今回は簡単なコマンドwcです。wcは文字数をカウントするという至ってシンプルな機能を持つコマンドです。wcのコマンド名もそのままWord Countを略したものなので覚えるのも簡単です。wcコマンドは文字数だけでなく行数などもカウントすることができます。Windows系には標準コマンドとしては該当する機能のコマンドは存在しないようですが、PowerShellならCount、Length、Measure-Objectで取得できます。なお、PowerShellについては次回説明します。
今回もこれまでのようにサンプルで利用するファイル・ディレクトリはデスクトップのsampleディレクトリとしています。デスクトップにsampleディレクトリがない場合は作成しておいてください(コマンド入力ならmkdir ~/Desktop/sampleとして作成することができます)。
また、カレントディレクトリも上記の場所になります。cd ~/Desktop/sampleのようにコマンドを入力してカレントディレクトリを変更しておけばよいでしょう。


文字数・行数などをまとめてカウント
wcコマンドでカレントディレクトリにある1.txtの文字数や行数を表示させてみましょう。この場合、wcの後にファイル名を指定するだけです。
wc 1.txt



タブで区切られた4つのデータが表示されていますが、左側から行数・単語数・バイト数・ファイル名になります。日本語の場合は単語数、バイト数はあまり意味がないかもしれません。
wcコマンドでの行数カウントには注意が必要です。というのもテキストによっては正しい行数にならないことがあるからです。wcコマンドがカウントする行数は改行コードなので行末(ファイルの最後)に改行コードがないと行数を正しくカウントすることができません。今回使用しているテキストファイルはいずれもファイルの最後に改行が入っています。最後に改行コードが入っていない場合でも行数をカウントするには以下のようにします。なお、1b.txtファイルの最後には改行コードは入っていません。
grep '' 1b.txt|wc -l






本当にwcコマンドが改行コードだけをカウントしているか気になる人は以下のURLにwcコマンドのソースリストがありますのでチェックしてみるとよいでしょう。macOSのwcコマンドの方がシンプルで読みやすいと思います。
・macOS (BSD)
https://opensource.apple.com/source/text_cmds/text_cmds-99/wc/wc.c.auto.html・Linux
https://github.com/coreutils/coreutils/blob/master/src/wc.c




バイト数を出力
文字数ではなくバイト数(1バイト=8ビット)だけを出力するには-cを指定します。以下のようにするとカレントディレクトリにある1.txtファイルのバイト数を表示します。
wc -c 1.txt





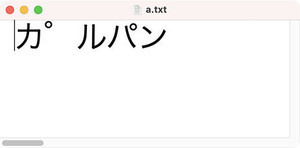
1.txtファイルの内容は英文字だけでしたが、日本語のマルチバイト文字の場合も確認してみましょう。2.txtファイルには図のように7文字の日本語が書かれています。バイト数は21と表示されます。1文字あたり3バイト使っているようです。
wc -c 2.txt



本当に1文字3バイトなのか確認してみましょう。図のように「あ」の1文字だけ入れた2b.txtファイルを用意します。実行すると3と表示されるので「あ」は3バイトのようです。
wc -c 2b.txt



それでは次にマルチバイトのテストには便利(?)な絵文字です。ニコニコ顔の絵文字を1つだけ入力したファイルを用意します。実行すると5と表示されるのでこの絵文字は5バイトのようです。
wc -c 3.txt



3バイトだ、4バイトだと言われても本当なの?と疑い深い人もいるかもしれません。特に過去にマルチバイト(ShiftJIS,EUC,JIS等)、そしてUnicodeに悩まされた経験がある人はそう考えてしまいそうです。ということで16進数としてファイル内容を表示するコマンド(ここではhexdump)を使ってそれぞれのファイルの内容を表示して確認してみましょう。結果はwcコマンドでの結果と同じバイト数です。
hexdump 1.txt

hexdump 2.txt

hexdump 2b.txt

hexdump 3.txt

実行結果を見ると絵文字なども問題なくカウントされています。
文字数だけ出力
-cではバイト数を表示しますが、実際には入力した文字数を知りたい用途の方が多いでしょう。文字数だけを出力する場合にはmオプションを指定します。絵文字や日本語を含むマルチバイト文字の場合はmを指定しないと正しい文字数になりません。
wc -m 1.txt



wc -m 2.txt



ところで気になるのは先ほどと同様、UTF-8でのマルチバイト文字が正しく処理されるかどうかです。例えば絵文字が正しく1文字としてカウントされるかどうかということです。先ほどと同様のファイルでそれぞれの結果を確認してみましょう。
wc -m 2b.txt



wc -m 3.txt



絵文字1文字は1文字とカウントされています。期待通りの結果です。
行数だけ出力
wcコマンドで行数だけを出力する場合にはlオプションを指定します。なお、最初にも書きましたがファイル末尾に改行コードがない場合は正しい行数がカウントされません。
wc -l 1.txt



直接入力した文字数をカウントする
wcコマンドはファイル名を指定せずに、そのまま入力すると標準入力からテキストデータを受け付けます。wcとだけ入力するとテキスト入力状態になります。文字を入力し最後にcontrolキーを押したままdキーを押すと文字数などがカウントされます。
wc







複数ファイルをまとめてカウント
複数ファイルの行数や文字数をまとめてカウントして合計を表示することもできます。この場合はシェルのワイルドカードを使えば簡単に実現できます。
wc *.txt




行数だけ、文字数だけをカウントすることもできます。この場合はオプションを指定するだけです。
wc -l *.txt




wcコマンドを実行すると対象となるファイル名まで出力されています。場合によってはファイル名は不要で単純な文字数・行数、合計の行数だけが欲しい場合もあります。この場合はcatコマンドと組み合わせます。
cat 1.txt | wc
cat 1.txt | wc -m
cat 1.txt | wc -l


複数ファイルを対象にすると合計のみが出力されます。
cat *.txt | wc
cat *.txt | wc -m
cat *.txt | wc -l


日本語だと使わない気もしますが、wオプションを指定すれば単語数だけをカウントすることができます。ただし、macOS (BSD)とLinuxでは単語のカウントに違いがあるようで同じ結果にならないことがあります。
wc -w 1.txt
cat 1.txt | wc -w
cat *.txt | wc -w


カレントディレクトリだけでなく、カレントディレクトリ以下のサブディレクトリまで対象にする場合はfindコマンドと組み合わせます。
find . -type f -name '*.txt' | wc -l
なお、findコマンドについては「第24回 ファイルの検索(UNIX系OS)」を参照してください。
次回はPowerShellで文字数・行数をカウントしてみます。
著者 仲村次郎
いろいろな事に手を出してみたものの結局身につかず、とりあえず目的の事ができればいいんじゃないかみたいな感じで生きております。