連載第6回の目的
この回から2回にわたり、手書きの数字を認識するサンプルを通じて、Pythonで作成したKerasモデルをTensorFlow.jsで利用する方法を理解します(図1)。この回では、Python環境の準備、学習済みモデルの構築を行います。
-

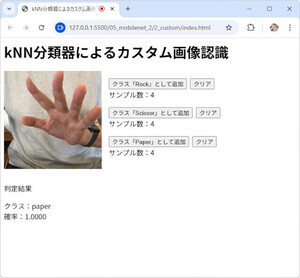
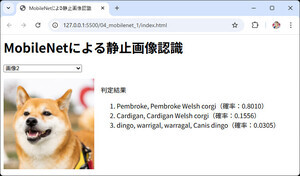
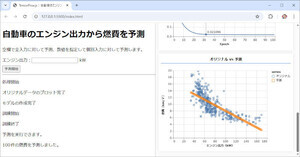
図1:完成サンプルイメージ

完成サンプル
https://github.com/wateryinhare62/mynavi_tensorflowjs/
今回のテーマも画像認識ですが、モデルの構築と利用を異なるプラットフォームで行います。共通のフォーマットとコンバータを介して、Pythonプラットフォームで構築したモデルをTensorFlow.jsすなわちWebプラットフォームで利用できることを理解します。
[NOTE]サンプルについて
本記事のサンプルは、Kerasのデモプログラム(https://github.com/keras-team/keras/tree/master/examples/demo_mnist_convnet.py)を一部改変して作成、実行しています。
MNISTデータベースとは
手書き文字認識モデルの構築には、MNISTというデータベースを使用します。MNISTとは、データベース機械学習、特に画像認識モデルの学習と評価に広く使われている、手書き数字の画像データのセットです。NIST(米国国立標準技術研究所)のデータを再構成して作成され(MはModifiedの意)、0から9までの手書き数字6万枚の訓練用画像と、1万枚のテスト用画像で構成されます。各画像には正解として、0~9のラベルが付けられています。このデータを使ってモデルを訓練することにより、手書き数字の認識が可能なモデルを構築することができます。
画像は、28×28ピクセルのモノクロ(グレースケール)画像となっており、背景は黒、文字部分は白です。このため、予測の際にはデータ形式をこれに合わせる必要があります。
派生のデータセットとして、手書きの英数字を含む「EMNIST」や、衣料品画像を集めた「Fashion-MNIST」などがあります。
モデル構築環境の構築
今回は、Pythonによって作成されたモデルをTensorFlow.jsで利用するというテーマなので、まずはPython環境の構築を行います。ただ、単にPythonが動けばよいというわけではなく、その後のパッケージインストールやモデル構築スクリプトなどが正しく動作する必要があります。筆者が試したところ、WindowsでもmacOSでも不具合が見られたので、LinuxディストリビューションであるUbuntuで環境構築を行っていくことにします。
本稿で用いた環境は、以下のとおりです。組み合わせによっては動作しない可能性もある旨、あらかじめご了承下さい。
- Windows 11 Pro(24H2)
- Windows Subsystem for Linux 2.8
- Ubuntu 24.04
- Python 3.12.3
- tensorflow 2.19
- tensorflowjs 4.22.0
WSLを有効化しUbuntuをインストールする
Linuxといっても、WindowsではWSL(Windows Subsystem for Linux)が使えるので、これを使ってLinux環境をWindows上に構築します。インストールするUbuntuは、最新のLTS(Long Term Support)であるUbuntu 24.04です。WSLおよびUbuntuがインストール済みという人は、この手順を飛ばして構いません。
「ターミナル」アプリを起動して、以下のコマンドを実行してください。
PS > wsl --install
管理者権限での実行が求められたら承諾してください。いくつかのサブモジュールがダウンロード、実行された後、「正常に終了しました。再起動する必要があります。」と表示されれば成功です。Windowsを再起動してください。
再び「ターミナル」アプリを起動して、wsl --listコマンドを実行してください。続けて、一覧に「Ubuntu-24.04」があることを確認して、wsl --installコマンドを実行してください。
PS > wsl --list --online
PS > wsl --install Ubuntu-24.04
インストールが済むと、すでにUbuntuは起動しており、そのままUbuntu上のユーザの作成となります(プロンプトが変化しています)。どのようなユーザ名でもよい(Windows上のユーザと同じでもOK)ので、ユーザ名とパスワードを指定してください。なお、ここで作成するユーザが、sudoコマンドによる管理者権限を利用できるユーザとなります。
ここで、Ubuntuのパッケージを以下のコマンドで最新の状態に更新しておきます。
$ sudo apt update
…ユーザのパスワードを求められたら入力する…
$ sudo apt upgrade -y
Pythonのツールをインストールする
Ubuntu 24.04はPythonを標準でサポートしていますが、念のため確認しましょう。以下のコマンドで、バージョンを確認できます(「python」ではなく「python3」でないと呼び出せないので注意してください)。
$ python3 --version
Python 3.12.3
標準では、Pythonのパッケージマネージャ(pip)はインストールされていないので、Ubuntuに用意されているpipのパッケージを以下のコマンドでインストールします。追って必要になる仮想環境のためのパッケージvirtualenvもインストールします。
$ sudo apt install python3-pip
$ sudo apt install python3-virtualenv
もし、カレントワーキングディレクトリがWindowsのファイルシステム上のもの(プロンプトに含まれるパスが/mnt/c/users…などとなっている)である場合には、cdコマンドでLinuxファイルシステムにおけるものに移動しておきましょう。Windowsのファイルシステムにおける制約で、仮想環境の構築時にエラーが発生することがあるためです。
仮想環境を構築してTensorFlowをインストールする
TensorFlowのインストールに先立ち、Pythonの仮想環境を作成しておきます。仮想環境とは、Pythonのインタプリタやパッケージを独立した場所にまとめて、そこでの作業がシステム全体に影響しないようする仕組みです。作業内容に適したバージョンを選択したり、仮想環境は不要になったら削除してしまえばよいなど、手軽に扱えるのもメリットです。
仮想環境は、作業場所となるフォルダに作成するのが一般的なので、今回の目的用に適当なフォルダを作成してください。ここでは、tfjsフォルダをホームディレクトリに作成したものとして説明を進めます。
tfjsフォルダにいることを確認して、以下のコマンドで仮想環境を構築します。
tfjs$ virtualenv -p python3 venv
これで、フォルダvenvがtfjs以下に作成され、仮想環境の一式が置かれます。仮想環境の有効化と無効化は、それぞれ以下のコマンドになります。
tfjs$ source venv/bin/activate 有効化
…仮想環境における作業…
(venv) tfjs$ ./venv/bin/disactivate 無効化
仮想環境がアクティブになると、プロンプトの左端が「(venv)」というように変化します。以降は、プロンプトに注意しながら作業してください。ここまでの作業で、ようやくTensorFlowをインストールできるようになりました。TensorFlow.js形式へのコンバータはTensorFlowJsパッケージで提供されるので、TensorFlowJsパッケージをインストールします。TensorFlowパッケージを含む他のパッケージは、依存関係で自動的にインストールされます。かなり時間がかかるので、気長に待ちましょう。
(venv) tfjs$ pip3 install tensorflowjs
モデル構築スクリプトの作成
必要なものが揃ったので、モデル構築スクリプトの作成に移行しましょう。作成といっても、今回はKerasのGitHubリポジトリにあるデモプログラムdemo_mnist_convnet.py(https://github.com/keras-team/keras/tree/master/examples/demo_mnist_convnet.py)を一部改変して使用することにします。このファイルをダウンロードして、作業フォルダに配置してください。
モデル構築スクリプトに保存スクリプトを追記する
このファイルのやっていることは追って見ていくことにして、まずは以下の行をファイルの最後尾に追記してください。これは、構築したモデルを外部ファイルに保存するAPIの呼び出しです。
model.export('mnist_model')
exportメソッドは、TensorFlowのSavedModel形式でモデルを保存します。他の形式で保存できるsaveメソッドもあり、表1のように使い分けられます。
表1:モデルの保存API
| API | 概要 |
|---|---|
| model.export('xxxx') | TensorFlowのSavedModel形式で保存 |
| model.save('xxxx.h5) | KerasのH5形式で保存(非推奨) |
| model.save('xxxx.keras) | KerasのH5形式で保存(非推奨) |
| model.save('xxxx') | KerasのSavedModel形式で保存 |
H5形式は単独のファイルであり、SavedModel形式は引数で指定したフォルダが作成され、そこにモデルのファイルが配置されます。これらのファイルを直接使うことはないので役割等の理解は不要ですが、今回のサンプルで使うTensorFlowのSavedModel形式を表2に挙げておきます。
表2:TensorFlowのSavedModel形式で作成されるファイル
| ファイル/フォルダ | 概要 |
|---|---|
| assets/ | 語彙テーブルを初期化するためのテキストファイルなど(ここでは空) |
| variables/ | 重みデータ |
| fingerprint.pb | SavedModelのフィンガープリント(ハッシュ) |
| saved_model.pb | モデルアーキテクチャとトレーニング構成 |
モデル構築スクリプトの出力を見てみる
このスクリプトを実行すると、以下のような出力が得られます。警告や情報は省いてあります。
(venv) ~$ python3 demo_mnist_convnet.py
x_train shape: (60000, 28, 28, 1) (1)
60000 train samples (2)
10000 test samples
Model: "sequential" (3)
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━ ━┳━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━ ╇━━━━━━━━━━━━━━━┩
│ conv2d (Conv2D) │ (None, 26, 26, 32) │ 320 │
├─────────────────────────────────┼─────────────────────── ─┼───────────────┤
│ max_pooling2d (MaxPooling2D) │ (None, 13, 13, 32) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ conv2d_1 (Conv2D) │ (None, 11, 11, 64) │ 18,496 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ max_pooling2d_1 (MaxPooling2D) │ (None, 5, 5, 64) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ flatten (Flatten) │ (None, 1600) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dropout (Dropout) │ (None, 1600) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dense (Dense) │ (None, 10) │ 16,010 │
└─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 34,826 (136.04 KB) (4)
Trainable params: 34,826 (136.04 KB)
Non-trainable params: 0 (0.00 B)
Epoch 1/3 (5)
422/422 ━━━━━━━━━━━━━━━━━━━━ 17s 37ms/step - accuracy: 0.8855 - loss: 0.3780 - val_accuracy: 0.9760 - val_loss: 0.0878
Epoch 2/3
422/422 ━━━━━━━━━━━━━━━━━━━━ 20s 36ms/step - accuracy: 0.9627 - loss: 0.1206 - val_accuracy: 0.9815 - val_loss: 0.0666
Epoch 3/3
422/422 ━━━━━━━━━━━━━━━━━━━━ 16s 38ms/step - accuracy: 0.9718 - loss: 0.0913 - val_accuracy: 0.9875 - val_loss: 0.0481
Test loss: 0.04890444129705429 (6)
Test accuracy: 0.9843999743461609
Saved artifact at 'mnist_model'. The following endpoints are available:
* Endpoint 'serve'
args_0 (POSITIONAL_ONLY): TensorSpec(shape=(None, 28, 28, 1), dtype=tf.float32, name='keras_tensor')
Output Type:
TensorSpec(shape=(None, 10), dtype=tf.float32, name=None)
Captures:
126736075415120: TensorSpec(shape=(), dtype=tf.resource, name=None)
126736075416464: TensorSpec(shape=(), dtype=tf.resource, name=None)
126736075418576: TensorSpec(shape=(), dtype=tf.resource, name=None)
126736075417232: TensorSpec(shape=(), dtype=tf.resource, name=None)
126736075417616: TensorSpec(shape=(), dtype=tf.resource, name=None)
126736075419152: TensorSpec(shape=(), dtype=tf.resource, name=None)


かなり長いのですが、これまでの回で学んだ内容の延長となっています。簡単に内容を説明します。
(1)は、訓練データが60,000個、形状は28×28、カラーモードは1すなわちグレースケールである旨の出力です。
(2)は、訓練データが60,000個、テストデータが10,000個であることを示しています。
(3)は、モデルがSequentialモデルであることを表しています。Sequentialモデルについては、第2回で簡単に紹介しました。入出力がともに1個で、層が一直線につながるモデルです。modelのsummaryメソッドにより得られる出力です。
(4)は、パラメータの総数と、訓練可能なパラメータ、訓練不能なパラメータの数を示しています。
(5)はエポック(学習回数)を表しており、この場合は3回で、回数を経るごとにaccuracy(正確性)が向上していることが読み取れます。
(6)は、テスト結果としての損失(loss)と正確性(accuracy)です。十分に低いloss(0.048)と高いaccuracy(0.984)を得られていることが確認できました。
まとめ
今回は、MNISTデータベースを利用した手書き数字の認識の準備として、Pythonによるモデルデータの保存について紹介しました。手順はやや複雑ですが、Windows上にTensorFlowの利用環境を構築する一つの解を示せたのではないかと思います。 次回は、MNISTデータベースを利用した手書き数字の認識の続編として、保存したモデルデータをTensorFlow.jsで読み込み、Canvas上に手書きした数字を認識させるサンプルを紹介します。
WINGSプロジェクト 山内直(著) 山田 祥寛(監修)
有限会社 WINGSプロジェクトが運営する、テクニカル執筆コミュニティ(代表山田祥寛)。主にWeb開発分野の書籍/記事執筆、翻訳、講演等を幅広く手がける。現在も執筆メンバーを募集中。興味のある方は、どしどし応募頂きたい。著書、記事多数。
RSS
X:@WingsPro_info(公式)、@WingsPro_info/wings(メンバーリスト)<著者について>
WINGSプロジェクト所属のテクニカルライター。出版社を経てフリーランスとして独立。ライター、エディター、デベロッパー、講師業に従事。屋号は「たまデジ。」。