



米オラクルは1月23日(現地時間)、生成AIサービスとして、「Oracle Cloud Infrastructure (OCI) Generative AI」の一般提供開始、「OCI Generative AI Agents」と「OCI Data Science AI Quick Actions」のベータ版提供開始を発表した。
「Oracle Cloud Infrastructure (OCI) Generative AI」は、CohereおよびMeta Llama 2の大規模言語モデル(LLM)をシームレスに統合するフルマネージド・サービス。「Oracle Cloud」で利用できるほか、「OCI Dedicated Region」を通じてオンプレミス環境でも利用可能。
「OCI Generative AI Agents」は、Gen AI Agent シリーズ初のエージェントで、RAG(検索拡張生成) Agentとなる。
「Announcing: AI Quick Actions for OCI Data Science」は、データ・サイエンス・ノートブックのユーザーインタフェースから、ボタン・クリックで呼び出せるユースケースのコレクション。
オラクルの生成AIサービスの強み

米オラクル AIプラットフォームおよびGenerative AI Service担当バイスプレジデント ヴィノード・マムタニ氏
AIプラットフォームおよびGenerative AI Service担当バイスプレジデント ヴィノード・マムタニ氏は、生成AI分野における同社の強みについて、次のように語った。
「企業が生成AIを活用するには、企業のナレッジ・ベースを活用したLLM の事前トレーニングやファインチューニングが必要だが、それらの継続的なトレーニングは時間がかかり高価という課題がある。オラクルなら、この課題解決を支援できる。なぜなら、われわれはすべてのスタックにAIを導入することができ、ガバナンスセキュリティも考慮して、企業が生成AIを利用することを実現できるからだ」
Oracle CloudのエコシステムにおけるAIのスタックは以下の図の通りだ。AIインフラストラクチャ層を基盤として、その上に、データ、データプラットフォーム、AIサービス、アプリケーションの各層が積み重なっている。
-
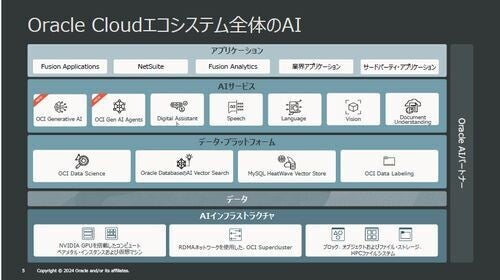
Oracle CloudのエコシステムにおけるAIのスタック

マムタニ氏は、このスタックについて、次のように説明した。
「AIインフラストラクチャ層はGPUを組み込んだOCIが担うが、OCIは競合に対しOCIはGPUのコストパフォーマンスが高い。また、われわれはデータがある場所にAIを組み込むという戦略をとっているので、われわれのスタックではデータを動かす必要がない」
今回発表された3つのサービスは、上記のスタックのAIサービスに属する。
OCI Generative AI
「OCI Generative AI」は9月にベータ版の提供か開始されたが、正式提供に伴い、Meta Llama 2 モデルと Cohere 多言語および英語埋め込みモデル(V3)が新たに追加された。
-

正式提供版に含まれる新しいモデル

モデルは、自社の独自データを活用してファインチューニングを行うことが可能だ。ファインチューニングはCohere Command 52/6Bモデルがリ王可能であり、バニラおよびT-fewのファインチューニング・オプションとパラメータ構成に対応している。トレーニングに使ったデータや推論データは他のユーザーが参照することは不可能であり、Cohere およびMetaにも送信されない。
OCI Generative AI Agents
エージェントは、コール・トランスクリプト、社内ナレッジソースなどのナレッジベースを利用する。2024年1月のベータ版では、 OpenSearch(ベータ版)を含む RAGが利用できる。また、「Oracle Database 23c AI Vector Search MySQL HeatWave Vector Store」の提供が予定されている。
デフォルトでは、OCI Generative AI サービスのモデル (Cohere および Llama 2) を利用するため、独自のモデルを持ち込む必要はない。
また、エージェントは、 ReAct フレームワークに基づいて推論して計画し、一連の思考および行動、観察に基づいてアクションする。
OCI Data Science AI Quick Actions
「CI Data Science AI Quick Actions」は、データ・サイエンス・ノートブックとのシームレスな統合により、 Llama2 や Mistral 7B などのLLM 、ノーコードでアクセスできる。
実行されるクイック・アクションとしては、「デプロイ」「微調整」「統合」「スケール」などがある。
デプロイとしては、Text Generation Inference(Hugging Face)、 vLLM(UC Berkeley) 、 Nvidia Triton を使用したモデル展開をサポートする。
ファインチューニングについては、PyTorchおよび Hugging Face Accelerate による分散トレーニング、DeepSpeed を使用した LLM ファインチューニングが行える。
加えて、オブジェクト・ストレージおよびFile System as a Service のマウントに対応しており、ファインチューニング時の重みの容易なチェックポイントおよび格納が可能となっている。














