



本連載では、AWS社が公開するチュートリアル「機械学習モデルを自動的に作成する」に沿って、以下の流れで解説を進めています。
| 工程 | ステップ | 実施内容 | 連載回 |
|---|---|---|---|
| 準備 | 1 | AWSアカウントを今すぐ無料で作成 | 第10回 |
| 開発 | 2 | Amazon SageMaker Studioをセットアップする | 第10回 |
| 3 | データセットをダウンロードする | 第11回 | |
| 学習 | 4 | SageMaker Autopilot実験を作成する | 第11回 |
| 5 | SageMaker Autopilot実験のさまざまなステージを調べる | 第11回 | |
| 推論 | 6 | 最適なモデルをデプロイする | 第12回 |
| 7 | モデルを使用して予測を行う | 第12回 | |
| 8 | クリーンアップ | 第12回 |
前回は Amazon SageMaker Autopilotを使って機械学習モデルの構築を行いました。今回は機械学習モデルを推論エンドポイントとしてデプロイし、精度検証を行います。
ステップ6:最適なモデルをデプロイする
SageMaker Autopilotの実験が完了したら、次は推論を行うために機械学習モデルのデプロイを行い、推論エンドポイントを作成します。「Best」の表示がある行を選択した状態で右上の「Deploy model」を選択するか、右クリックで「Deploy model」を選択します。
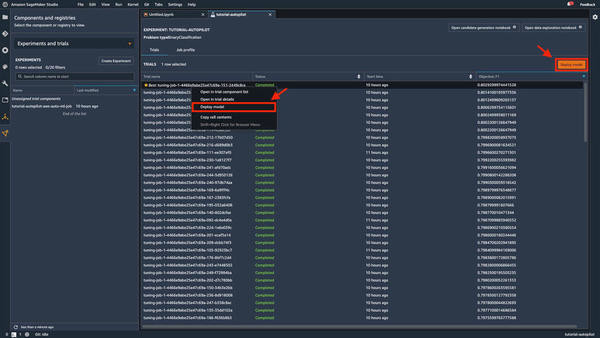 |
ここで、「REALTIME DEPLOYMENT SETTINGS」でデプロイ(推論エンドポイント) の設定を行います。
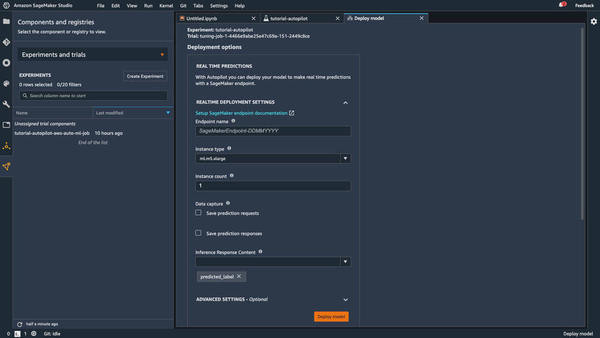 |
ここでも原則としてデフォルト値を設定します。各設定値の説明を簡単にまとめておくので、実際の業務で利用する際は参考にしてください
| 分類 | 設定値名 | 説明 | デフォルト値 |
|---|---|---|---|
| REALTIME DEPLOYMENT SETTINGS | Endpoint name | 推論エンドポイントの名称を設定する。最大63文字まで設定可能であり、英数字もしくはハイフン(-)の利用が可能。1つのAWSリージョンのアカウント内で一意である必要がある | なし(今回は「tutorial-autopilot-best-model」を設定) |
| Instance type | 推論エンドポイントをホストする推論インスタンスのインスタンスタイプを設定する(後述の囲み記事「Instance typeについて」を参照) | ml.m5.xlarge(今回は「ml.m5.large」を設定) | |
| Instance count | 推論エンドポイントをホストする推論インスタンスのインスタンス数を設定する | 1 | |
| Data capture | 推論エンドポイントのリクエストまたはレスポンスを収集してS3バケットに保存する。有効化する場合はAmazon SageMaker Studioがランダムに取得する割合を設定できる ・Save prediction requests ・Save prediction responce |
未選択 | |
| Inference Responce Content | 推論エンドポイントが入力データごとに返す応答コンテンツを設定する ・predicted_label:分類されたクラスのラベル ・probability: 分類されたクラスの確率 ・probabilites: 全てのラベルの確率のリスト ・labels:全てのラベルのリスト |
predicted_label | |
| ADVANCED SETTINGS - Optional | Environment variables - Optional | 推論エンドポイントのDockerコンテナに環境変数を設定する | なし |
| IAM role | 推論エンドポイントに付与するAWSリソースの操作権限を設定したIAM ロールを指定する | Default SageMaker Role | |
| Encryption key - Optional | AWS Key Management Service(KMS)によるデータの暗号化を実施する場合に暗号鍵を指定する | なし | |
| Virtual private cloud(VPC) - Optional | セキュリティ要件などでインスタンスをユーザー管理の VPC 内に配置する必要がある場合に設定する | なし |
設定の完了後に「Deploy model」を選択します。推論インスタンスの作成と機械学習モデルのデプロイが行われます。
 |
上記の画面では進行状況がわかりづらいため、「Experiments and trials」と表示されているプルダウンメニューから、「Endpoint」を選択して移動します。「Endpoint status」が「Creating」から「InService」となれば完了です。
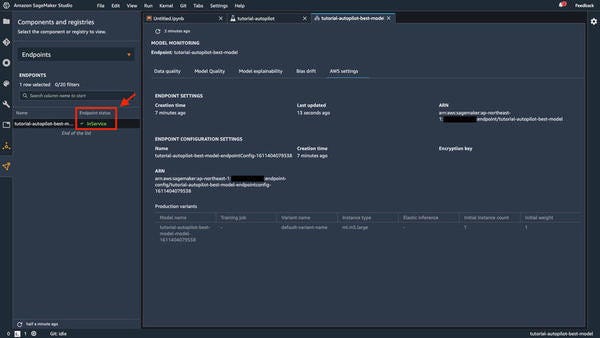 |
Instance typeについて
Instance typeのデフォルト値は「ml.m5.xlarge」ですが、以下のようにリソースの構成上限に抵触してデプロイを行うことができません。
 |
今回は「ml.m5.large」を選択しましたが、実際の業務などで「ml.m5.xlarge」の利用が必要な場合はAWSサポートに上限緩和申請を行ってください。
ステップ7:モデルを使用して予測を行う
推論エンドポイントのデプロイまで完了しましたので、最後に実際に推論を実施して精度を検証してみましょう。
実行するコード
ノートブックのセルに下記のコードをコピー&ペーストして実行してください。なお、「ep_name」はステップ6で設定した「Endpoint name」と一致させる必要があります。
import boto3, sys
ep_name = 'tutorial-autopilot-best-model' #(著者追記) ステップ6で設定した「Endpoint name」と一致させること
sm_rt = boto3.Session().client('runtime.sagemaker')
tn=tp=fn=fp=count=0
with open('bank-additional/bank-additional-full.csv') as f:
lines = f.readlines()
for l in lines[1:2000]: # Skip header
l = l.split(',') # Split CSV line into features
label = l[-1] # Store 'yes'/'no' label
l = l[:-1] # Remove label
l = ','.join(l) # Rebuild CSV line without label
response = sm_rt.invoke_endpoint(EndpointName=ep_name,
ContentType='text/csv',
Accept='text/csv', Body=l)
response = response['Body'].read().decode("utf-8")
#print("label %s response %s" %(label,response))
if 'yes' in label:
# Sample is positive
if 'yes' in response:
# True positive
tp=tp+1
else:
# False negative
fn=fn+1
else:
# Sample is negative
if 'no' in response:
# True negative
tn=tn+1
else:
# False positive
fp=fp+1
count = count+1
if(count % 100 == 0):
sys.stdout.write(str(count)+' ')
print("Done")
accuracy =(tp+tn)/(tp+tn+fp+fn)
precision = tp/(tp+fp)
recall = tn/(tn+fn)
f1 =(2*precision*recall)/(precision+recall)
print("%.4f %.4f %.4f %.4f" %(accuracy, precision, recall, f1))
推論が100個行われるごとに数字が表示され、「Done」が表示されると完了です。表示される4つの数字は、左から「正確度(accuracy)」「適合率(precision)」「再現率(recall)」「F1値(F-measure)」を表します。
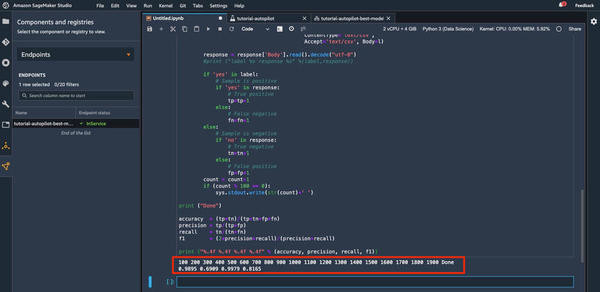 |
コードの解説
ここでは、「bank-additional-full.csv」のヘッダ行を除いた最初の2,000行を精度検証用のテストデータとして利用しています※ 。
response = sm_rt.invoke_endpoint(EndpointName=ep_name,
ContentType='text/csv',
Accept='text/csv', Body=l)
AWS SDK for Python(Boto3)のSageMakerRuntimeクラスのinvoke_endpointメソッドを使ってテストデータを1行ずつ推論エンドポイントに送信し、その応答として推論結果を取得しています。
if 'yes' in label:
# Sample is positive
if 'yes' in response:
# True positive
tp=tp+1
else:
# False negative
fn=fn+1
else:
# Sample is negative
if 'no' in response:
# True negative
tn=tn+1
else:
# False positive
fp=fp+1
上記のコードでは、推論結果を基にして混同行列を計算しています。前回のチュートリアルではPandasのcrosstab関数を使っていましたが、今回のチュートリアルでは手動で計算を行っています。
混同行列
混同行列については本連載の第8回で解説しましたが、以下に再掲しておきます。
 |
行方向(縦軸)が「正解(観測; Observed)」、列方向(横軸)が「予測(Predicted)」を表します。「正解(2種類) * 予測(2種類)」で、以下の4つの指標があります。
- True Positive(TP):定期預金を申し込むと予測して、実際に申し込んだ顧客の数
- False Poritive(FP):定期預金を申し込むと予測したが、実際には申し込まなかった顧客の数
- True Negative(TN):定期預金を申し込まないと予測して実際に申し込まなかった顧客の数
- False Negative(FN):定期預金を申し込まないと予測したが、実際には申し込んだ顧客の数
混同行列という名前通り混乱しやすいですが、Positive/Negativeはあくまで「予測」に対してかかっている言葉です。その予測の正解と不正解に応じて、True/Negativeが付いていると考えると理解しやすいと思います。
「正確度(accuracy)」「適合率(precision)」「再現率(recall)」「F1値(F-measure)」は、機械学習モデルの精度を評価する際によく用いられる指標であり、それぞれ下記を意味します。
- 正確度(accuracy):予測したもののうち、正しく定期預金を申し込む/申し込まないを予測できた割合(今回は0.9895)
|
|
- 適合率(precision):定期預金を申し込むと予測したもののうち、正しく定期預金を申し込むと予測できた割合(今回は0.6909)
|
|
- 再現率(recall):実際に定期預金を申し込んだもののうち、正しく定期預金を申し込むと予測できた割合(今回は0.9979)
|
|
- F1値(F-measure):適合率と再現率の調和平均(今回は0.8165)
|
|
今回の精度検証では、正確度と再現率が高い一方で、適合率が低くなっています。適合率の定義は、「定期預金を申し込むと予測したもののうち、正しく定期預金を申し込むと予測できた割合」を表すため、「定期預金を申し込むと予測した誤検出」が多いと言えます。
本連載の第8回で確認したように、このチュートリアルのデータは「定期預金を申し込んだ顧客」のデータ数が不足している「不均衡データ」でした。このデータはオープンデータなのでデータ数を増やすことはできませんが、実際の業務で同様の事象が発生した場合は、定期預金を申し込んだ顧客のデータ数を増やすと指標値が改善する可能性があります。
※ 厳密に言うと、このように学習に用いたデータを精度検証に用いるのは正しい方法ではありません。今回はチュートリアルに従いましたが、正しく評価するためには、本連載の第6回で紹介したようにNumPyのメソッドやPandasのsampleメソッドを使うなどして、学習に利用しなかったデータをテストデータに採用して精度検証を行うべきでしょう。
ステップ8:クリーンアップ
以下が課金要素となるため、必要に応じて削除を行います。
- 推論エンドポイント
- S3バケットに格納したデータ
ノートブックのセルに次のコードをそれぞれコピー&ペーストして実行してください。なお、「ACCOUNT_NUMBER」部分はご自身のAWSアカウントの12ケタの数字に読み替えてください。
sess.delete_endpoint(endpoint_name=ep_name)
%%sh
aws s3 rm --recursive s3://sagemaker-ap-northeast-1-ACCOUNT_NUMBER/sagemaker/tutorial-autopilot/
また、Amazon SageMaker Studioを削除する場合は、以下の手順で行います。
「SageMaker Studio コントロールパネル」に移動し、削除対象の「ユーザー名」を選択します。
 |
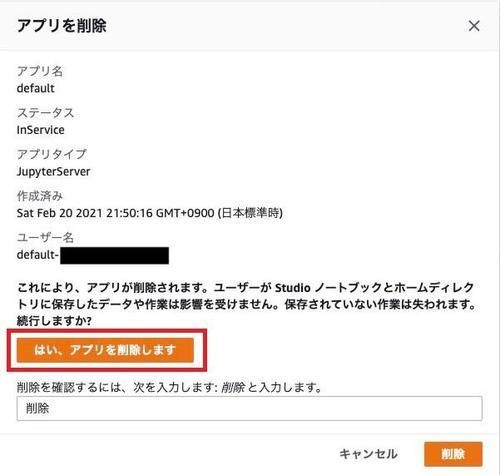
下図の赤枠内に示す「アプリを削除」を選択します。
 |
下図の赤枠内に示す「はい、アプリを削除します」を選択し、テキストボックスに「削除」と入力して、「削除」を選択します。
 |
数分程度待って、アプリの「ステータス」が「Deleted」になったことを確認できたら、「ユーザーを削除」を選択します。
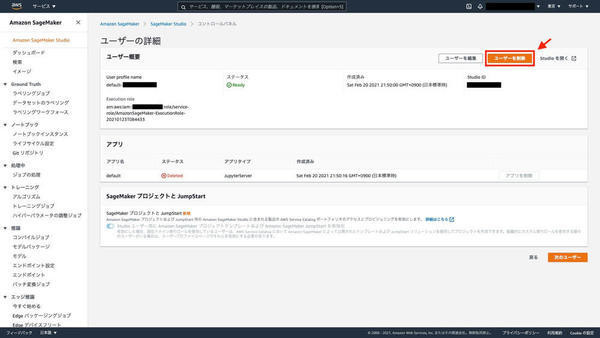 |
下図の赤枠内に示す「はい、ユーザーを削除します」を選択し、テキストボックスに「削除」と入力して、「削除」を選択します。
 |
* * *
第10回から今回まで、4回にわたってAmazon SageMaker Studioの基本的な使い方について解説しました。途中、Amazon SageMaker Autopilotも扱いましたが、データの準備と簡単な設定で機械学習モデルの構築ができることがおわかりいただけたのではないでしょうか。ぜひご自身でもチュートリアルを試し、実業務への活用につなげていってください。
著者紹介
 |
菊地 貴彰 (KIKUCHI Takaaki) - 株式会社NTTデータ
システム技術本部 デジタル技術部
Agile プロフェッショナル担当
大学・大学院では、機械学習を専攻。ベイズ的枠組みを用いて、複数の遺伝子のデータから遺伝子どうしの相互作用ネットワークの推定に関する研究を行った。
株式会社NTTデータに入社後は、法人や金融のシステム開発のシステム基盤担当としてキャリアを積み、現在はデジタル技術やAgile開発を専門に扱う組織でシステム開発全般を担当する。
2019, 2020 APN AWS Top Engineers, Japan APN Ambassador 2020に選出に選出。
本連載の内容に対するご意見・ご質問はtwitter: @kikuchitk7まで。




