


6ワークロード データレイク編 【2】クラスメソッド
DXが声高に叫ばれる昨今、デジタル化された業務の結果、生成されるデータをいかにして活用するかが企業の命運を分けるようになってきた。ここ十数年を振り返ると、突如として量も形式も増えたデータに翻弄されることも少なくなかったが、その間にビッグデータを味方につけようと工夫がこらされた技術の一つがデータレイクである。今回は、Snowflakeのサービスパートナーであり、各種先端技術ブログでも有名なクラスメソッド株式会社でデータアナリティクス事業本部 プリセールスアーキテクトとして活躍しており、個人としてもこのテクノロジーの歴史をつぶさに見つめてきた甲木 洋介氏に、過去から紐解くデータレイクと、未来を担うSnowflakeの役割をご紹介いただこう。
解説者:クラスメソッド株式会社 データアナリティクス事業本部 プリセールスアーキテクト
甲木 洋介氏
Twitter:@yokatsuki
はじめに
データ分析の世界において「データレイク」という概念が登場してから10年程になります。弊社クラスメソッドのデータアナリティクス事業本部は、企業様が持つデータ分析のためのクラウド基盤作りや機械学習の推進など、ビジネス加速の支援に取り組んでいます。第5回目の今回は、データ分析基盤を構築するプリセールス活動の中で、個人的視野で捉えたデータレイクの登場と進化の歴史的な流れをまとめ、データレイクの未来の姿を考えます。
データレイクのはじまり
既存データウェアハウスに対する課題
データレイク登場よりも前、1990年代にはデータウェアハウスという概念が既に実装された製品と共に存在していました。日々発生する業務データを管理している基幹システムから、業務分析に必要なデータを抽出し、分析に適した形に加工・集約されたデータの全体、およびそのデータを管理するシステムのことを当時から「データウェアハウス(DWH)」と呼んでいます。 データウェアハウス(ここでは分析用データ全体の意味)から、固定レポートやダッシュボード表示のために、あるいは分析操作を高速化する目的で、分析用途ごとの集約・集計データを作成することがあります。この集約・集計データを「データマート」あるいは「キューブ」と呼んでいます。 これら「データウェアハウス」「データマート」「キューブ」等のデータを、分析のためのソフトウェアやExcelの分析機能を使って分析することで、経営判断のために必要な情報を得る、という流れは現在も多くの企業に採用されています。
しかしデータウェアハウスには、いくつかの解決すべき課題がありました。
課題1:大量のデータが扱えない
既存のデータウェアハウスは、サーバールームやデータセンターに配置したサーバマシン、いわゆるオンプレ環境に構築することが普通でした。そのためストレージサイズ変更に柔軟性がなく、「過去13カ月のデータで分析していたところを3年にしたい、また新規に構築された別システムで発生するデータも分析対象にしたい」などの初期設計時以降に追加される要件に対応することができませんでした。もちろん、最近扱われるようになってきたセンサーデータ等も量が膨大になるので、従来のデータウェアハウスでは取り扱いが難しいものでした。 当時の対応策として、分析対象のシステムを管理可能な規模にグループ分けしてそれぞれにデータウェアハウスを立てる等の手段が取られたのですが、それはシステムやデータの分断(サイロ化)が避けられない、ということを意味していました。課題2:分析対象のデータが限定される
データ分析の一つの理想的な流れは、以下のサイクルをできるだけ速く多く回すことです。● 仮説を立てる
● 検証のためのデータを集める
● 集めたデータを使って検証する
● 検証結果から新たな仮説を立てる
これを実現するためには、仮説を立ててから分析に必要となるデータを揃えるまでの時間をできるだけ短縮する必要があります。しかし既存のデータウェアハウスで新たなデータを格納するためには、あらかじめデータの設計が必要でした。そのため、データを格納するまでに時間がかかり、分析サイクルのスピードを上げることができませんでした。
この課題の解決のために「安いコストで柔軟に容量確保が可能」かつ「事前設計不要ですぐに保存開始が可能」なデータの蓄積場所が必要となってきました。この必要性を満たすデータの蓄積場所が実現できれば、諸般の事情で今までは廃棄していた「もしかしたら分析に使えるかもしれない」レベルのデータもあらかじめ蓄積できるようになるのでは、との期待が生まれました。
データレイクの登場
「データレイク」という言葉が登場したのは2010年頃のようです。2010年10月、データ統合ツール等のベンダーPentaho社のCTOであるJames Dixon氏が、自身のブログにおいてデータマートと比較する形でデータレイクの概念について言及しています。
参考:Pentaho, Hadoop, and Data Lakes | James Dixon’s Blog
この頃のデータレイクの実現イメージは、現在のデータレイクのようなオブジェクトストレージではなく、当時「ビッグデータ」や「NoSQL」という単語と共に注目されていたデータ分散処理技術”Hadoop”を使った基盤で構成するというものでした。データを複数のサーバマシンで処理することで、1台では抱えきれなかった膨大なデータを高速で処理できるようになりました。またJSONなどの半構造化データも柔軟に扱うことができるため、データレイクの基盤として注目されるようになりました。
しかし、このHadoop基盤を使ったデータレイクは、爆発的な普及までには至りませんでした。なぜならば、2010年代はGoogle CloudやAmazon Web Services、Microsoft Azureなどのパブリッククラウドサービスが広く普及し始めた時期です。そこで提供されるようになったGoogle Cloud Storage(GCS)、Amazon Simple Storage Service(S3)、Azure Blob Storageなどのオブジェクトストレージサービスが、データレイク実現の手段として広がりを見せたのです。 パブリッククラウドのオブジェクトストレージサービスは、先に述べた「安いコストで柔軟に容量確保が可能」かつ「事前設計不要ですぐに保存開始が可能」なデータの蓄積場所をまさに実現できるものでした。また、「オブジェクト」ストレージサービスは、構造化データを格納したCSVファイル、半構造化データを格納したJSON、XMLファイルに加えて動画、音声などの非構造化データも格納できます。そこで「パブリッククラウドのオブジェクトストレージサービスでデータレイクを作り、とにかく何でもデータレイクに入れれば、データ分析の問題は全て解決する」と考えられるようになりました。
こうして、Amazon S3などのパブリッククラウドのオブジェクトストレージサービスにあらゆるデータを格納・蓄積する機運が生まれました。
● 構造化データ以外の半構造化データ、非構造化データ
● 年単位の長期間にわたる履歴データ
● 将来分析に使用する可能性のあるデータ
● 未加工、未集計の生データ
これが今日も続くデータレイク普及のきっかけになります。
初期のデータレイクに対する反省と、改善の取り組み
データレイクができたことで、さまざまなメリットが得られるようになりました。
● 分析対象のデータの追加が容易になった
● 部門横断的なデータ活用ができるようになった
● 年単位レベルの長期間データが分析できるようになった
● 業務システム側で長期間のデータを抱え込まなくて済むようになった
● 分析の粒度をデータ発生元の生データまで辿れるようになった
しかし実際にデータレイクを運用してみると、新たな課題が見えてきました。新たに発生した代表的な課題を2つ挙げてみます。
課題3:
生データを生成されたままの形で格納しているため、文字および改行コード、日時の表現形式がシステムごとにバラバラ。そのため分析に使用するために都度形式を揃えるためのデータ加工が必要とされ、分析作業の速度・効率が上がらない。課題4:
広大なストレージに無計画にデータを格納し続けたため、どこに何が格納されているかわからなくなってしまった。また、画像や音声などの非構造化データを格納してみたはいいものの、どのように分析に掛ければ良いのか適切な技術が適用できずにいる。結果、活用されないデータが大量に貯まり、湖(データレイク)ではなく沼(データスワンプ)になってしまった。このような状況を受けて、マッキンゼーは2017年に「データレイクに飛び込むためのよりスマートな方法」というタイトルの論文を発表しています。
参考:A smarter way to jump into data lakes | McKinsey Digital
この論文では、データレイクはそれ自身で独立して使うものではなく、データ分析基盤の重要な要素として活用するものである、との主張がなされています。それぞれのステージの説明詳細については、原文をご参照ください。
現在のデータレイク
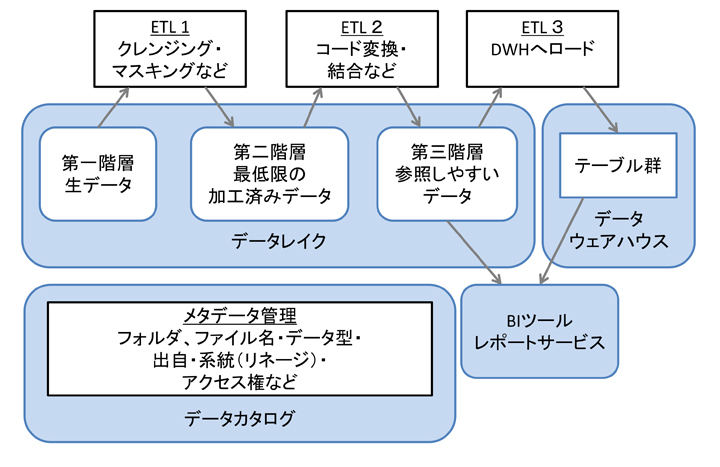
このように今まで発表された論文や、実際にデータレイクを構築した企業が経験した実績を元に、データレイクは少しずつ進化しています。2021年の現在においては、データレイクにおける課題3を解決するために、名称は統一されていないものの、データレイクに格納したデータを段階的なETL処理を施して内部的に複数の階層に分けて構成する方法が検討・採用されてきています。
第一階層(「ランディング層」「ステージング層」「インターフェース層」など)
● 生データをそのままの形で受け取り、保存しておく階層● 長期保存と、最も細かいレベルでのデータ検証目的で使用する
第二階層(「一次処理層」「中間層」「アーカイブ層」など)
● すぐに検索が実行できるレベルの最低限の加工を行ったデータを保存する階層・不正データ、空白データの除去
・文字、改行コード統一
・タイムスタンプ形式統一
・ファイル圧縮形式統一
・フォルダ構造整備-パーティション化
・データマスキング
・非構造化データのメタデータ(タグ)付与
● データの内容を詳しく知る人が探索的データ分析の目的で使用する
● 機械学習のための学習データおよび検証データとしても使用する
第三階層(「構造化層」「分析層」など)
● 人間が内容をより理解しやすい構造に加工したデータを保存する階層・コード番号の実データ変換(”1”→”男性”など)
・親子テーブルの結合
・明らかに不要な要素、カラムの削除
・詳細過ぎるデータの集計(コンマ秒単位→時間単位など)
● ビジネス寄りのデータ分析者が、データウェアハウスよりも詳細なデータで分析したい場合に使用する
● データウェアハウスのデータ構造と近しくなるため、データウェアハウスのオフロード先(普段分析に使わないが、場合によっては必要になる過去データ置き場)としての意味合いもある
● 逆に、この層のデータを完全にデータウェアハウスにロードしてしまい、この層自体作らないという考え方もある
● 用途によっては、APIを提供して、外部関連システムにデータを提供する目的で使用する場合もある
-
データレイクとその周辺機能

また課題4においては、データレイクに蓄積されたデータに関する、以下のメタ情報を把握する必要があります。
・フォルダ、ファイル、ファイル内の要素、カラム等の物理名
・要素、カラムのデータ型
● ビジネス視点のメタ情報
・フォルダ、ファイル、要素、カラムの論理名
・データの読み方、業務上の用途
・データの出自(発生元情報)
・データの系統(発生元からのデータ加工変遷、「リネージ」とも呼ばれる)
● ガバナンス関連情報
・フォルダ、ファイル、要素、カラムごとのアクセス権
このメタ情報管理を実現するために「データカタログ」と呼ばれる各種管理情報を保持する仕組みが導入されますが、データカタログ機能を提供する製品・サービスはデータレイクとは異なります。従ってデータカタログはデータレイク構築とは別に、要件や予算規模に応じて検討・導入する必要があります。
ここまででデータレイクがどのように登場し、進化してきたかを見てきました。ここからは、未来のデータレイクの姿について考察していきます。










