



前回はAnalyzerの仕組みについて理解していただきました。今回はそれを踏まえて、実際にFessが日本語文書に適用しているAnalyzerについて説明します。
Fessは国際化されたソフトウェアなので、日本語以外にもさまざまな言語のAnalyzerを定義しています(執筆時点では37言語に対応)。Fessのインデックスは、以下の2種類のAnalyzerでトークナイズされたインデックスで構成されています。
- 各言語用のAnalyzer: 日本語の場合、形態素解析による分割
- 全言語共通のAnalyzer: 2-gramベースの分割
検索対象のドキュメントの言語を自動判定して、その言語用Analyzerと言語共通Analyzerでインデックスして、それらにOR検索することで検索システムを実現しています。
Analyzerの定義
今回はFess 12.1.2を利用して説明します。
FessのZIPファイルはダウンロードページから入手することができます。ZIPファイルを展開して、bin/fess.[sh|bat]を実行して起動してください。
FessのElasticsearchにアクセスして、日本語Analyzerの動作を確認してみましょう。
単語分割の確認はElasticsearchのAnalyze APIを利用します。 Fessの日本語Analyzerはjapanese_analyzerで定義されているので、analyzerで指定して以下のリクエストを実行します。
$ curl -XGET 'localhost:9201/fess.search/_analyze?pretty' -H 'Content-Type: application/json' -d'
{
"analyzer" : "japanese_analyzer",
"text" : "東京スカイツリーの①番出口"
}'
{
"tokens" : [
{
"token" : "東京",
"start_offset" : 0,
"end_offset" : 2,
"type" : "word",
"position" : 0
},
{
"token" : "スカイ",
"start_offset" : 2,
"end_offset" : 5,
"type" : "word",
"position" : 1
},
{
"token" : "ツリー",
"start_offset" : 5,
"end_offset" : 8,
"type" : "word",
"position" : 2
},
{
"token" : "1",
"start_offset" : 9,
"end_offset" : 10,
"type" : "word",
"position" : 4
},
{
"token" : "番",
"start_offset" : 10,
"end_offset" : 11,
"type" : "word",
"position" : 5
},
{
"token" : "出口",
"start_offset" : 11,
"end_offset" : 13,
"type" : "word",
"position" : 6
}
]
}
分割された単語はtokens配列のtokenの値として格納されます。「東京スカイツリーの①番出口」の文字列をトークナイズして、半角カタカナが全角カタカナに変換もされているのがわかります。
検索エンジンはこの単語でインデックスを作成し、検索しています。
Analyzer: japanese_analyzer
まずはjapanese_analyzerがどのように定義されているかを見ていきます。
Fessの検索で利用される各種Analyzerはapp/WEB-INF/classes/fess_indices/fess.jsonで定義されています。
japanese_analyzerは以下のように定義されています。
"japanese_analyzer": {
"type": "custom",
"char_filter": [
"mapping_ja_filter",
"fess_japanese_iteration_mark"
],
"tokenizer": "japanese_tokenizer",
"filter": [
"truncate10_filter",
"fess_japanese_baseform",
"fess_japanese_stemmer",
"japanese_pos_filter",
"lowercase"
]
},
前回説明したように、AnalyzerはCharFilter、TokenizerおよびTokenFilterで構成されています。上記のjapanese_analyzerの構成内容を順に見ていきましょう。
CharFilter: mapping_ja_fileter
japanese_analyzerで一番始めに適用される処理がmapping_ja_filterです。
このCharFilterはapp/WEB-INF/classes/fess_indices/fess/ja/mapping.txtの内容に基づいて文字を置換しています。mapping.txtには全角英数字を半角英数字に変換するなど、日本語観点での文字の正規化を定義しています。
"mapping_ja_filter": {
"type": "mapping",
"mappings_path": "${fess.dictionary.path}ja/mapping.txt"
},
CharFilter: fess_japanese_iteration_mark
fess_japanese_iteration_markはanalysis-fessプラグインが提供するビルドインのCharFilterで、踊り文字を正規化します。たとえば、「日々」を「日日」に変換するなどです。内部的にはkuromoji_iteration_markと同様の機能を提供しています。
fess_[lang]_*で定義されたものがいくつかありますが、これらはElasticsearchプラグインのインストール状況により適用される機能が切り替わります。 日本語の場合は、analysis-kuromoji-neologdプラグインがインストールされている場合はNEologd辞書が適用されたKuromojiが利用され、なければ通常のKuromojiが適用されます。
Tokenizer: japanese_tokenizer
japanese_tokenizerはanalysis-fessプラグインが提供するfess_japanese_reloadable_tokenizerのTokenizerです。標準ではanalysis-jaプラグインが提供する、辞書が自動再読込されるreloadable_kuromojiが利用されます。 機能的にはkuromojiと同様です。
"japanese_tokenizer": {
"type": "fess_japanese_reloadable_tokenizer",
"mode": "normal",
"user_dictionary": "${fess.dictionary.path}ja/kuromoji.txt",
"discard_punctuation": false,
"reload_interval":"1m"
},
ユーザ辞書はapp/WEB-INF/classes/fess_indices/fess/ja/kuromoji.txtを利用して、1分間隔で更新チェックを行い、更新されていればTokenizerの辞書情報が更新されます。
modeについては、normalは通常の形態素解析による分割、searchは複合語の場合には分割、extendedは未知語を1-gramに分割があり、normalを利用しています。
discard_punctuationは句読点を削除するかを指定しています。
TokenFilter: truncate10_filter
ここからがTokenFilterの処理になります。
japanese_tokenizerが分割した単語単位に処理していきます。
truncate10_filterは10文字以上の単語については切り捨てて10文字にします。
"truncate10_filter" : {
"type" : "truncate",
"length" : 10
},
10文字以上の単語は同じ単語の扱いになってしまいますが、Fessでは分割されない10文字以上の単語を検索したいケースが少ないと考えています。
もし、長い単語を検索したい要件がある場合は、上限を増やすなどを検討してください。
TokenFilter: fess_japanese_baseform
fess_japanese_baseformはkuromoji_baseformと同様です。
単語を原形にします。たとえば、「走って」は「走る」に変換されます。
TokenFilter: fess_japanese_stemmer
fess_japanese_stemmerはkuromoji_stemmerと同様です。
指定した文字数以上(デフォルトは4文字以上)の単語で長音記号を取り除きます。たとえば、「サーバー」は「サーバ」に変換されます。
TokenFilter: japanese_pos_filter
japanese_pos_filterはstoptagsで指定した品詞の単語を取り除くTokenFilterで、以下のように定義しています。
"japanese_pos_filter" : {
"type" : "fess_japanese_part_of_speech",
"stoptags" : [
"その他", "その他-間投", "フィラー", "感動詞", "記号", "記号-アルファベット",
"記号-一般", "記号-括弧開", "記号-括弧閉", "記号-句点", "記号-空白", "記号-読点",
"形容詞", "形容詞-接尾", "形容詞-非自立", "語断片", "助詞", "助詞-格助詞",
"助詞-格助詞-一般", "助詞-格助詞-引用", "助詞-格助詞-連語", "助詞-間投助詞",
"助詞-係助詞", "助詞-終助詞", "助詞-接続助詞", "助詞-特殊", "助詞-副詞化",
"助詞-副助詞", "助詞-副助詞/並立助詞/終助詞", "助詞-並立助詞", "助詞-連体化",
"助動詞", "接続詞", "接頭詞", "接頭詞-形容詞接続", "接頭詞-数接続",
"接頭詞-動詞接続", "接頭詞-名詞接続", "動詞-接尾", "非言語音", "連体詞"
]
},
品詞情報はjapanese_tokenizerで付加されます。助詞などは検索で不要な場合が多いので取り除いています。
記号などを検索したい場合にはstoptagsで対象の品詞を指定しないようにしてください。
TokenFilter: lowercase
ビルドインのTokenFilterで大文字の英数字を小文字に変換します。
以上のように単語を正規化することで適切な検索ができるようになり、不要なものはできるだけ取り除くことでインデックスサイズを削減することができます。
Analyzerを更新する
Fessが定義しているAnalyzerを更新したい場合は、app/WEB-INF/classes/fess_indices/fess.jsonを変更後にfess.YYYYMMDDインデックスを再生成する必要があります。
Fessでインデックスを再構築するには、http://localhost:8080/admin/upgrade/ にアクセスして、以下の図のエイリアス更新を有効にして開始ボタンを押下します。
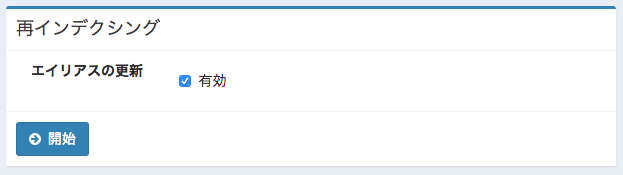 |
再インデクシングの処理状況はダッシュボードで新しいfess.YYYMMDDインデックスが作成されるので、そのドキュメント数で確認できます。
処理が完了すると、fess.searchとfess.updateエイリアスが新しいインデックスに移ります。
問題がなければ古いfess.YYYYMMDDインデックスは削除して問題ありません。
まとめ
今回はFessが利用する日本語用Analyzerについて説明しました。
Fessでの日本語検索の品質を改善したい場合は、japanese_analyzerを調整することで検索結果のスコアリングが改善することができます。
今回の日本語AnalyzerはFessに限らず、Luceneベースの検索を作るときにも役に立つかもしれません。
次回は言語共通で利用しているAnalyzerについて説明していきます。
著者紹介
 |
菅谷 信介 (Shinsuke Sugaya)
Apache PredictionIOにて、コミッター兼PMCとして活動。また、自身でもCodeLibs Projectを立ち上げ、オープンソースの全文検索サーバFessなどの開発に従事。










