2023年初めに大ブレイクしたChatGPTだが「大規模言語モデル(LLM)」と呼ばれる仕組みに基づいている。そのブレイクから半年、ChatGPTに追いつけ追い越せと多くの研究者が大規模言語モデルを改良し続けている。それで動かすだけならば意外と簡単に試すことができる。今回は、オープンソースのモデルを動かす方法を紹介しよう。
-
OpenCALMを使って猫の名前や小説のアイデアを出したところ

ChatGPTに追いつけ追い越せ
ChatGPTは会話型AIである。AIを相手にして、かなり良い精度で会話をすることができる。しかし、ただ会話ができるだけではない。「生成AI(Generative AI)」と呼ばれるだけあって、かなり複雑な指示を読み取って、文章生成を行うことができる。もともと大規模なWeb上のテキストデータを用いて、機械学習で訓練していることから、大規模言語モデル(LLM)と呼ばれている。 それで、ChatGPTを使う事で、文章を要約したり、箇条書きの文章から文章を生成したり、プログラムを生成したり、キャッチコピーを考えたり…と、かなり高度な仕事をこなすことができる。さながら、優秀な秘書のような実力を発揮する。その驚異的な力は、多くの人の仕事を奪うまでと言われている。
-
ChatGPTに前回の連載の内容を要約させたところ - 驚くほどの正確さだ

そんな、ChatGPTにおいつけおいこせと、各社がしのぎを削っている。ChatGPTを開発し提供しているOpenAIはMicrosoftの資金提供を受け、大規模言語モデル(LLM)の改良や応用の面で業界のトップを走っている。プログラム自動生成という面でも、GitHub Copilotを発表し、驚異的な生産性の向上を実現している。Microsoftは、検索エンジンのBingにも大規模言語モデルを応用しており、今後は、ExcelやWordなどさまざまな製品にも搭載していく。 これに対して、Googleは会話型AIのBardを発表し、OpenAIとMicrosoftの両陣営に真っ向から勝負を挑んでいる。先日も、音楽を生成する「MusicLM」や、テキストと音声の両方に対応したAudioPaLMを発表し話題になった。
そして、第三勢力として注目を集めているのが、FacebookやInstagramを運営するMetaだ。Metaは自社で開発していた大規模言語モデル「LLaMA」をオープンソースとして公開し、世界中の研究者がこのモデルを改良できるようにした。
オープンソースの威力はすさまじかった。わずかな期間で、Metaの「LLaMA」を改良した「Alpaca」がリリースされ、それをShareGPTのデータでファインチューニング(微調整)した「Vicuna」などの数多くのモデルが公開されることとなった。
ただし、もともと、Metaが公開した「LLaMA」の利用は、アカデミック用途限定というライセンスの縛りをつけていた。これに対して、Databricks社は2023年4月12日に「Dolly-v2」を公開した。これが商用利用も可能な史上初の大規模言語モデルとなった。Databricks社は、社員5000人を活用して作成した1万5千回分の会話データセットを用いて作成したモデルだった。その後、画像生成AIで大手のStable Diffusionを開発したStability.aiも「StableLM」というオープンなモデルを公開した。
日本語が使える大規模言語モデルはあるの?
前述のオープンソースの大規模言語モデルの多くは、英語のみに対応したものが多く、日本語を話せるモデルは、まだそれほど多くなかった。2023年5月後半には、そんな状況が一変する。17日にサイバーエージェント社から68億パラメーターを持つモデル「OpenCALM」が公表され、続く同日にrinna社からも36億パラメーターのモデル「japanese-gpt-neox-3.6b」などが公開されたのだ。今後、これを皮切りに多くの研究機関から日本語ベースの大規模言語モデルが発表されていることが予想される。
日本語が使える大規模言語モデル「OpenCALM」とは?
それでは、本題に入ろう。このように、2023年に入ってから、世界中で大規模言語モデルを舞台にした熱い戦いが繰り広げられている。そうした、話を聞いているだけでは、実にもったいない。というのも、Metaが公開したLLaMA以降、多くの大規模言語モデルはオープンソースとして公開されているのだ。そのため、実際に環境さえ用意すれば誰でも試すことができるのだ。
今回は、前回に引き続き、Google Colaboratory(以後、Colabと略す)を利用して、OpenCALMを動かしてみよう。
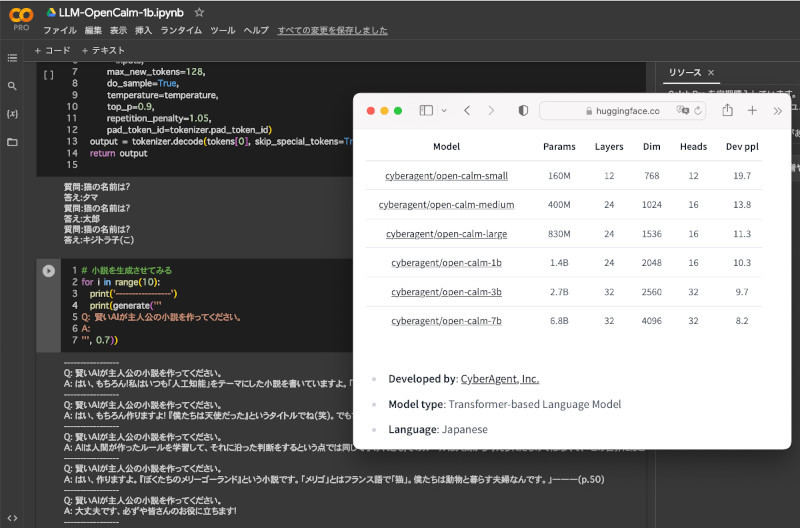
なお、OpenCALMには、次のようにモデルのサイズにより、small/medium/large/1b/3b/7bが用意されており、こちらから一覧を確認できる。利用するマシンや実行環境、利用用途に応じて使い分けよう。当然、パラメータが膨大なほど生成速度は遅くなるが精度は向上する。
-
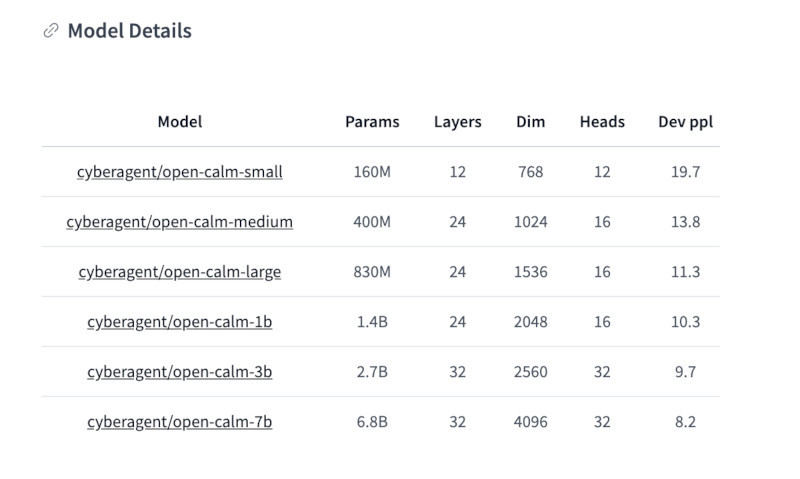
OpenCALMのモデルサイズとパラメータ数

OpenCALMを試してみよう
それでは、Colabを使って、OpenCALMを試してみよう。ブラウザで以下のColabにアクセスしたら、Googleアカウントでサインインしよう。
Google Colaboratory
[URL] https://colab.research.google.com/
そして、サインインできたら、[ノートブックを新規作成]ボタンをクリックしよう。
-
![[ノートブックを新規作成]ボタンを押そう](images/004.jpg)
[ノートブックを新規作成]ボタンを押そう
![[ノートブックを新規作成]ボタンを押そう](/techplus/photo/article/zeropython-104/images/004l.jpg)
次に、画面上部にある「ランタイム」というメニューから「ランタイムのタイプを変更」をクリックして、[GPU]を選択して「保存」ボタンを押そう。
-
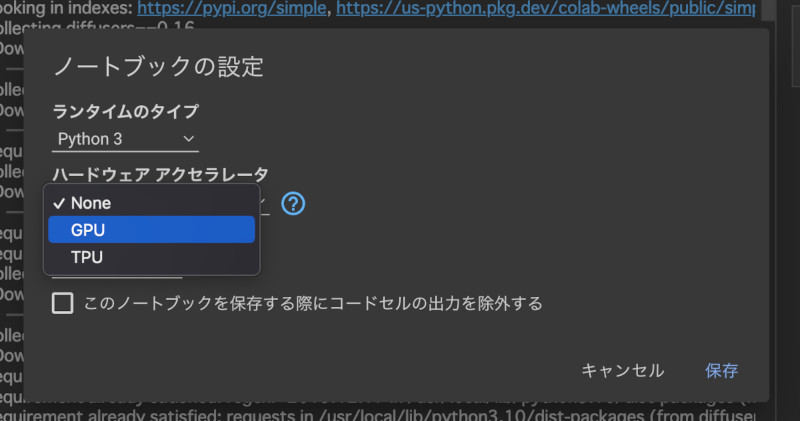
ランタイムのタイプをGPUに変更する

必要ライブラリのインストール
続いて、OpenCALMを実行するのに必要なライブラリをインストールしよう。テキストボックス(セルと呼ぶ)に以下のコードを入力して、セルの左側にある実行ボタンを押そう。
# 環境のインストール
!pip install -U \
transformers==4.30.2 \
sentencepiece==0.1.99 \
accelerate==0.20.3
すると、必要なライブラリがインストールされる。なお、OpenCALMを実行するには、PyTorchも必要だが、Colabには最初からインストールされているので上記の手順には入れていない。
-

ライブラリをインストールしたところ

OpenCALMのモデルを読み込もう
続いて、画面上部にある[+コード]をクリックして、コードセルを作成したら次のPythonのプログラムを入力して実行しよう。これは、OpenCALMのモデル1bを読み込むものだ。
# モデルを指定 --- (*1)
model_name = "cyberagent/open-calm-1b" # メモリが許す場合こちらがオススメ
# model_name = "cyberagent/open-calm-medium" # メモリエラーになる場合はこちらを
# モデルの読み込み --- (*2)
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", torch_dtype=torch.float16)
tokenizer = AutoTokenizer.from_pretrained(model_name)
実行すると、モデルの読み込みが行われる。これには、それなりに時間が掛かる。
-
モデルの読み込みをしているところ

実行が完了すると、WARNING(警告)が表示されるが、エラーでなければ読み飛ばしても問題ない。
プログラムを確認してみよう。上記の(*1)でモデルを指定子、(*2)でモデルを読み込んでいる。なお、この時点でメモリエラーが出るようなら、(*1)のモデルを「cyberagent/open-calm-medium」などに変更してみよう。
いよいよプロンプトを実行してみよう
それでは、続いてプロンプトを実行してみよう。プロンプトとは大規模言語モデルに与える指示文のことだ。OpenCALMは日本語に対応しているのでプロンプトを記述できる。ここでは「吾輩は」というシンプルなプロンプトを与えてみる。空気を読んで「吾輩は猫である」と表示してくれたら成功だ。
# プロンプトを指定 --- (*1)
prompt = '吾輩は'
# 推論を行う --- (*2)
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
with torch.no_grad():
tokens = model.generate(
**inputs,
max_new_tokens=64,
do_sample=True,
temperature=0.8,
top_p=0.9,
repetition_penalty=1.05,
pad_token_id=tokenizer.pad_token_id,
)
# 結果を表示 --- (*3)
output = tokenizer.decode(tokens[0], skip_special_tokens=True)
print(output)
実行してみると、「吾輩は猫である。にゃあ!」などの応答が表示されることだろう。良い感じだ。ただし、これは、ランダムに生成されるものであるため、実行する度に異なる応答が表示されることだろう。
-
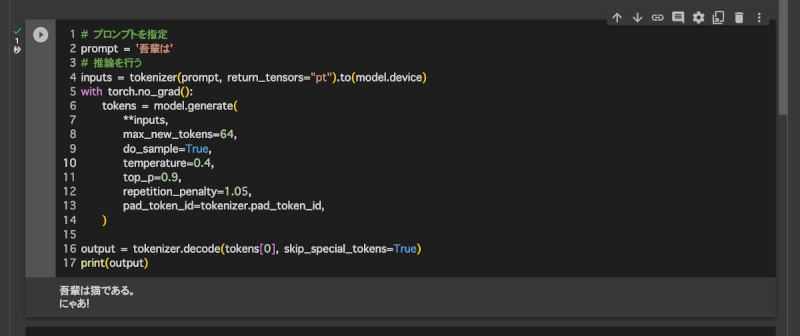
プロンプトを指定して推論したところ、吾輩は?

プログラムを確認してみよう。(*1)でプロンプトを入力する。ここを変更することで、異なるテキストを生成できる。そして、(*2)で大規模言語モデルによる推論を行って、(*3)で結果を表示する。
なお、大規模言語モデルでは、トークナイザーを利用して、文章を数値ベクトルに変換し、数値ベクトルを利用して応答を生成する。この時、生成された応答も数値ベクトルであるため、(*3)のように、トークナイザーで実際のテキストに書き戻す(デコードする)ことで、人間が読めるテキストになるのだ。
いろいろなプロンプトを実行してみよう
なお、せっかくなので、いろいろなプロンプトを実行して結果を観察してみよう。手軽にプロンプトが実行できるように次のような関数を定義してみよう。以下のPythonのプログラムは、単に先ほどの推論を行うプログラムをgenerateという関数にまとめただけのものだ。
# 推論を行う関数を用意
def generate(prompt, temperature=0.7):
inputs = tokenizer(prompt.strip(), return_tensors="pt").to(model.device)
with torch.no_grad():
tokens = model.generate(
**inputs,
max_new_tokens=128,
do_sample=True,
temperature=temperature,
top_p=0.9,
repetition_penalty=1.05,
pad_token_id=tokenizer.pad_token_id)
output = tokenizer.decode(tokens[0], skip_special_tokens=True)
return output
それで、この関数を利用していろいろ遊んでみよう。
以下は、OpenCALMに猫の名前を考えてもらうプロンプトを作った。単に「猫の名前を考えてください。」と入力してみよう。
print(generate('猫の名前を考えてください。'))
すると、次のようにトンチンカンな回答が表示される。
猫の名前を考えてください。
ペットの名前を予想して、的中するとプレゼントがもらえますよ!
ところが、大規模言語モデルの面白いところなのだが、模範的な回答をいくつかプロンプトに差し込むことで、指示者の意図を汲み取ってくれる。これを、『思考の連鎖(CoT / Chain of Thought Prompting)』と呼ぶ。
以下のコードを入力して試してみよう。
print(generate('''
質問:猫の名前は?
答え:タマ
質問:猫の名前は?
答え:太郎
質問:猫の名前は?
答え:'''))
すると、次の画像のように「三毛」というそれらしい答えを出すことができた。その後、何度か再実行してみると「シロちゃん」「豆助」「一太」などの回答が表示される。
-
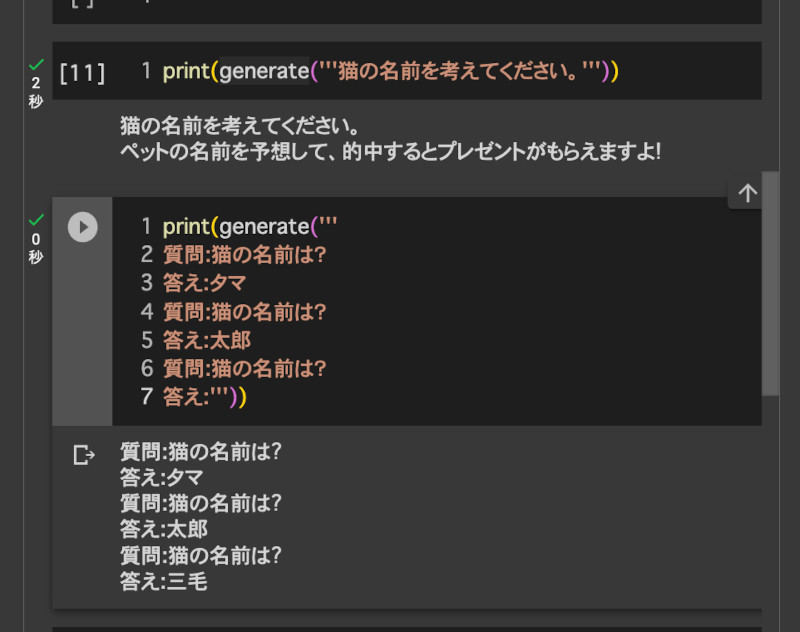
思考の連鎖CoTを利用すると大規模言語モデルの能力を引き出すことができる

小説を生成してみよう


続いて、OpenCALMをいろいろなアイデア生成に使ってみよう。以下のPythonコードを実行してみよう。小説のアイデアを考えてくれる。
# 小説を生成させてみる
for i in range(10):
print('-----------------')
print(generate('''
Q: 賢いAIが主人公の小説を作ってください。
A:
''', 0.7))
実行すると次のように、いろいろなストーリーを考えてくれたり、考えてくれなかったりする。
-
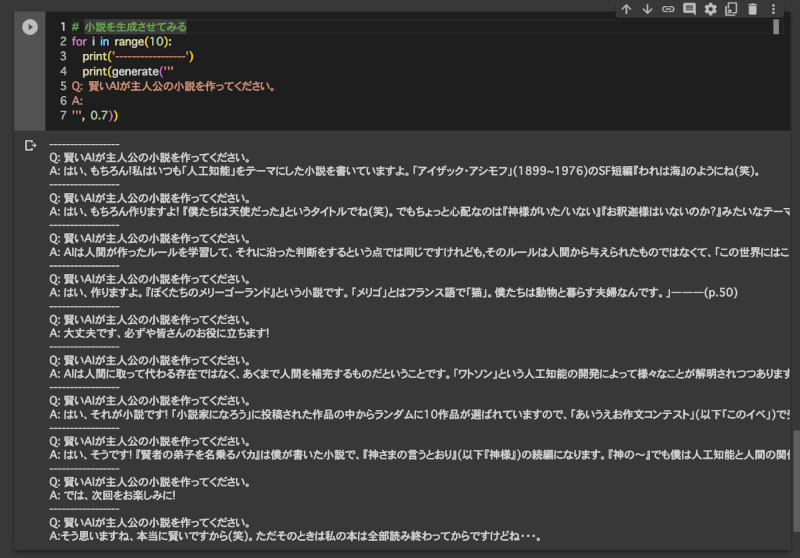
小説を考えてもらったところ

なお、先ほど定義したgenerate関数だが、第2引数に熱量(temperature)を指定できるようにした、この値が大きいほど、ランダム性が高い回答をするようになる。0.1などを指定すると、だいたい同じ回答を返すようになる。面白いので変更して試してみよう。
まとめ
以上、今回は、日本語が使える大規模言語モデルのOpenCALMを使う方法を解説した。プロンプトを変えるだけで、回答がいろいろ変化するので試してみると良いだろう。
ただ、少し試してみただけなので、何とも言えないが、モデル1bでは、大規模言語モデルの得意とするプログラムの生成や、文章の要約といったタスクを実行することはできなかった。もしかすると、プロンプトを工夫することでできるかもしれないので、この辺りも試してみると良いだろう。
なお、Colabに課金するとより高スペックなマシンを利用できるようになるのだが、同じプログラムで、モデル7b(68億パラメータ)も動かすことができた。動かすだけでも面白いので、オープンソースの大規模言語モデルの実力を試してみると良いだろう。
自由型プログラマー。くじらはんどにて、プログラミングの楽しさを伝える活動をしている。代表作に、日本語プログラミング言語「なでしこ」 、テキスト音楽「サクラ」など。2001年オンラインソフト大賞入賞、2004年度未踏ユース スーパークリエータ認定、2010年 OSS貢献者章受賞。技術書も多く執筆している。直近では、「実践力をアップする Pythonによるアルゴリズムの教科書(マイナビ出版)」「シゴトがはかどる Python自動処理の教科書(マイナビ出版)」「すぐに使える!業務で実践できる! PythonによるAI・機械学習・深層学習アプリのつくり方 TensorFlow2対応(ソシム)」「マンガでざっくり学ぶPython(マイナビ出版)」など。