ところでこのRing廻りについてもう1つ。Photo04は同じレイアウトだが、Display ControllerそのものがGPUではなくSystem Agentに置かれているのが判る。普通に考えればDisplay ControllerはGPUの傍に置くのが正しい。この理由は塩田氏のレポートにもあるように、Display ControllerをGPU内に設けると、DisplayのRefreshのために、定期的にMain Memoryにアクセスを行うトラフィックがRing Busを経由することになり、これによるRing Busの実質的なThroughput低下、ひいてはSystem全体のPerformance Downを引き起こすことになる。これを避けるために、Display ControllerのみはSystem Agent内に置くことで、DisplayのRefreshに必要なMemory AccessのトラフィックはRing Busを介さないように配慮したという話である。

|
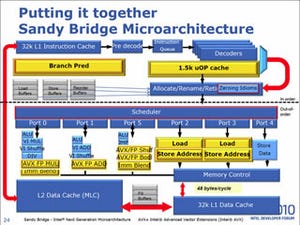
Photo04: いたる所で出てくるOverview。問題になっているのはコア上側のSystem Agentの中の左下、紫色の部分である。 |
一見これはスマートなのだが、その代償としてGPUからMemoryをアクセスするのに、2コアでも6cycle、4コアならば10cycleの余分なレイテンシが入ることになってしまっている。普通に考えればこれも図6の様な構造にすれば大分カバーできる筈であり、こうできないどんな理由があったのか、もまた気になるところだ。

|
図6 |
ついでに言えば、Intelの示したプレゼンテーションの中には、LLCからGPUにデータがコピーされる、というものがあった。実はこれは非常に意味深である。単にGPUがMemoryからのReadを掛ける際に、それがどこかのLLCに入っている場合はLLCから取り込む、というだけの話であれば問題はないのだが、逆にGPUからLLCに対して書き込みも出来る、という話だとすると、これはGPUコアがLLCとのCache Coherencyを利用できるという話になる。が、今のところそうした話は無い。Cache Coherencyについてはこんな説明(Photo05)があり、少なくともCPUとGPUの間にCache Coherencyが成立しているように見えない。またIntelがRing Busの動作として示す例でも、あくまでキャッシュから読み込むケースだけに限られており、それもGlobal Observationだと但し書きがついているあたり、無駄にGPUがSystem Agentから遠く離れ、間にLLCを挟む必然性が良く判らない。やはり現状のSystem Agentの物理的な実装に制約があり、その向こうには別のモジュールを置けない(つまりダイ上で一番端に置かないといけない)という事で、なので図6とか図5の実装が不可能、という話なのかもしれない。

|
Photo05: 可能性としては、LLCの一部がGraphics Cacheとして使われるケースで、そうした場合にはGPUとその一部の間でCoherencyが保たれることになるが、そんな贅沢な使い方が現実問題として許されるのか謎である。 |