



今回は、前回までに作成した「getss.ps1」でWebページのスクリーンショットを取得する処理を改善していく。現状では、Microsoft Edgeのヘッドレスモードを使ってWebページのスクリーンショットを撮っているが、コンテンツによってはこれができない。そうしたコンテンツを避けるように、PowerShellスクリプトの処理を変更する。
前回のgetss.ps1
前回改良したgetss.ps1では、PowerShellスクリプトの内部構造を整理し、Snipping Toolでデスクトップのスクリーンショットを撮るという機能を追加した。
#!/usr/bin/env pwsh
#========================================================================
# スクリーンショットを取得する
#========================================================================
#========================================================================
# 引数を処理
# -URI uri スクリーンショットを取得するリソースのURI
# -Width width スクリーンショットの幅
# -Height height スクリーンショットの高さ
#========================================================================
Param(
[Parameter(Mandatory=$false)][String]$URI = "desktop:",
[Int]$Width = 1200,
[Int]$Height = 800
)
#========================================================================
# デフォルトのスクリーンショットファイル
#========================================================================
$outfile="${env:HOME}/ss.png"
#========================================================================
# スクリーンショットの取得に利用するアプリケーション
#========================================================================
$msedge='C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe'
$snippingtool='SnippingTool.exe'
#========================================================================
# どの方法でスクリーンショットを取得するか判断
#========================================================================
switch -Wildcard ($URI)
{
'http*'
{
#========================================================
# Microsoft Edgeを使って取得
#========================================================
$method='msedge'
break
}
'desktop:*'
{
#========================================================
# Snipping Toolを使って取得
#========================================================
$method='snippingtool'
break
}
}
#========================================================================
# スクリーンショットを取得
#========================================================================
switch ($method)
{
#================================================================
# Microsoft Edgeを使って取得
#================================================================
'msedge'
{
$o1='--headless'
$o2='--screenshot="' + ${outfile} + '"'
$o3="--window-size=${Width},${Height}"
Start-Process -FilePath $msedge `
-ArgumentList $o1,$o2,$o3,$URI `
-Wait
break
}
#================================================================
# Snipping Toolを使って取得
#================================================================
'snippingtool'
{
Start-Process -FilePath $snippingtool
# ※ -Waitは指定しても機能しない
break
}
}
Webリソース以外のスクリーンショットも取得できるようにするため、引数で取っていたURLをURIへ拡張し、内部のフローを再整理した。今回は、これにWebコンテンツの種類を判定する処理を追加する。
Microsoft Edgeのヘッドレスモードでは取得できない
Microsoft Edgeのヘッドレスモードでは、スクリーンショットを取得できないケースがある。例えば、MIMEタイプがtext/htmlに分類されるリソースは取得することができるのだが、PDFやCSVといったデータは今のところ取得できない。将来的には取得できるようになるかもしれないが、今のところは無理なのだ。
処理は、「netcat.ps1」を作ったときと同じように実装する。まず、URIの拡張子などからMIMEタイプが明確なものについては、その段階でMIMEタイプを定めてしまう。処理の高速化のためだ。ここでMIMEタイプが判断できないものについては、curlでWebサーバに問い合わせてMIMEタイプを取得する。
MIMEタイプが確定したら、次はMIMEタイプに従って処理を分ける。ここではMIMEタイプがtext/htmlとtext/plainの場合のみ、処理をこれまで通り続けることにして、それ以外の場合には代わりに「http://example.com/」のスクリーンショットを撮るようにする。ここの処理は何でもよいのだが、実装しやすいのでとりあえずこうしておく。
コンテンツ種類の判断とそれを利用する処理へ変更していく
では書き換えだ。今回の目的に一致するようにgetss.ps1を書き換えていく。netcat.ps1で実装したものと似ているので、そこからコードを持ってきて書き換える方法で十分に対応できる。
まず、コンテンツ種類の確認にcurl.exeを使うので、このコマンドパスを変数に代入しておく。
#========================================================================
# スクリーンショットの取得に利用するアプリケーションほか
#========================================================================
$msedge='C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe'
$snippingtool='SnippingTool.exe'
$curl='C:\Windows\System32\curl.exe'
次に、引数に指定されたURIからコンテンツタイプを判断する処理を追加する。これは、netcat.ps1に追加したものとほぼ同じでよいと思う。拡張子が「.html」「.htm」「.shtml」になっていれば「text/html」、「/」で終わっていても「text/html」、「.txt」で終わっていれば「text/plain」とする。


#========================================================================
# スクリーンショットを撮るリソース種類の特定
#========================================================================
$contenttype='none'
switch -Wildcard ($URI)
{
#================================================================
# コンテンツの種類を特定
#================================================================
'http*.html'
{
$contenttype='text/html'
break
}
'http*.htm'
{
$contenttype='text/html'
break
}
'http*.shtml'
{
$contenttype='text/html'
break
}
'http*/'
{
$contenttype='text/html'
break
}
'http*.txt'
{
$contenttype='text/plain'
break
}
'http*.csv'
{
$contenttype='text/csv'
break
}
'http*csv=1'
{
$contenttype='text/csv'
break
}
'http*.pdf'
{
$contenttype='application/pdf'
break
}
'http*.zip'
{
$contenttype='application/zip'
break
}
default
{
$contenttype=( & $curl --location `
-Ss -I `
$URI |
Select-String "^Content-Type:" )
break
}
}
拡張子が「.csv」「.pdf」「.zip」だった場合にはそれぞれ「text/csv」「application/pdf」「application/zip」を設定しておく。これらはMicrosoft Edgeのヘッドレスモードではスクリーンショットが取得できないので、処理を高速化するためにURIの段階で判断して対象から外しておく。
それ以外の場合には、curlでWebサーバに問い合わせてコンテンツタイプを取得する。そして、判定したコンテンツ種類が「text/html」「text/plain」以外だった場合には、URIを「http://example.com/」に書き換えるようにする。
#========================================================================
# スクリーンショットが取れないWebリソースの場合、代わりに
# http://example.com/ のスクリーンショットを取っておく
#========================================================================
switch -Wildcard ($contenttype)
{
#================================================================
# コンテンツの種類を特定
#================================================================
'*text/html*'
{
break
}
'*text/plain*'
{
break
}
'*/*'
{
$URI='http://example.com/'
break
}
}
PDFやCSVといったコンテンツのスクリーンショットを取る必要が出てきた場合には、この部分でさらに処理を切り分けて($methodを書き換えるなど)対応する。例えば、PDFだった場合には一旦ダウンロードしてPDFビューアで開いてからスクリーンショットを取るとか、画像処理プログラムでスクリーンショットに変換するとかだ。
こうした処理は必要に応じて将来対応することにする。今は、PowerShellスクリプトの構造がそうした処理の追加を行いやすいように整理され、読みやすい状態になっていればよい。
新しいgetss.ps1へまとめる
これら書き換えをgetss.ps1へまとめると次のようになる。
#!/usr/bin/env pwsh
#========================================================================
# スクリーンショットを取得する
#========================================================================
#========================================================================
# 引数を処理
# -URI uri スクリーンショットを取得するリソースのURI
# -Width width スクリーンショットの幅
# -Height height スクリーンショットの高さ
#========================================================================
Param(
[Parameter(Mandatory=$false)][String]$URI = "desktop:",
[Int]$Width = 1200,
[Int]$Height = 800
)
#========================================================================
# デフォルトのスクリーンショットファイル
#========================================================================
$outfile="${env:HOME}/ss.png"
#========================================================================
# スクリーンショットの取得に利用するアプリケーションほか
#========================================================================
$msedge='C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe'
$snippingtool='SnippingTool.exe'
$curl='C:\Windows\System32\curl.exe'
#========================================================================
# どの方法でスクリーンショットを取得するか判断
#========================================================================
switch -Wildcard ($URI)
{
'http*'
{
#========================================================
# Microsoft Edgeを使って取得
#========================================================
$method='msedge'
break
}
'desktop:*'
{
#========================================================
# Snipping Toolを使って取得
#========================================================
$method='snippingtool'
break
}
default
{
$method='none'
}
}
#========================================================================
# スクリーンショットを撮るリソース種類の特定
#========================================================================
$contenttype='none'
switch -Wildcard ($URI)
{
#================================================================
# コンテンツの種類を特定
#================================================================
'http*.html'
{
$contenttype='text/html'
break
}
'http*.htm'
{
$contenttype='text/html'
break
}
'http*.shtml'
{
$contenttype='text/html'
break
}
'http*/'
{
$contenttype='text/html'
break
}
'http*.txt'
{
$contenttype='text/plain'
break
}
'http*.csv'
{
$contenttype='text/csv'
break
}
'http*csv=1'
{
$contenttype='text/csv'
break
}
'http*.pdf'
{
$contenttype='application/pdf'
break
}
'http*.zip'
{
$contenttype='application/zip'
break
}
default
{
$contenttype=( & $curl --location `
-Ss -I `
$URI |
Select-String "^Content-Type:" )
break
}
}
#========================================================================
# スクリーンショットが取れないWebリソースの場合、代わりに
# http://example.com/ のスクリーンショットを取っておく
#========================================================================
switch -Wildcard ($contenttype)
{
#================================================================
# コンテンツの種類を特定
#================================================================
'*text/html*'
{
break
}
'*text/plain*'
{
break
}
'*/*'
{
$URI='http://example.com/'
break
}
}
#========================================================================
# スクリーンショットを取得
#========================================================================
switch ($method)
{
#================================================================
# Microsoft Edgeを使って取得
#================================================================
'msedge'
{
$o1='--headless'
$o2='--screenshot="' + ${outfile} + '"'
$o3="--window-size=${Width},${Height}"
Start-Process -FilePath $msedge `
-ArgumentList $o1,$o2,$o3,$URI `
-Wait
break
}
#================================================================
# Snipping Toolを使って取得
#================================================================
'snippingtool'
{
Start-Process -FilePath $snippingtool
# ※ -Waitは指定しても機能しない
break
}
}
多少スクリプトは長くなったが、処理自体はシンプルだ。
動作を確認する
作成したPowerShellスクリプトの動作を確認してみよう。次のURLのスクリーンショットを取得するケースを考える。
Microsoft Edgeで閲覧すると、次のようにPDFビューアがMicrosoft Edge内部で起動して閲覧できる状態になる。
-

Securing the Software Supply Chain: Recommended Practices Guide for Developers - PDFの閲覧状態

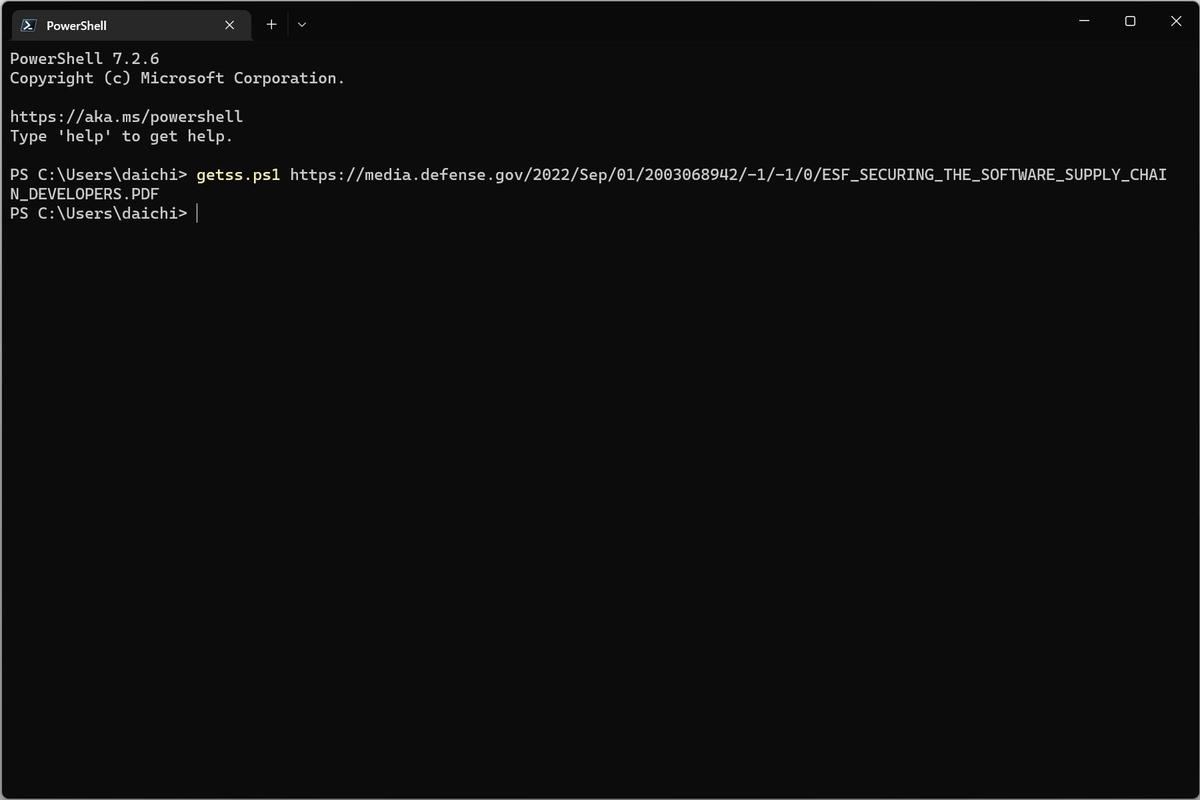
このURLをgetss.ps1に指定してスクリーンショットを取得しようとすると、次のようになる。
getss.ps1でPDFのスクリーンショットの取得を試みる
getss.ps1 https://media.defense.gov/2022/Sep/01/2003068942/-1/-1/0/ESF_SECURING_THE_SOFTWARE_SUPPLY_CHAIN_DEVELOPERS.PDF
-
getss.ps1でPDFのスクリーンショットの取得を試みる

getss.ps1を実行することで次のスクリーンショットが得られる。
-
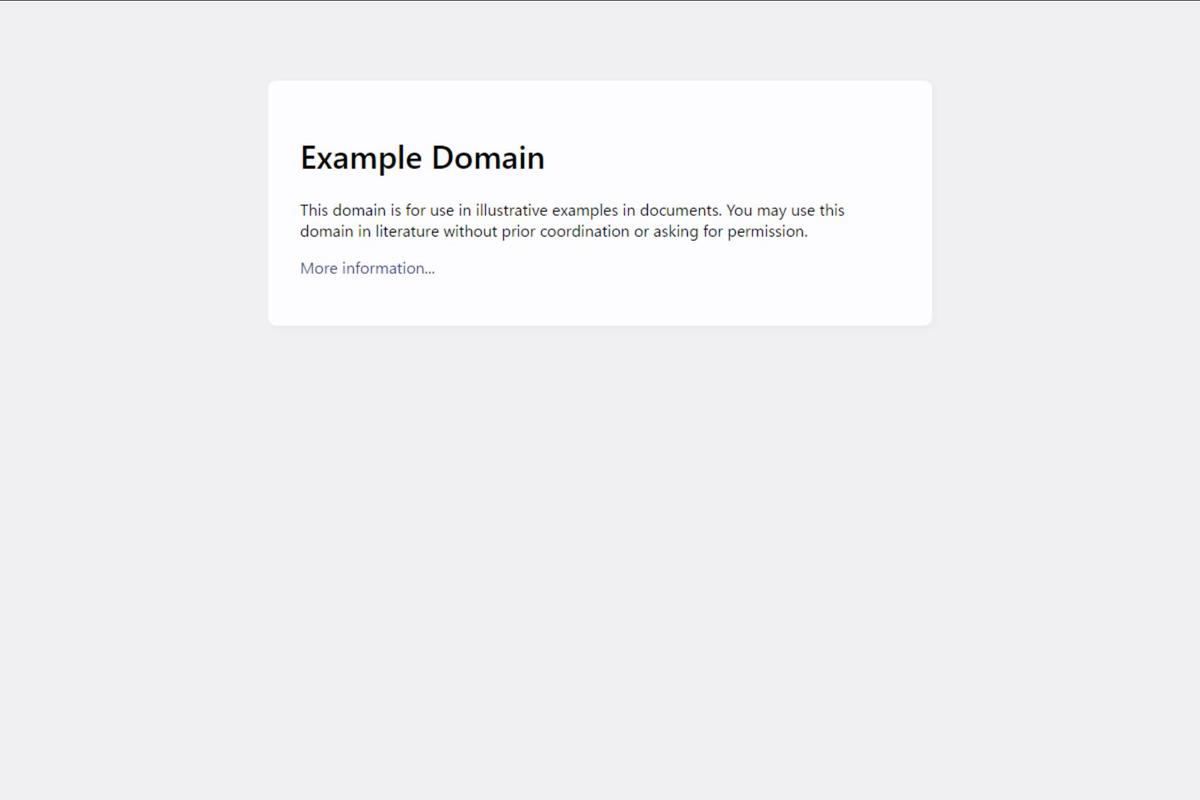
getss.ps1を実行した結果得られたスクリーンショット

PDFのスクリーンショットはMicrosoft Edgeのヘッドレスモードでは取得できないため、処理の途中で「http://example.com/」のURLへと置き換わり、そのスクリーンショットが取得されている。想定した通りの動作になった。
今回、取得できないURIを「http://example.com/」へと置き換えたのには、ちゃんと理由がある。取得できないURIに対してスクリーンショットを取得しようとすると、Microsoft Edgeの処理が固まったような動作になるのだ。スクリプトを改善していく際、問題となりそうな部分を先に解消しておくことも、大切なポイントなのである。










