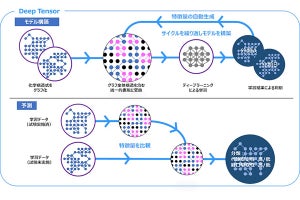
「スパースモデリング」と呼ばれるデータ分析手法をご存知だろうか。わずかなデータからでもAIモデルを構築可能な技術であり、2019年にイベント・ホライズン・テレスコープが公開した、ブラックホールシャドウの撮影に利用された手法としても知られる。
スパースモデリングは膨大な量のデータから学習するディープラーニングとは反対に、わずかなデータ量からでもAIを構築可能であり、AIが結論を導く過程が人間にも理解しやすく、AIのブラックボックス化問題の回避も可能だという。
独自のスパースモデリング技術をAIに応用してデジタルソリューションを開発する、AIスタートアップ HACARUSの代表取締役 CEO 藤原健真氏に、同技術の概要と今後の発展性について話を聞いた。
-

HACARUS 代表取締役 CEO 藤原健真氏

プロフィール
1976年生まれ、滋賀県出身。カリフォルニア州立大学コンピューター科学学部卒業。18歳で単身アメリカに渡り進学。帰国後、ソニー・コンピュータエンタテインメントでエンジニアとしてPlayStationの開発に従事した後、数社のテクノロジーベンチャー企業を共同創業。
京都が持つ大学の技術と知財、ライフサイエンス・モノつくりの経験と知見、優秀な日本人学生と留学生、よその真似をしない独自のビジネス価値観、といった強みを再発見する。2014年に株式会社HACARUSを創立。
趣味はアウトドア、山登り、夜に日本酒を飲みながらのシンセサイザーいじりとテクノ音楽制作。尊敬する経営者は任天堂の故岩田さん。
--スパースモデリングはどのような特徴があるのでしょうか
藤原氏:現在のAI開発の主流な技術であるディープラーニングと大きく異なる点が3つあります。1つ目はAIを構築する際にビッグデータが不要である点、2つ目はAIが結論に至った理由が説明可能である点、3つ目は計算量が少なく消費電力も少ない点です。特に3点目なのですが、現在のままディープラーニングの活用を続けると電力供給が追い付かなくなるかもしれないという試算もあるほどで、エネルギー問題の観点でもスパースモデリングを用いたAIに期待しています。
具体的に他のAI技術とどれだけ異なるかを、太陽光パネルの画像から異常箇所を検出するAIを構築すると仮定して説明します。一般的に、SVM(サポートベクタマシン)やCNN(畳み込みニューラルネットワーク)では、AIが学習するためのデータとして800枚程度の画像が必要とされています。一方でスパースモデリングでは、60枚程度の画像でAIを作ることができます。また、学習のために必要な時間も、SVMでは30分、CNNでは5時間であるのに対して、スパースモデリングでは19秒です。
-

スパースモデリングで構築したAIの特徴

私がスパースモデリングの理屈を説明するときには、関数y=f(x)の例を用いて説明をします。yは導きたい答えで、xはAIが学習する特徴量としての入力値です。一般的なAI開発に用いられるディープラーニングでは、多量のデータからxとyの組み合わせを読み込んで関数の中身を調整します。関数の中身は詳しくはわからないけれど、おそらく適切であろうxとyの関係性を導くようなアプローチです。
犬の画像から犬種を判断するAIをディープラーニングで作ると仮定しましょう。多量の犬種の画像を読み込んで、「Aという特徴を持つ犬はチワワ」「Bという特徴を持つ犬はトイプードル」という組み合わせを関連付けることで、新しい画像を読み込んだ時に「この画像はAの特徴があるからチワワだな」と予測します。特徴量xから適切なyを導くというディープラーニングのアプローチは、数学や統計学の世界では順問題と呼ばれています。
対してスパースモデリングは、逆問題を解こうとするアプローチの手法です。つまり、「導きたい答えであるyは、どのようなxによって特徴づけられているのだろうか?」という考えを基本にしています。スパースモデリングにはビッグデータが不要と言われますが、そもそも多量のデータを用いて問題を解決しようとするアプローチではないのです。答えであるyを特徴づけているのは、どのようなxであるのかを見極める手法です。
-

ディープラーニングとスパースモデリングの差異のイメージ

--どのように特徴を見つけ出しているのですか
藤原氏:実は人間の視点が非常に大切です。例えば、私たちが人の顔を認識する際のことを想像してください。目の前にいる人が誰なのかを識別する場合には目や鼻、口など特定の部位にのみ着目していて、それ以外のおでこや頬の詳細まで詳細に確認して見分けることはしませんよね。スパースモデリングもこれと似たような考え方でAIを構築します。
一方で、さまざまな人の顔のデータを多量に読み込んで、おでこや頬や輪郭の細部まで特徴付けを行うのがディープラーニングの手法です。これが2つの手法で大きく異なる点ですね。スパースモデリングでは、画像のどこに着目して、反対にどこを無視するのかをAIに教えるための作業が必要です。
こうした理由から、当社がスパースモデリングでAIを作る際には、何を特徴として捉えるのかを毎回データ加工する手順を採用しています。MRI画像から腫瘍を見つけるAIを構築する場合には、医師がMRI画像のどこに着目して病巣を見つけているのかを、先生にヒアリングしました。
スパースモデリングを使って少ないデータの量で精度の高いAIを構築するためには、専門家のドメイン知識をAIに落とし込む過程が不可欠です。だからこそ、AIが特定の結果を導出した過程が説明可能で人間にも理解しやすいのです。AIのブラックボックス化を回避できるというのは、こうした理由があるからなのです。私たちはむしろ、データだけを使ってAIを作るということはしないようにしています。
--素晴らしい技術だということがわかりました。今後、スパースモデリングはディープラーニングと逆転するのでしょうか
藤原氏:そうなれば私も嬉しいのですが、どちらの技術にも一長一短がありますので、実際には逆転はしないと思っています。自動車の世界でもそうですが、電気自動車が作られた後もガソリン車は残っていますし、使用用途によってはディーゼル車やハイブリッド車が有効な場面もあります。それと同様で、AIを支える技術も適材適所での活用になると思います。
データが大量に手に入る環境であれば、むしろディープラーニングでAIを構築した方が短期間で正確なAIが作れます。自動運転のAIを作りたい場合には街中の交通情報を集めれば済みますし、AlphaGoのような技術も自動で膨大な量の対局データが取得できます。そのような場合には、わざわざ人間にヒアリングして特徴を絞り込むというスパースモデリングのアプローチよりも、ディープラーニングの方が適切な手段だと考えられますね。
医療の分野では、AIが結論を導き出した過程が説明できないブラックボックスでは困る場面があります。あるいは、希少疾患のようにそもそもデータが多量に取れない場合もあります。こうしたケースではむしろスパースモデリングが適切な手法だと言えるでしょう。先ほどの話に戻りますが、スパースモデリングは消費電力が少なくて済みます。ドローンやウェアラブルデバイスなど、バッテリーの大きさが限られる場面でもスパースモデリングが有効だと思っています。