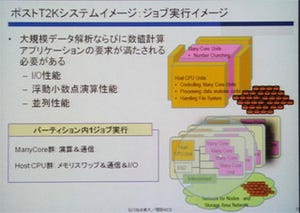
|
|
隣接計算ノード間での往復通信性能の測定結果 |
このグラフはMPI(Message Passing Interface)通信ライブラリを使って隣接ノード間で往復(ピンポン)の通信を行った場合のメッセージ長と転送速度の関係を示すものである。短いメッセージでは色々な通信オーバヘッドが入るので、当然、転送速度は遅いが、1MBかそれ以上のサイズのメッセージでは4.75GB/sの転送速度が得られている。計算ノード間をつなぐTofuインタコネクトの1方向のピークデータ伝送バンド幅は5GB/sであるので、その性能をほぼフルに利用できていることを示している。
また、FFT(高速フーリエ変換)などの処理では、各ノードの処理結果を他の全部のノードに転送するAlltoAllという転送が必要になる。次の図は、このAlltoAll通信の性能を理論限界性能に対するパーセンテージで示したものである。

|
|
京コンピュータのAlltoAll通信性能の測定結果 |
AlltoAllは、すべてのノード間で通信が行われ、Tofuのようなバケツリレーで送るネットワークでは混雑渋滞が発生しやすい。このため、青線で示された従来の転送アルゴリズムではメッセージサイズを大きくしても理論限界の50%程度で頭打ちであり、メッセージサイズが10KB程度では性能が低下してしまっている。
京スパコンでは、Tofuインタコネクトの接続構造で渋滞が発生しないように伝送方法を工夫した2つの新規アルゴリズムを開発した。一方のアルゴリズムは、サイズが大きいメッセージでは理論限界の90%を超える性能を実現し、もう1つのアルゴリズムは67%で飽和するが、100KB以下のサイズのメッセージでは、前者のアルゴリズムより高い性能を実現できる。
データ伝送を行う場合はメッセージのサイズは分かっているので、京スパコンでは、サイズに応じて最適なアルゴリズムを選択するという方法で、高い効率を実現している。現在も通信アルゴリズムのチューニングは続けられており、このデータは中間結果であるという。
スパコンでは、多数の計算ノードで分担して計算処理を行い、全部の計算ノードの処理が終わったことを確認して、その結果を使う次の計算を始めるというようなケースが多く存在する。この、全部の計算ノードの終了を待ち合わせるのがバリアという機能である。この場合、各計算ノードは他のすべての計算ノードに自分の終了を伝え、各計算ノードは、他のすべての計算ノードからの終了メッセージの受け取りを確認するというのが1つのやり方であるが、終了の確認をツリー状にまとめて行くとより効率的に処理できる。
また、AllReduceは、全計算ノードの処理結果の合計を取り、その結果を全部の計算ノードに送るというような処理であり、これもバリアと同じようなパターンの通信が必要となる。

|
|
バリアとAllReduce処理の所要時間の測定結果 |
このような通信の処理時間であるが、1万8000ノード以下の場合、待ち合わせを行うMPIのバリア処理や全ノードの8バイトのデータの合計を求めるAllReduce処理では、通常の通信機能だけを使ってソフトウェアで行うと60~90μsかかるが、Tofuインタコネクトの専用のハードウェアアシストを使うことにより15μs程度という結果が得られている。この傾向を延長すると9万ノードに近い京スパコンのフルシステムでも20μs以下で処理ができると考えられる。
このような通信を行っている間は、計算ノードは次の処理を始められず、ムダな空き時間になってしまうので、この部分の処理時間短縮は非常に重要である。