


今回は、仕事で使うことを主眼において、PythonとExcelを比較してみよう。結論から言えば、適材適所で用途に応じて使い分けるのがベストだ。とは言え、どのような場合にPythonを使うと良いのか考察してみよう。
-
Python vs Excel - 五番勝負

第一回戦 - どちらが気軽に使えるか?
最初に、PythonとExcelで「どちらが気軽に使えるか」を比べてみよう。言うまでもなく、Excelを使う時は、スプレッドシートのセルにデータを入力し、マウスで操作を選んでいくというスタイルだ。これに対して、Pythonはエディタでプログラムを書いて実行するか、Jupyter NotebookやColaboratoryなどの対話実行環境を開いて、プログラムを記述していくというスタイルだ。
-
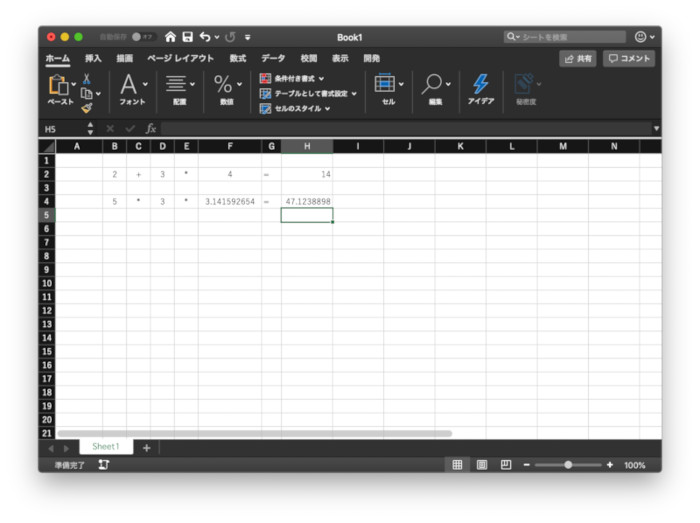
ExcelはGUIで操作を行う

-
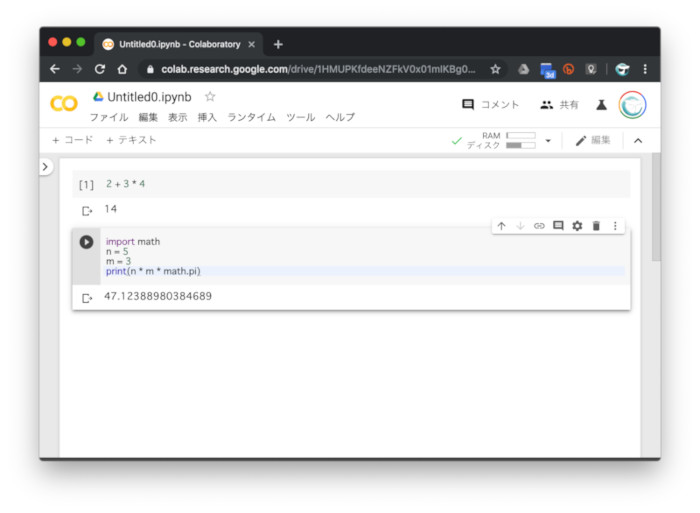
Pythonはエディタや対話環境を開いてプログラムを記述していく

やはり、気軽さという部分だけで考えるなら、データ入力以外はマウス操作を主体にして操作できるExcelの方が気軽と言えるだろう。しかし、基本的にExcelは有償でありPythonはフリーである。財布の観点から見ればPythonが気軽だ。
また、最近では、Webブラウザ上で使えるオンライン版のExcelも用意されており、ブラウザ上で、ささっと表計算が行えるので重宝する。この点でも、Pythonは負けていない。Webブラウザから使えるPythonの対話実行環境の『Google Colaboratory』がある。ブラウザでアクセスするだけで、手軽に科学計算やAIライブラリのライブラリが整ったPythonを利用することができる。なお、Colaboratoryに関しては、本連載の27回目でも紹介している。今回、Excelとの勝負にあたり、PythonはColaboratory環境を利用することにする。
【判定】 気軽に使えるのは、Excel。ただし、Excelは有償。また双方ともWebブラウザからも使えるなど利便性は互角。
第二回戦 - CSVファイルが見やすいのは?
次は、適当なCSVファイルを読み込んで、どちらが見やすいかを比べてみよう。ここで利用するのは、『政府統計の総合窓口e-Stat』より、『国勢調査 男女別人口-全国,都道府県(大正9年~平成27年)』からダウンロードしたCSVファイルを読み込んでみた。
ExcelではダウンロードしたCSVファイルをそのまま読み込んだ。
Pythonでは上述のGoogle Colaboratoryを利用した。その際、メニューから[表示 > 目次]をクリックし、[ファイル]のタブより、CSVファイルをアップロードして、以下のプログラムを実行した。
import pandas as pd
pd.read_csv("c01.csv", encoding="sjis", skipfooter=2, engine='python')
それでは、両者を比べてみよう。
-
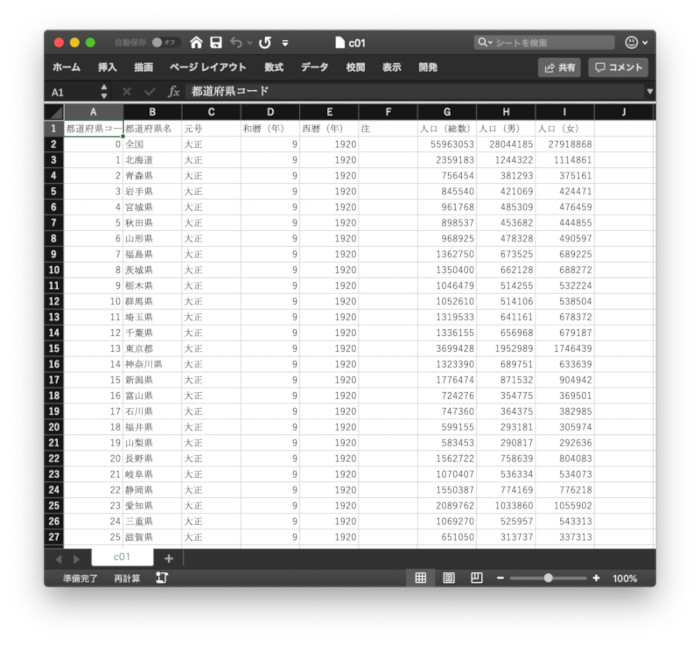
ExcelでCSVファイルを読み込んだところ

-
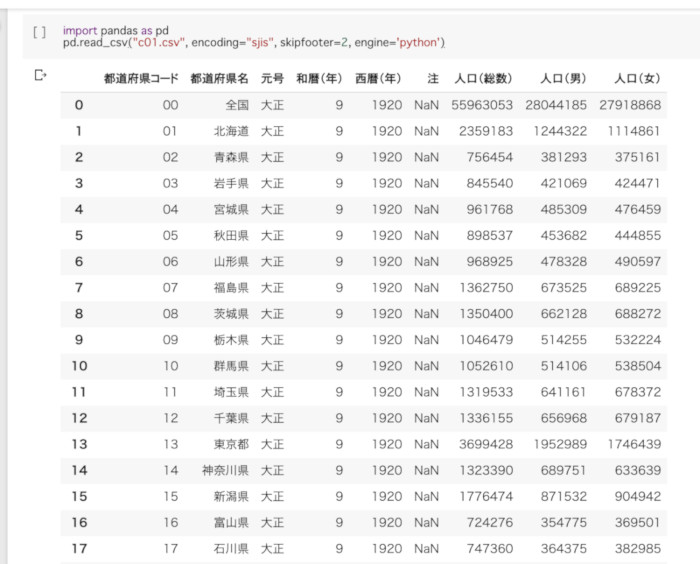
PythonでCSVファイルを読み込んで表示したところ

両者を比べてみると、明らかにPythonの方が見やすい。これは、Excelが汎用的な用途で利用されるのに対して、PandasはCSVファイルなどの表データを読み込むことを主眼に置いていることが理由だろう。もちろん、Excelでもテーブルのスタイルを設定すれば同じように綺麗に色分け表示できるが、ここでは読み込んですぐの状態を比較した。
ちなみに、「Pythonの方が見やすい」と一言で言ったが正確に言うと、Pandasライブラリに対するColaboratoryの出力だ。Excelと比べてPythonには豊富なライブラリが用意されているので、そうしたライブラリを使えることや、自身でプラグインを作って出力をカスタマイズできるという点も大きい。
【判定】 美しく表示されるのは、Python。ただし、Excelは汎用用途に特化しているのに対して、PythonライブラリがCSVファイルの読み込みに特化していることが理由。
第三回戦 - グラフが作りやすいのは?
次にグラフ作成対決をしてみよう。最初に、先ほど利用したCSVファイルを元に、1920年の都道府県別人口データのグラフを作成してみよう。
最初にExcelの操作方法から見てみよう。今回のCSVファイルでは、1920年から2015年まで各都道府県ごとに連続して人口を表すデータが並んでいる。そこで、1920年のデータだけ新規シートへコピーし、不要な列を削除した上で、データを選択し、リボンメニューの[挿入]から縦棒のグラフを選択した。
-
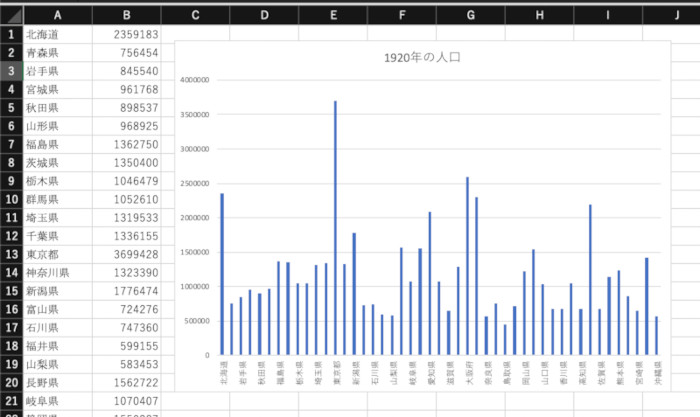
Excelで1920年の都道府県別人口データのグラフを作成した

同じグラフをPythonで描画してみよう。Colaboratoryでは残念ながら日本語フォントが入っていないため、グラフが文字化けしてしまう。しかし、Colaboratoryは拡張性が高く、独自のフォントやライブラリの追加が容易だ。以下のコードを実行して、フォントをインストールしよう。
# Colabへ日本語フォントのインストール
!apt-get -y install fonts-ipafont-gothic
!rm /root/.cache/matplotlib/fontlist-v300.json
# 実行後、メニューより[ランタイム > ランタイムの再起動]を実行
ただし、フォントはインストールしただけでは反映されず、Pythonのランタイムを再起動が必要だ。メニューより[ランタイム > ランタイムの再起動]を実行しよう。
さらに、日本語フォントをライブラリに設定しよう。以下のコードを実行する。
import pandas as pd, numpy as np
import matplotlib.pyplot as plt
import seaborn
seaborn.set(font='IPAGothic')
以上で、必要な準備が整った。以下のコードを実行するとグラフが描画される。
plt.figure(figsize=(8, 4), dpi=130) # グラフのサイズを指定
d = pd.read_csv("c01.csv", encoding="sjis", skipfooter=2, engine="python")
# 西暦1920年のデータを取り出す
d = d[d["都道府県名"] != "全国"] # 全国を除外
y1920 = d[d["西暦(年)"] == 1920]
# グラフの描画
x = np.arange(len(y1920))
plt.bar(x, y1920["人口(総数)"].astype(int))
plt.xticks(x, y1920["都道府県名"], rotation=90, fontsize=7)
plt.title("1920年の人口")
plt.show()
実行すると以下のようになる。
-
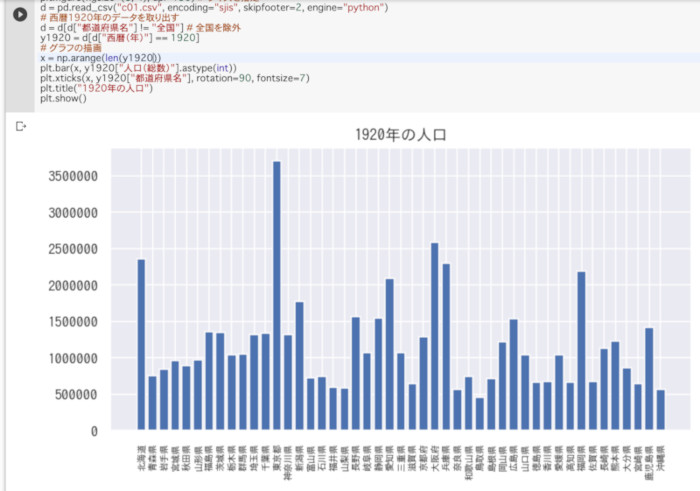
Pythonで1920年の人口グラフを描画したところ

Excelではデータを目視してデータを選びグラフを描画したのに対して、Pythonを利用する場合は、データ操作に特化したPandasライブラリのおかげで、任意のデータを手軽に取り出し、グラフを描画することができた。どちらも、操作に習熟していれば、あっという間にグラフを描画できる。
なお、オンライン環境のColaboratoryを使う場合は日本語フォントのインストールが必要となるのでこの点はマイナスだが、Colaboratoryの元となったJupyter Notebookをローカルにインストールした場合には、一度フォント設定をしてしまえば、以後設定は不要となるため、この点は考慮しないものとして考えた。
【判定】引き分け。マウス操作で直感的に操作できるのはExcelだが、Pandasやmatplotlibのライブラリに習熟していれば、Pythonでも簡単に描画できる。
第四回戦 - 複雑なグラフが作りやすいのは?
以上、ここまでの部分で簡単な比較をしてみた。それでは、もう少し複雑なグラフの作成ではどうだろうか。次に、1920年、1970年、2015年の三つの項目をグラフ中に描画してみよう。
Excelでは、CSVファイルを読み込んだ後、リボンの[データ]にあるフィルタの機能を利用して、1920年、1970年、2015年の各都道府県別データを抽出する。新規シートを作成し、それぞれ抽出したデータを年ごと列ごとににコピーした。そして、各年のその上でグラフを描画した。
Pythonでは、以下のプログラムを実行して描画した。
plt.figure(figsize=(8, 4), dpi=130) # サイズを指定
d = pd.read_csv("c01.csv", encoding="sjis", skipfooter=2, engine="python")
# 不要なデータを削除
d = d[d["都道府県名"] != "全国"] # 全国を除外
d = d[d["都道府県名"] != "人口集中地区"]
d = d[d["都道府県名"] != "人口集中地区以外の地区"]
# 各年のデータを抽出
y1920 = d[d["西暦(年)"] == 1920]
y1970 = d[d["西暦(年)"] == 1970]
y2015 = d[d["西暦(年)"] == 2015]
# グラフの描画
x = np.arange(len(y1920))
plt.plot(x, y1920["人口(総数)"].astype(int), label="1920年")
plt.plot(x, y1970["人口(総数)"].astype(int), label="1970年")
plt.plot(x, y2015["人口(総数)"].astype(int), label="2015年")
plt.xticks(x, y1920["都道府県名"], rotation=90, fontsize=7)
plt.title("都道府県別の人口")
plt.legend()
plt.show()
それでは、作成した折れ線グラフを比較してみよう。
-
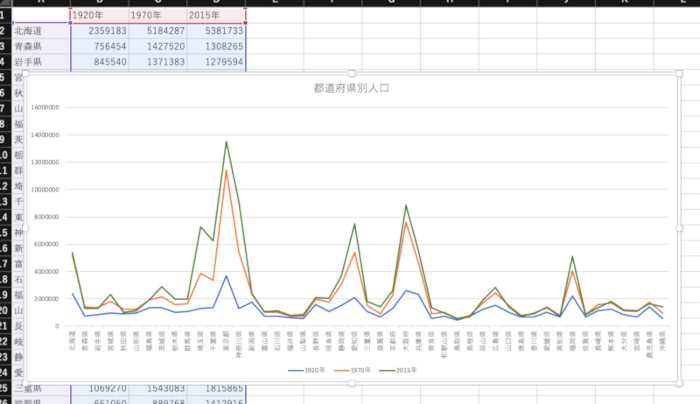
Excelで三項目の折れ線グラフを描画したところ

-
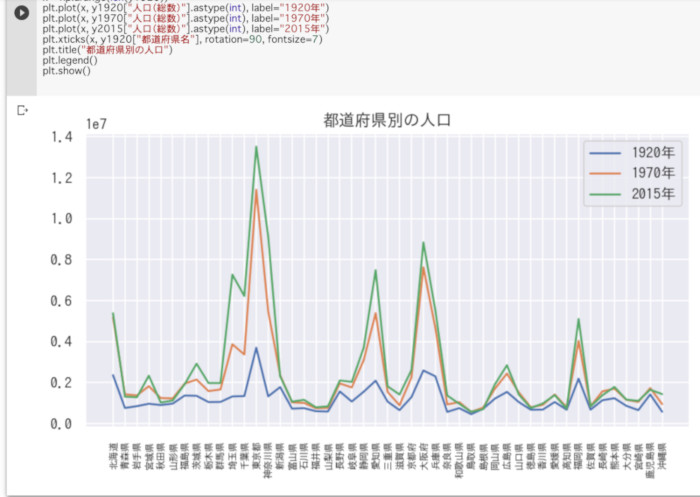
Pythonで三項目の折れ線グラフを描画したところ

先ほどと同様に、操作に習熟していれば、作成にかかる手間も、それほど変わらない。グラフのデザインが異なるだけで、どちらも同じように描画できるので、どちらが上とは言い難いので、やはり引き分けだろう。ただし、Pythonでは手軽に複雑な条件でデータを抽出できるため、データの内容によっては、Pythonが優位になる可能性もある。
【判定】引き分け。
第五回戦 - 集計してみよう
さて、続いて、先ほどのデータを集計してみましょう。1920年から2015年の間に、各都道府県でどれだけ人口が増加したかを調べて、成長順にデータを並び替えてみましょう。
Excelの場合は、先ほどグラフを作ったのと同じ手順で、1920年と2015年の人口データを新規シートにコピーし、各行に対して成長率を調べる計算式(2015年÷1920年)をオートフィルを利用して設定します。その後、リボンの[データ]タブより、成長率の列をキーにして並び替えを行ったものだ。
Pythonの場合は、以下のプログラムを実行した。処理の内容は、CSVデータを読み込み、1920年と2015年のデータを抽出し、成長率を求めて並び替えて表示するというものだ。
import pandas as pd
d = pd.read_csv("c01.csv", encoding="sjis")
# 不要データを削除
d = d[d["都道府県名"] != "全国"] # 全国を除外
d = d[d["都道府県名"] != "人口集中地区"]
d = d[d["都道府県名"] != "人口集中地区以外の地区"]
# 1920年と2015年を抽出してカラムに名前を付けて結合
y1920 = d[d["西暦(年)"] == 1920][["都道府県名", "人口(総数)"]]
y1920 = y1920.rename(columns={'人口(総数)': '1920年'})
y2015 = d[d["西暦(年)"] == 2015][["都道府県名", "人口(総数)"]]
y2015 = y2015.rename(columns={'人口(総数)': '2015年'})
y = pd.merge(y1920, y2015, on='都道府県名')
# 成長率を求める
y["成長率"] = y['2015年'].astype(int) / y['1920年'].astype(int)
# 並び替えて表示
y.sort_values(by=["成長率"], ascending=False)
双方の実行結果は以下の通り。
-
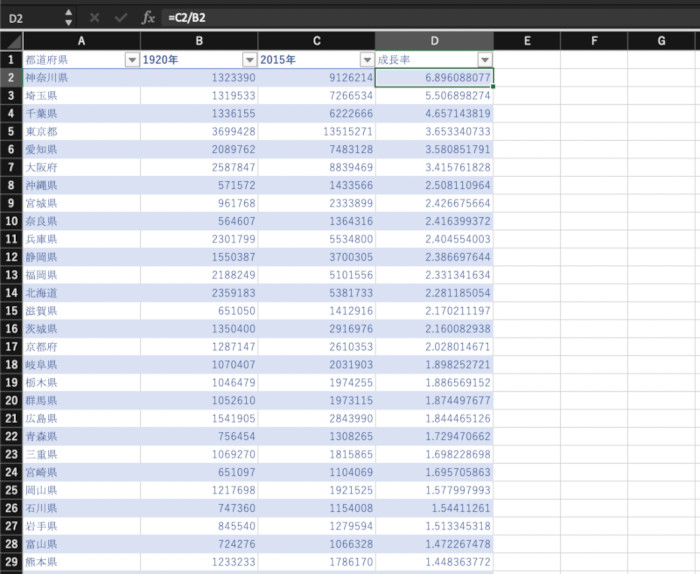
Excelで成長率順に表示したところ

-
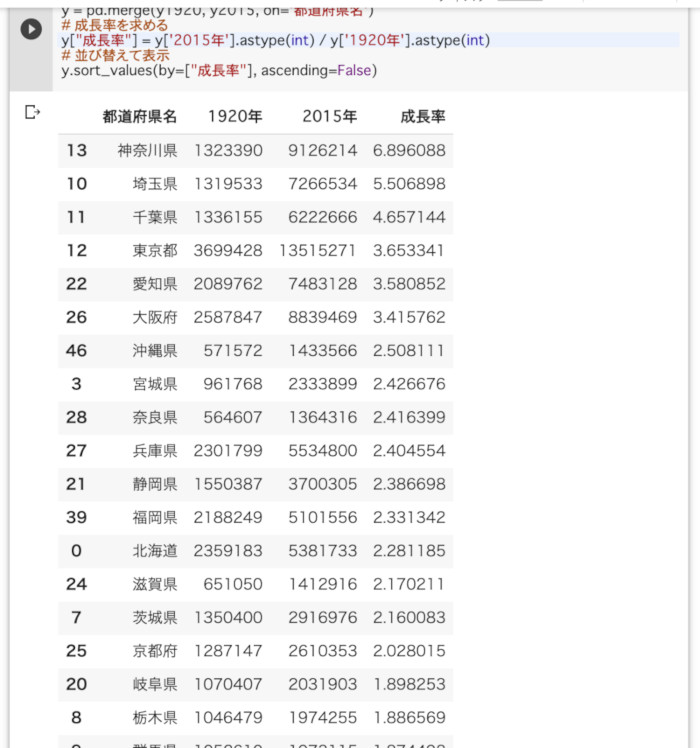
Pythonで成長率順に表示したところ

当然ながら処理結果自体はどちらも同じとなる。なお、ExcelにもPythonにもピボットテーブルなど、複雑な集計を行う機能が備わっているが、今回は、地道に操作してみた。Excelでは地道なフィルタ操作や範囲選択とコピー&ペーストが必要になるのに対して、Pythonのプログラムでは、手軽にデータ操作が可能なのことが分かると思う。
【判定】処理が複雑になればなるほどPythonが優勢。
まとめ
以上、今回はPythonとExcelを対決させてみた。一般的な観点から見れば、マウス操作で手軽に操作できるExcelと、プログラミングを覚えないと操作できないPythonでは圧倒的にExcelの方が難易度が低い。そのため、簡単なデータからグラフを作成するだけであれば、Excelで十分と言える。
しかし、Pythonが生きてくるのは、その後の工程だ。データに対して、条件を指定して抽出したり集計したりする場合には、Pythonで書いた方が分かりやすい。プログラムとして、データの操作の手順を残すこともできる。
もちろん、Excelだけでも、大抵の作業をこなすことができるだろう。しかし、さらに一歩進んでPythonも使いこなせると、仕事の幅がぐっと広がることだろう。
自由型プログラマー。くじらはんどにて、プログラミングの楽しさを伝える活動をしている。代表作に、日本語プログラミング言語「なでしこ」 、テキスト音楽「サクラ」など。2001年オンラインソフト大賞入賞、2004年度未踏ユース スーパークリエータ認定、2010年 OSS貢献者章受賞。技術書も多く執筆している。




