cacheに転用
グラフィックスの描画では、例えば、森の近景ではそれぞれの木を描く必要があるが、遠景では適当な緑の濃淡のある壁紙で代用すれば、描画のための計算が大幅に省略できる。グラフィックスでは壁紙は多用されるので、これを格納する専用のテクスチャキャッシュが設けられている。壁紙の模様は一定であり、書き直す必要はないので、テクスチャキャッシュはRead Onlyのキャッシュとなっている。
しかし、壁紙の模様は一定でも、壁紙を貼った面までの距離による拡大縮小や、その面を斜めから見た場合の見え方に対処するために、壁紙の模様の変形を必要とする。この変形を行うのがテクスチャユニットである。

|
|
Keplerでは、テクスチャキャッシュからレジスタファイルにバイパスを新設 |
壁紙のこのような変形を行うため、これまでのGPUではテクスチャキャッシュとレジスタファイルの間にテクスチャユニットが入っていた。標準の距離で正面から見るという設定とすれば変形無しにテクスチャユニットを通過するので、テクスチャキャッシュを通常のRead Onlyのキャッシュとして使用することも可能であるが、テクスチャユニットの通過時間の分だけアクセスが遅くなってしまう。このため、Keplerではテクスチャユニットをバイパスするパスが新設され、通常のロード、ストア命令でアクセスできるようになった。そして、テクスチャキャッシュはRead Only Data Cacheという名前に変わった。
定数を多く使っているプログラムでは、それらをRead Only Data Cacheに移すことにより、L1キャッシュやシェアードメモリをより有効に使うことができるようになる。使い方は、CUDAプログラムの中でconst __restrict属性を付けて定数を宣言すると、この48KBのRead Onlyデータキャッシュに割り付けられる。

|
|
const __restrict属性の使用例 |
L1キャッシュとシェアードメモリはバンド幅を倍増
Keplerでも、L1キャッシュとシェアードメモリは1個の64KBのメモリアレイを分割して使用するのはFermiと同じである。Fermiでは16KBと48KBという分割しか出来ず、Fermi以前の製品と同じ16KBをシェアードメモリに割り当て、残りの48KBをFermiで新設したL1キャッシュとして使用するのが一般的であったが、Keplerでは32KB/32KBの分割も可能となった。
また、SMXのコア数が増えたことからシェアードメモリ/L1キャッシュへのアクセスも増えるので、レジスタファイルとの転送パスを256ビット幅に倍増し、64bit以上のデータのロード命令では、Fermiと比べてキャッシュのデータ転送バンド幅を倍増している。
L2キャッシュもバス幅を拡張
GPUのL2キャッシュの構造はCPUのキャッシュとは異なる。マルチコアCPUでは一般にCPUコアとメモリ直前のキャッシュ(LLC:Last Level Cache)ブロックのペアを単位として、これを並べる。しかし、DRAMメモリとLLCのブロックの対応はなく、どのメモリの内容でもどのLLCブロックにも入るようになっている。
一方、GPUのL2キャッシュはGDDRメモリチップと1対1に対応し、自分が属しているメモリコントローラに繋がっているGDDRメモリのデータだけを格納するメモリキャッシュという構造になっている。

|
|
GK110チップのL2キャッシュとGDDR5メモリの接続 |
そして、L2キャッシュブロックとクロスバの間のバンド幅はFermiの384bit幅から512bit幅に強化されている。そして、この部分は倍速クロックを使っていないので、FermiアーキテクチャのGF110の772MHzとGK104を使うK10の745MHzのクロックの違いを含めると1.3倍程度のバンド幅となっている。
なお、GK110でも表示用のフレームバッファメモリにビットイメージを書き込むラスターエンジンは持っていると思われるが、全体構成図に描かれていないので、この図でも省略している。