前回までの記事で、秀丸上で使用できる基本的な正規表現(メタ文字)を紹介し終えました。本来はエスケープ文字やパターンの繰り返し、前方一致なども含める予定でしたが、それらは具体例で使用する際、個別に紹介しますのでご了承ください。
すべての全角英数字を検出する
さて、よく初心者がやってしまいがちなのが、文書に全角と半角を混合して書いてしまうアンバランスな文書です。一方の英単語は半角、もう一方の英単語は全角となりますと、文書全体の見栄えが悪くなってしまいます。また、Webなどインターネット上に公開する文書やHTMLはもちろん、会社へ提出するレポートなどでも、全角・半角が混ざった文書は決して見やすくありません。そこで、すべての全角文字を検出する正規表現を紹介します。
正規表現
検索:[0-9A-Za-z]
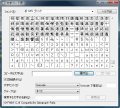
検索を実行するときは、検索ダイアログの[検索文字列を強調]にチェックを入れておきましょう。初期状態では、マッチした全角英数字がハイライト表示されます(図1、2)。これに全角スペースを加えるときは、「□0-9A-Za-z」とし、記号類を追加する場合は「!?0-9A-Za-z]」としてください。また、逆に半角英字数をピックアップする場合は「[0-9A-Za-z]」と、ブラケットで囲んだ英数字をすべて半角にしましょう。
 |
 |
図1 検索ダイアログの[検索文字列を強調]にチェックを入れてから、正規表現による検索を行なってください |
図2 これでマッチした全角英数字がハイライト表示されます |
一見すると置換も簡単なように見えますが、テキストエディタの場合、ブラケットで検索対象となる範囲を広げることは可能でも、そのマッチした部分を対になる文字に変換することは非常に難しくなります。マクロを使うのが一般的ですが、秀丸自身の機能として、英数字を半角もしくは全角にする変換機能が備わっていますので、そちらを使った方がスマートでしょう(図3、4)。
 |
 |
図3 [編集]メニューから[変換]→[英数字のみ半角に]を選択します |
図4 これで英数字がすべて半角に変換されました |
しかし、このままでは面白くありません。そこで、すべての全角英数文字を検出し、編集しやすいようにするため、前後に「★」マークを付ける正規表現を紹介します。
正規表現
検索:[0-9A-Za-z]+
置換:★\0★
これで英数字の前後に「★」マークが付いたため、手直しがしやすくなりました。ポイントは正規表現の末尾に付けた、直前の文字列が1回以上の繰り返すことを示す「+(プラス)」。検索文字列として「[0-9A-Za-z]」を指定しますと、全角英数字一文字ずつにマッチしてしまうため、「★0★1★」と置換されてしまいます。
そのため「+」を付けることで、"全角英数字が1回以上続く文字列"のみ検索対象とし、マッチした文字列自体を指すタグ付き正規表現「\0」を「★」で囲んだ置換文字列を与えてやれば良い、ということになります(図5)。
 |
図5 検索文字列を「[0-9A-Za-z]+」、置換文字列を「★\0★」とすることで、文書中の全角英数字が「★」で囲まれます |
ちなみにシフトJISの場合「0」は0x824F、「z」は0x829Aと続けて配置されているため、「[0-z]」と書いても間違いではありません。しかし、正規表現の可読性を損なわないため、「[0-9A-Za-z]」という表記をお勧めします。ただし半角英数字の場合、数字の後には「;<=>」といった記号が含まれるため、「[0-9A-Za-z]」と表記しなければなりません。含まれる記号に関しては、Windows OS付属の「文字コード表」をご参照ください。