前回は、PythonでGmailのAPIにアクセスし、メールの要約を確認するところまで紹介した。今回は、もう一歩進めて、受信したメールを指定したフォルダに保存していくプログラムを作ってみよう。メールをファイルに保存するなら、個人的なメールバックアップとして使うこともできるし、また、様々な用途にも使えるだろう。
前回までのあらすじ
さて、今回は、前回の続きとなる。既に、OAuth認証を行って、GmailのAPIが自由に使えるようになっているところから始める。もし、認証が終わってない人は、前回の内容を参考にして、作業を一通り終えておこう。
前回の補足 - APIの利用権限について
ちなみに、前回、一つ目に実行したプログラム「gmail_auth.py」は、ユーザー認証のために必要なプログラムだ。このプログラムでは、冒頭で、以下のようにスコープ(利用可能権限の範囲)を指定していた。
# Gmail権限のスコープを指定
SCOPES = 'https://www.googleapis.com/auth/gmail.readonly'
上記のようにSCOPEを指定すると、Gmailを読込専用で利用するという意味になる。もし、メールの送信なども行いたい場合には、SCOPEの値を「https://mail.google.com/」と変更しなくてはならない。より詳しくSCOPEを指定したい場合は、こちらを参考にして書き換える必要がある。
今回は、受信専用のプログラムを作るので、そのままの設定で大丈夫だ。
メールを受信するプログラム
ここから、前回認証した情報をそのまま利用して、メールを受信するプログラムを改良してみよう。前回と同じように、認証情報のファイル「client_id.json」と「credentials-gmail.json」をJupyter Notebookと同じディレクトリに配置しよう。
それでは、Jupyter Notebookでプログラムを実行していこう。ここでは、前回のように、完全なプログラムを一度に全部実行するのではなく、少しずつ、意味のある塊ごとに実行して、プログラムの仕組みを理解しこう。
まず、以下のプログラムは、Google APIを有効にするものだ。
import httplib2, os
from apiclient import discovery
from oauth2client import client, tools
from oauth2client.file import Storage
# Gmail権限のスコープを指定
SCOPES = 'https://www.googleapis.com/auth/gmail.readonly'
# 認証ファイル
CLIENT_SECRET_FILE = 'client_id.json'
USER_SECRET_FILE = 'credentials-gmail.json'
# ------------------------------------
# ユーザ認証データの取得
def gmail_user_auth():
store = Storage(USER_SECRET_FILE)
credentials = store.get()
if not credentials or credentials.invalid:
flow = client.flow_from_clientsecrets(CLIENT_SECRET_FILE, SCOPES)
flow.user_agent = 'Python Gmail API'
credentials = tools.run_flow(flow, store, None)
print('認証結果を保存しました:' + USER_SECRET_FILE)
return credentials
# Gmailのサービスを取得
def gmail_get_service():
credentials = gmail_user_auth()
http = credentials.authorize(httplib2.Http())
service = discovery.build('gmail', 'v1', http=http)
return service
# ------------------------------------
# GmailのAPIが使えるようにする
service = gmail_get_service()
このプログラムを実行すると、何も表示されないが、エラーがでなければ、変数serviceを通して、GoogleのAPIが使えるようになっている。ここまでのプログラムは、ほぼ定型文と言って良いだろう。
続けて、Gmailのメール一覧を取得してみよう。以下のように記述すると、メッセージの一覧(メッセージIDと、スレッドID)を取得できる。
# メッセージを扱うAPI
messages = service.users().messages()
# 自分のメッセージ一覧を100件得る
msg_list = messages.list(userId='me', maxResults=100).execute()
msg_list
実行すると以下のような画面が表示される。
-

メッセージの一覧を100件得たところ

もちろん、このメッセージ一覧は、実際のメッセージではなく、メッセージを識別するためのID一覧だ。実際のメッセージを得るには、さらに以下のように実行される。例えば、取得したメッセージIDを利用してメッセージを表示するには、以下のようにする。以下は、最新のメールを一件、取得してその内容を表示する。
# 先頭のメッセージ情報を得る
msg = msg_list['messages'][0]
# idを得る
id = msg['id']
threadid = msg['threadId']
# メッセージの本体を取得する
data = messages.get(userId='me', id=id).execute()
print(data)
プログラムを実行すると、以下のようになる。
-
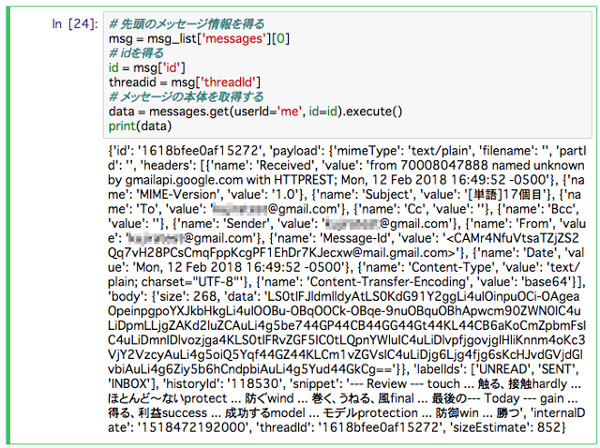
メッセージ本体の内容を表示したところ

メッセージの本体を取得するためには、messages.get()メソッドを使う。その際に、idを指定すると、idに対応するメッセージが取得されるという具合だ。
手順をまとめると、以下のようになる。
- (1) messages.list()でidの一覧を得る
- (2) messages.get()でidを指定してメッセージの詳細を得る
また、取得したメッセージの詳細を見てみよう。以下を実行して見ると、送信者情報やメールの件名を得ることができる。
data['payload']['headers']
実行すると以下のように表示される。実は、このメール、勉強のために自分自身に対して毎日メールしている、英単語の勉強メールだ。その点を踏まえて内容を見ると、分かりやすいだろうか。Subject(メールの件名)の項目に「[単語] 17日目」という文字列を見つけることができるだろう。
-

ヘッダ一覧を表示

続けて、メール本文の要約データを見てみよう。
data['snippet']
プログラムを実行すると、以下のように表示される。
-

メール本文の要約を表示

詳細な本文データを取得する方法
上記の方法では、本文の要約が取得した辞書型データのキー「snippet」に設定されているので、この項目を参照すれば、メールの本文が分かる。とは言え、正確にメールの本文や添付ファイルなどが知りたい場合には、生のメールデータから取得する必要がある。
しかし、ハッキリ言って、電子メールのフォーマットは、歴史的な事情から、非常に複雑なものとなっている。素人が独自にメールフォーマットを解析しようとしても難しい。しかし、Pythonには、電子メールを解析するためのモジュールemailがあるので、これを利用することで、比較的手軽にメールから本文を取り出すことができる。
実際のメール本文を得るためには、まず、rawフォーマット(Emailそのままの形式)でデータを取得し、Emailモジュールを使って、メールを解析するという手順を踏む。
実際のプログラムを見てみよう。
import base64, email
msg = msg_list['messages'][0]
# (1) rawフォーマットでメールを取得
data = messages.get(userId='me', id=msg['id'], format='raw').execute()
raw_data = base64.urlsafe_b64decode(data['raw'])
# (2) Emailを解析する
eml = email.message_from_bytes(raw_data)
# (3) 本文を取得
body = ""
for part in eml.walk(): # (4)
if part.get_content_type() != 'text/plain': # (5)
continue
s = part.get_payload(decode=True)
if isinstance(s, bytes):
charset = part.get_content_charset() or 'iso-2022-jp' # (6)
s = s.decode(str(charset), errors="replace")
body += s
# (7) 本文を表示
print(body)
実行すると、以下のように実際の本文が表示される。
-

実際のメール本文を取得して表示

プログラムの(1)の部分では、raw形式でメールを取得する。ただし、この時点でメールは、Base64でエンコードされている。そこで、Base64でデコードする。すると、Googleがメールを取得したそのままの状態のメールデータが得られる。次に、(2)の部分では、emailモジュールを使って、メールの解析を行う。
そして、(3)の部分で、メールの本文を取り出す。ただし、ここで注意が必要なのは、メールというは、複数のパートに分けられているものがるということだ。なぜ、複数のパートに分けられるのかというと、添付ファイルやHTMLメールを実現するためだ。一つのメールの中に、複数のデータを持たせるために、このような仕組みとなっている。
それで、(4)にあるように、walk()メソッドを使うと、複数パートを持つメールの各パートを一つずつ処理することができる。(5)では、複数のパートを一つずつ調べていって、コンテンツの種類が「text/plain」(テキストデータ)であれば、それを本文と判定して処理を行うようにしている。そして、(6)の部分で、取り出したテキストデータを文字コードごとにデコードする。
最終的なプログラム
以上、ここまでの部分をまとめて、最新のメール100件を特定のフォルダに保存するプログラムを作ってみよう。少々長くなるがまずはソースコードを表示する。
import httplib2, os
from apiclient import discovery
from oauth2client import client, tools
from oauth2client.file import Storage
import base64, email
import dateutil.parser
# 保存先
save_dir = os.path.join(os.curdir, 'gmaildata')
if not os.path.exists(save_dir):
os.mkdir(save_dir)
# Gmail権限のスコープを指定
SCOPES = 'https://www.googleapis.com/auth/gmail.readonly'
# 認証ファイル
CLIENT_SECRET_FILE = 'client_id.json'
USER_SECRET_FILE = 'credentials-gmail.json'
# ------------------------------------
# ユーザ認証データの取得
def gmail_user_auth():
store = Storage(USER_SECRET_FILE)
credentials = store.get()
if not credentials or credentials.invalid:
flow = client.flow_from_clientsecrets(CLIENT_SECRET_FILE, SCOPES)
flow.user_agent = 'Python Gmail API'
credentials = tools.run_flow(flow, store, None)
print('認証結果を保存しました:' + USER_SECRET_FILE)
return credentials
# Gmailのサービスを取得
def gmail_get_service():
credentials = gmail_user_auth()
http = credentials.authorize(httplib2.Http())
service = discovery.build('gmail', 'v1', http=http)
return service
# ------------------------------------
def email_extract_text(raw):
# Emailを解析する
eml = email.message_from_bytes(raw)
# 件名を取得
subject = ''
lines = email.header.decode_header(eml.get('Subject'))
for frag, encoding in lines:
if encoding:
sub = frag.decode(encoding)
subject += sub
else:
if isinstance(frag, bytes):
sub = frag.decode('iso-2022-jp')
else:
sub = frag
subject += sub
# 差出人を取得
addr = ''
lines = email.header.decode_header(eml.get('From'))
for frag, encoding in lines:
if encoding:
sub = frag.decode(encoding)
addr += sub
else:
if isinstance(frag, bytes):
addr = frag.decode('iso-2022-jp')
else:
sub = frag
addr += sub
print("-----------")
print("From: " + addr)
# 本文を取得
body = ""
for part in eml.walk():
if part.get_content_type() != 'text/plain':
continue
# ヘッダを辞書型に落とす
head = {}
for k,v in part.items():
head[k] = v
s = part.get_payload(decode=True)
# 文字コード
if isinstance(s, bytes):
charset = part.get_content_charset() or 'iso-2022-jp'
s = s.decode(str(charset), errors="replace")
body += s
print("Body: " + body)
# 日付
date = dateutil.parser.parse(eml.get('Date')).strftime("%Y/%m/%d %H:%M:%S")
# 件名と本文を結果とする
return \
'From: ' + addr + "\n" + \
'Date: ' + date + "\n" + \
'Subject:' + subject + "\n\n" + \
'Body:\n' + body
def receive_gmail(count):
# GmailのAPIが使えるようにする
service = gmail_get_service()
# メッセージを扱うAPI
messages = service.users().messages()
# 自分のメッセージ一覧を100件得る
msg_list = messages.list(userId='me', maxResults=count).execute()
for i, msg in enumerate(msg_list['messages']):
msg_id = msg['id']
print(i, "=", msg_id)
m = messages.get(userId='me', id=msg_id, format='raw').execute()
raw = base64.urlsafe_b64decode(m['raw'])
# メールデータを保存
text = email_extract_text(raw)
fname = os.path.join(save_dir, msg_id + '.txt')
with open(fname, 'wt', encoding='utf-8') as f:
f.write(text)
if __name__ == '__main__':
receive_gmail(100)
処理の流れとしては、今回紹介したプログラムをつなぎ合わせたもので、Gmail APIからメッセージ一覧を取得し、一件ずつrawデータを取り出し、emailモジュールを使ってメールを解析してファイルへ保存するというものになっている。
プログラムを実行するには、以下のようにコマンドラインから実行する。
$ python gmail-to-file.py
すると、プログラムと同じディレクトリに、「gamildata」というディレクトリを作成し、そのディレクトリ以下にメールを100件保存する。
-

プログラムを実行すると100件のメールをディレクトリに保存する

まとめ
Gmail APIを使うことで、Pythonを使って気軽にメール一覧を取得できることが分かっただろう。しかし、生の電子メールデータから本文や添付ファイルを取り出すためには、Pythonのemailモジュールおよび、メールフォーマットに対するそれなりの理解が必要となるだろう。とにかく、Gmailをテキスト形式で保存したいという方は、本稿の最後のプログラムをダウンロードして、内容を確認してみよう。
自由型プログラマー。くじらはんどにて、プログラミングの楽しさを伝える活動をしている。代表作に、日本語プログラミング言語「なでしこ」 、テキスト音楽「サクラ」など。2001年オンラインソフト大賞入賞、2004年度未踏ユース スーパークリエータ認定、2010年 OSS貢献者章受賞。技術書も多く執筆している。