正規表現を使ったパターンマッチはとても便利なのだが、なんだか難しそうというイメージを持っていないだろうか。正規表現はワイルドカードを拡張したものと考えて基本だけを覚えるだけでも、いろいろな場面で活用できる。今回は、正規表現を使って大量ファイルの自動分類に挑戦してみよう。
-

正規表現でファイルをフォルダに分類したところ

正規表現とは?
正規表現とは文字列を特殊なパターンを使って表現するものだ。ファイル操作に使うワイルドカードを拡張したものと言えば分かりやすいだろうか。今や、正規表現は大抵のテキストエディタに実装されていることもあり、正規表現を覚えるなら、Pythonのプログラミングだけでなく、日々のあらゆる場面で役立つとも言える。
なお、以前本連載の33回目でも正規表現について紹介したが、今回はPythonでファイルを分類する目的のため、基本の基本に絞って紹介しよう。
Pythonで正規表現を使う方法
Pythonで正規表現使うには標準ライブラリの「re」を使う。そして、re.searchメソッドって正規表現検索を行うことができる。以下は、「abc.txt」という文字列が「^a」という正規表現パターンに一致するかをテストするプログラムだ。以下のプログラムを「re_test.py」という名前で保存しよう。
# reモジュールの取り込み
import re
# 正規表現検索を行う
target = "abc.txt"
pattern = "^a"
if re.search(pattern, target) is None:
print("マッチしない")
else:
print("マッチした")
プログラムを実行するにはコマンドラインで「python3 re_test.py」とコマンドを入力するかIDLEを起動してファイルを選択して実行する。
ここでは「^a」という正規表現パターンを指定している。この「^」は文字列の先頭を意味するパターンだ。つまり、「^a」と書くとaから始まる文字列かどうかという意味になる。
ファイル一覧から特定のパターンのものだけを選んで表示しよう
もう一つ簡単なプログラムで確認してみよう。以下のプログラムは、ファイル一覧を表す配列filesの中で拡張子「.txt」で終わるものだけを選んで表示する例だ。以下を「filter.py」という名前で保存しよう。
import re
# ファイルの一覧
files = ["aaa.mp3", "bbb.txt", "200abc.txt",
"201eee.txt", "aaa.txt", "200.mp3"]
# 拡張子「.txt」のものだけを表示
for f in files:
if re.search(r'\.txt$', f):
print(f)
プログラムを実行するにはIDLEを使うか、コマンドラインで「python3 filter.py」を実行しよう。
そして、プログラムを実行すると、リスト型変数filesの一覧から「.txt」の拡張子を含むものだけを選んで表示でする。
$ python3 filter.py
bbb.txt
200abc.txt
201eee.txt
aaa.txt
プログラム中で指定した正規表現「\.txt$」だが、「\.」と書くとドット(.)を意味する。正規表現でドットは文字1字を表す特殊文字のため、ドットを表現したい時には「\.」と記述する必要がある。また、Pythonで「r'...'」と記述すると文字列の展開を抑制できるので、正規表現パターンを指定したい時などに重宝する。
200個以上のファイルをフォルダ分けしよう
さて、正規表現の使い方を覚えたので、さっそく今回のお題に挑戦しよう。今回も筆者が日々の作業で行ったものがベースとなっている。以下のように、200を超えるMP3ファイルがあり1つのフォルダに入っている。
-
200以上のMP3ファイルが1つのフォルダに散らばっている

実はこのMP3ファイルは、もともと英語、中国語、日本語と各言語ごとに整理されたものだ。ファイル名を見ると以下のような規則になっている。
osg_(言語コード)_(データ番号).mp3
ここで言語コードは、日本語「J」、英語「E」、中国語「CHS」のようなものになっている。そこでこれらを言語ごとのフォルダに分類するプログラムを作ってみよう。
こちらにサンプルファイルの一覧をアップロードしています。
そして、これらMP3ファイルのファイル名から正規表現で言語コードを取り出してフォルダ毎に振り分けるプログラムが以下のものとなる。「bunrui.py」という名前で保存しよう。
import re, os, glob, shutil
# ファイル一覧を取得する --- (*1)
files = glob.glob("*.mp3")
base_dir = os.path.dirname(__file__)
# 各ファイルごとに処理を行う --- (*2)
for f in files:
# 正規表現マッチ --- (*3)
m = re.search(r'_([a-zA-Z]+)_([0-9]+)\.mp3', f)
if m is None:
print("処理しない:", f)
continue
# 丸カッコで囲った部分を得る --- (*4)
lang = m.group(1)
no = m.group(2)
# 保存先フォルダ名を決める --- (*5)
lang_dir = os.path.join(base_dir, lang)
if not os.path.exists(lang_dir):
os.mkdir(lang_dir)
# ファイル名を決定してコピー --- (*6)
newfile = os.path.join(lang_dir, f)
shutil.copy(f, newfile)
print("コピー:", newfile)
プログラムを実行するには、IDLEを使うか、コマンドラインで「python3 bunrui.py」を実行しよう。
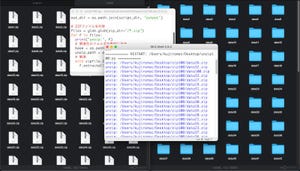
-

プログラムを実行したところ

プログラムを実行すると、言語コードごとにフォルダが作成され、その中にMP3ファイルがコピーされる。
それではプログラムを確認してみましょう。(*1)ではglobメソッドを使ってMP3ファイル(拡張子が「.mp3」)のものを取得している。この時点で特定の拡張子のファイルに振り分けているが、全てのファイルを取得したい場合には「*.mp3」と書いているところを「*」と書き換えよう。
(*2)の部分ではfor文を利用して各ファイル1つ1つに対して処理を行う。繰り返しの中では、(*3)で正規表現を使ってマッチ処理を行う。正規表現パターンにマッチしなければ、その旨を表示して次のファイルに処理を移すようにしている。なお、正規表現パターンで「[a-zA-Z]+」と書くと小文字と大文字のアルファベットの連続を意味する。「[0-9]+」と書くと数字の連続という意味になる。
(*4)の部分では正規表現でマッチした部分文字列を取り出している。正規表現のパターンで丸カッコで括った部分「(...)」を、ここで指定しているように、m.group(1)、m.group(2)のようにして取得できる。なお、ここでは言語コードを変数langに、データ番号を変数noに代入した。変数noは使っていないが、ファイル数が多すぎる場合など、さらに番号に応じてフォルダを分けることもできるだろう。
(*5)では保存先のフォルダ名を決めてフォルダがなければ自動的に作成するようにしている。そして(*6)でファイルをコピーする。
なお、ファイルコピーではなく、ファイルを移動したい場合には、(*6)の「shutil.copy(f, newfile)」の部分を「shutil.move(f, newfile)」と修正しよう。
まとめ
以上、今回は正規表現を利用して、ファイルをそれぞれのフォルダに分類する方法を紹介した。正規表現を使うことで、ワイルドカードなど単純な分類では対処できないような複雑なルールのファイル名を振り分けることができる。今回のプログラムを参考にして、業務自動化に役立ててみよう。
自由型プログラマー。くじらはんどにて、プログラミングの楽しさを伝える活動をしている。代表作に、日本語プログラミング言語「なでしこ」 、テキスト音楽「サクラ」など。2001年オンラインソフト大賞入賞、2004年度未踏ユース スーパークリエータ認定、2010年 OSS貢献者章受賞。技術書も多く執筆している。直近では、「シゴトがはかどる Python自動処理の教科書(マイナビ出版)」「すぐに使える!業務で実践できる! PythonによるAI・機械学習・深層学習アプリのつくり方 TensorFlow2対応(ソシム)」「マンガでざっくり学ぶPython(マイナビ出版)」など。