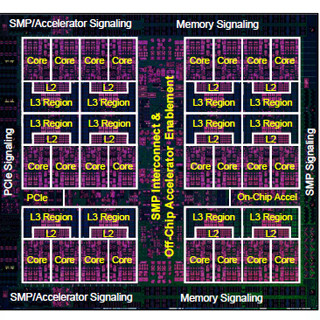
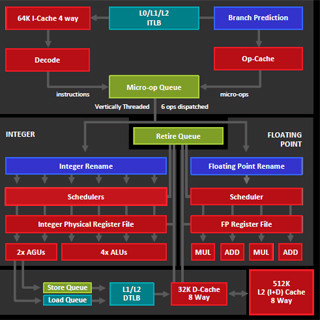
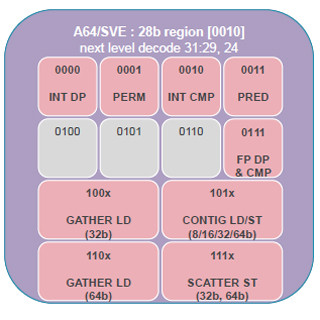
Hot Chips 28において、Baidu(百度)のJian Ouyang氏がソフトウェア定義のSQLアクセラレータについて発表を行った。

|
|
ソフトウェア定義のSQLアクセラレータを発表するBaiduのJian Ouyang氏 |
ビジネスの規模が拡大し、データ量が増加するのに加えて、データを解析するアルゴリズムも複雑になるので、ビッグデータの処理に必要となる計算パワーは加速度的に伸びて行くという。このビッグデータの処理を効率的に行うため、Baiduはソフトウェア定義のアクセラレータを開発した。
Ouyang氏らの分析では、約40%のアナリティックの処理はSQLで記述されており、残りのものも、多くはSQLで書き直すことができる。この分析から、アナリティック用のソフトウェア定義のアクセラレータを作ることが解であると考えたという。

|
|
約40%のデータアナリティックはSQLで記述されており、残りの大部分もSQLで書き直せる。このため、ソフトウェア定義のデータアナリティックのアクセラレータを作ることが解となる (このレポートのすべての図は,Hot Chips 28でのOuyang氏の発表スライドのコピーである) |
ソフトウェア定義のアクセラレータ(Software-Defined Accelerator:SDA)は、Filter、Sort、Aggregate、Join、Group byの機能を担当し、データタイプは、文字、整数、Float/double、ストリングを扱う。

|
|
SQLアクセラレータは、Filter、Sort、Aggregate、Join、Group byを処理する |
SQLのクエリを分析して、アクセラレータで処理できる機能を抽出する。それらの処理はSDA APIで呼び出され、SDA-Driverでハードウェア化された機能を呼び出す。

|
|
SQLクエリを分析し、SDAで処理できる部分を抜き出し、ハードウェアを使えるようにする |
SDAは、列フォーマットのデータを保持するメモリのデータを、PEでFilterやJoinなどの処理を行い、メモリに格納する。そのメモリのデータをPEが処理して、メモリに書き込むというデータフロー的な処理モデルを使っている。
データはPEを搭載したボード上のDDRメモリに格納され、アクセラレータボードの中で処理が行われる。しかし、PEが対応できないSQL処理をホストで行うために、データをホストプロセサのメモリにコピーする機能も持っている。

|
|
列フォーマットのデータを保持するメモリからデータを読み、PEで処理してメモリに書き込むという処理が続くデータフローモデル |
SDAは、物理的にはDDR4メモリとPEがクロスバで繋がっている構造で、これがPCI ExpressでホストCPUに繋がる。ブロック図の右下のCFGはソフトウェア定義の構造をプログラムする部分と考えられる。
PEはFilterならFilterだけ、JoinならJoinだけという単一機能である。データタイプは多種のデータタイプをサポートする。

|
|
SDAは、PEとDDR4メモリがクロスバを介して接続されている構造となっている。PEは単一機能であるが、必要な機能を持つようにプログラムすることができる |
次の図はFilter機能の例であるが、4つの比較器を持ち、その結果を組み合わせて、複雑なフィルタ条件を作り出している。また、中間結果を格納するメモリがあり、中間結果をフィルタ条件に加えることができる。これにより、さらに、複雑なフィルタ条件を作ることができるようになっている。
なお、各フィルタは8行分のデータを入力として扱っている。

|
|
フィルタPEは多数のフィルタと中間結果のメモリを持つ。各フィルタは4つの比較器を持ち、それらの結果を組み合わせて複雑なフィルタ条件を作り出す。さらに、中間結果も入力することで、より複雑な組み合わせが作れる |
SDAは、次の図の写真に見られるようなハーフハイト、ハーフ長のボードで作られており、Xilinxの「Kintex UltraScale KU115」FPGAと4チャネルの72bit DDR4メモリを持つ。メモリ容量は8~32GB、メモリバンド幅は約76GB/sである。そして、ホストとはPCI Express 3.0 x8で繋がっている。

|
|
SDAはハーフハイト、ハーフ長のボードで作られ、XilinxのKU115 FPGAと8~32GBのDDR4メモリを搭載している。ビッグデータ処理に効くメモリバンド幅は約76GB/s |
FPGAロジックのクロックは300MHzである。Filter、Sort、Aggregate、JoinとGroup byを実現するのに必要な資源が次の表に示されているが、LUTの使用率は1.6%~14%である。また、BRAMの使用率は3%~27%で、複数のファンクションをFPGAに搭載することができる。

|
|
FPGAのクロックは300MHz。LUTの使用率は1.6%~14%、BRAMの使用率は2.5%~27%であり、複数のファンクションをFPGAに搭載できる |
システム的には、SDAのドライバ側にPE Viewという管理機能と、処理すべき仕事を格納するキューがあり、キュー単位でFPGAに割り付けて実行させる。

|
|
ドライバ側にPE Viewという管理機能と、処理する仕事のキューがあり、キュー単位でPEに割り付けて実行させる |
次の図はフィルタ機能を作った場合の性能を示すもので、ホストはXeon E5-2620 2ソケットで、合計コア数は12個、クロックは2.0GHz、メインメモリは128GBである。SDAのFPGAには5PEを載せており、クロックは300MHzで動作する。
次の図の左の2つの棒グラフは、マイクロベンチマークでの性能比較である。青がホストのソフトウェアで実行した場合の処理時間、赤がSDAを使った場合の処理時間である。複数の棒グラフがあるが、これは、フィルタで除外するデータの比率が、左端は90%、その右は80%、右端は60%の場合である。
SDAを使った場合、左の5Mレコードの場合は、性能は3~10倍に向上している。中央の80Kレコードのケースでは性能向上は2~3倍になっている。右端はTPC-DSのフィルタの性能比較で、25倍の性能向上が得られている。
ただし、Xeon E5-2620は2012年に発売されたCPUで、最近のCPUを使えば、CPUの性能が上がり、性能比は小さくなると思われる。

|
|
Filterの性能比較。左は5Mレコードの結果で、SDAを使うと3~10倍の性能。中央は80Kレコードの結果で、2~3倍。右端はTPC-DSの性能比較で25倍の性能 |
次の図はSortでの性能比較である。左はマイクロベンチマークでの比較で、データが7Bのストリングの場合は30倍以上の性能であるが、100Bになると3.4倍に低下している。クロックが300MHzと低いので、データ量が多くなると時間が掛かるようである。
右はTerasortの結果で、8倍の性能となっている。

|
|
マイクロベンチマークでのSortの性能比較(左)とTerasortでの性能比較(右)。マイクロベンチマークでの比較ではストリングが7Bと短い場合は30倍以上の性能であるが、100Bと長くなると2.4倍に低下する |
次の図は、TPC-DSのScale=10での性能比較で、単一の機能ではなく、右側のコードに示すようにいくつもの機能が使われている実戦的な使用状況での性能比較である。このケースでは、ホストでは36秒の処理時間が0.65秒に短縮され、55倍の性能向上が得られたという。

|
|
色々な種類の処理が含まれたTPC-DSベンチマークの実行時間が、36秒から0.65秒に短縮され、55倍の性能向上が得られた |
結論であるが、SQLを処理する汎用的なアクセラレータを提案し、SDAのハードウェアとソフトウェアのアーキテクチャを示した。また、FPGAを使ってSDAを開発して、性能を実測した。
SDAはデータフロー処理のプログラムモデルで、オンデマンドでリソースを用意するという処理を行い、分散処理システムにも適している。
なお、筆者らはHot Chips 26において、AI処理用のSDAを発表している。

|
|
SQLを処理するSDAを提案し、FPGAを使った実装を行った。SDAは分散処理システムにも適している |
Hot Chips 28のこの発表の直前にはOracleのSPARC M7プロセサの発表が行われた。Oracleの実装はフルカスタムのCPUへの組み込み、Baiduの発表はFPGAと実装は異なるが、処理の考え方は非常に似通っているのは興味深い。