

Windowsでは、文字をリトルエンディアンの16 bitで扱う。いわゆるUTF-16LEという形式になるが、これをMicrosoftは「Unicode」と呼ぶ。Windows NTの開発時期と初期のユニコード(話が面倒になるので仕様としてのUnicodeを仮名書きする)の策定時期が重なっており、幸か不幸か、Windows NT 3.1は、ユニコードを採用したオペレーティングシステムとして登場した。NTの開発は1980年台末に遡る。そして同じころ、ユニコードの構想が行われ、1990年にはMicrosoftが策定に参加、翌年の1991年にユニコード・コンソーシアムが設立された。そういうわけで、Windows NT以後、現在のWindows 10、Windows 11では、内部的な文字コードとして1文字16 bitの「Unicode」を使う。これは文字エンコードとしてはリトルエンディアンのUTF-16という形式になる。
ほとんどのユーザーは、WindowsをGUIで利用するため、文字を「フォント」として見るので、文字コードがどうなっているのかを見ることもないし、また、その必要もない。しかし、ユーザーが文字コードの問題に引っかかることがある。1つは、俗に言う「文字化け」。インターネットからダウンロードした、あるいは、他のプラットフォームから持ってきたテキストファイルなどが読めない状態になることがある。これは、メモ帳などのファイルビュアーとして使われるアプリが複数のエンコード方式に対応することて対処できつつある。
もう1つは、ExcelやPowerShellでの「サロゲートペア」の問題だ。Windows NT 4.0が登場した1996年、ユニコードコンソーシアムは、Unicode 2.0を発表したが、この頃16 bitには世界中の文字が入らないことが米国企業にも理解され、コードの範囲を拡大することになった。しかし、Windows NTのように、すでに16 bitで文字コードを定めてしまったシステムが普及しはじめていた。その折衷案としてでてきたのがサロゲートペアだ。まず、ユニコードで文字に割り当てるコード範囲を21ビット(0~0x10FFFF)以下とする。次に16 bitの文字コードのうち一部をサロゲート用に割り当て、2つの16 bit文字を使って20 bitを表現することにした。これにより、21 bitのユニコード文字コードの範囲をカバーした。ただし、Windowsのサロゲートペアへの対応は2006年のWindows Vistaで行われた。
サロゲートペアでは、16 bit文字2つでユニコードの第1面から第16面(0x010000~0x10FFFF)の範囲を表現する(表01)。第4面から第13面は未定の範囲であり、いまのところ十分な「空き」がある。サロゲートペアとして使う範囲は、他の文字と重ならならず、かつ、上位10 bitを示すハイサロゲートと下位10 bitを示すローサロゲートも先頭のbitが重ならないため、簡単に見分けることができる。
| ■表01 | ||||
|---|---|---|---|---|
| 面 | 主な用途 | 開始 | 終了 | 備考 |
| 第0面 基本多言語面 | 一般スクリプト | 00000 | 01FFF | |
| 記号 | 02000 | 02DFF | ||
| CJKの表音文字、記号 | 02E00 | 033FF | ||
| CJK統合漢字 | 03400 | 09FFF | ||
| 彝文字 | 0A000 | 0A4CF | ||
| ハングル音節 | 0AC00 | 0D7AF | ||
| 代用符号位置 | 0D800 | 0DFFF | サロゲート範囲 | |
| ハイサロゲート | 0D800 | 0DBFF | 10bit分 | |
| ローサロゲート | 0DC00 | 0DFFF | 10bit分 | |
| 私用 | 0E000 | 0F8FF | ||
| 互換文字と特殊文字 | 0F900 | 0FFFD | ||
| 第1面 | 追加多言語面 | 10000 | 1FFFF | この20bitの範囲をD800-DC00~DBFF-DFFFで表す |
| 第2面 | 追加漢字(表意文字)面 | 20000 | 2FFFF | |
| 第3面 | 第3漢字(表意文字)面 | 30000 | 3FFFF | |
| 第4~13面 | 未定 | 40000 | DFFFF | |
| 第14面 | 追加特殊用途面 | E0000 | EFFFF | |
| 第15/16面 | 私用面 | F0000 | 10FFFF | |
しかし、一部のソフトウェアは、サロゲート導入以前の「すべての文字は16 bitで表現できる」という考えのままだ。このため、実際には1文字なのにサロゲートペアを2文字と数えてしまうものがある。ユニコードの第一面以降に文字が追加されていくごとにサロゲートペアの利用頻度もあがる。たとえば、利用頻度が高くなってきた多くの絵文字がサロゲートペアで表現される範囲に入っている。
Windowsにも、サロゲートペアを正しく1文字と判定する文字列処理機能はある。また、サロゲートペアに対するビット割り当てから、サロゲートペアかどうかを判定するのも難しくない。こうした処理は、個別のアプリケーションで行うものではなく、システムが提供すべきものだ。というのもユニコードの処理に関するルールは膨大で、1つのアプリケーションがすべて対応できるものでもないからだ。
しかし、1文字は16 bitという前提で作られたプログラムのなかには大規模に書き換えないと対応ができないものがある。ただし、大半のプログラムは、サロゲートペアを含むような文字列を扱うことがないために問題が表面化していないだけだ。
広く利用されているExcelやWindowsに付属するWindows PowerShellは、サロゲートペアを2文字と判定してしまうような「古代」のソフトウェアである。たとえば、Excelでセルに絵文字1つを入れて、文字列の長さを求めるLEN関数を適用すると2という数字が返ってくる(写真01)。サロゲートペアにならない漢字を入れたときには、正しく1と表示する。文字列の長さの違いは、文字列処理のMID/LEFT/RIGHT関数なども影響を受け、サロゲートペアの途中を切り出してしまう。結果として文字が正しく表示されないといった問題が起きる。バージョンアップが2~3年に一回という昔ならともかく、いまでは、Excelは半年ごとにバージョンアップしている。日本語などの2バイトコード文字対応のために1バイトコード用、2バイトコード用にLENBとLEN関数などの文字列処理関数を追加したぐらいなのだから、サロゲートペアに対応した文字列関数を新規に追加するぐらいなんとかなりそうな気はする。とはいえ全部が古代のままではなく、たとえば、ExcelはIVSによる異字体セレクタには対応している。こちらは役所関係の要望も強いだろうから優先度が高かったのは理解できる。しかし、Windowsがサロゲートペアに対応して15年、そろそろサロゲートペアにもちゃんと対応してほしいところだ。
-
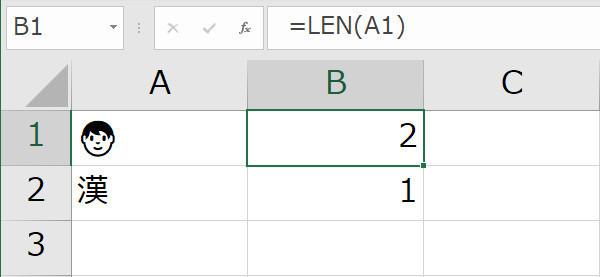
写真01: Excelで絵文字をセルに入れて文字数を得るLEN関数を適用すると2が返ってくる。しかし、普通の文字なら1になる

PowerShellの場合には、言語であるため、少し話がややこしくなる。Excelと同様に、サロゲートペアを含む文字列は、ユーザーが認識できる文字数と文字列長が一致しない。もちろん、PowerShellから.NET Frameworkの文字列処理ライブラリ関数(System.Globalization.StringInfoなど)を呼び出せば、サロゲートペアを含む文字列の長さを正しく判定できる。しかし、通常の文字列の長さを取得するプロパティである「length」は、サロゲートペアの文字を2と報告する(写真02)。
-

写真02: Windows PowerShellでも変数に絵文字を入れると、文字数を返すlengthプロパティは2を返す。絵文字を含む文字列の文字数を正しく得るには、.NET FrameworkのStringInfoクラスなどを利用する

Windows 10では、標準付属のメモ帳などがUTF-8に対応し、絵文字入力パネルが搭載され、標準のテキスト入力がカラーフォントによる絵文字表示(カラーフォント対応Windows 8で入った)するなど、環境的には整備されつつある。たとえば、「設定」アプリやエクスプローラーの検索欄には、赤毛の男性の顔を示す絵文字が入る。これは、「男性、スキントーン、ゼロ幅接接合子(ZWJ。Zero Width Joiner)、赤毛」という4つのコードの並びになるが、1つの絵文字として表示されている(写真03)。ZWJは「制御文字」なので、この絵文字が「何文字」になるのかを判定するのは難しいところだが、この並び(Unicode Text Segment)は、1つの絵文字として表示されることが期待されている。実際、Windowsの設定などの検索欄や多くのブラウザのアドレス欄などは、そのように表示できる。正しくユニコードを表示できるということは、Windows内部には、そのための機能が組み込まれているということになる。しかし、ExcelやPowerShellはこれを使っていないということだ。
-
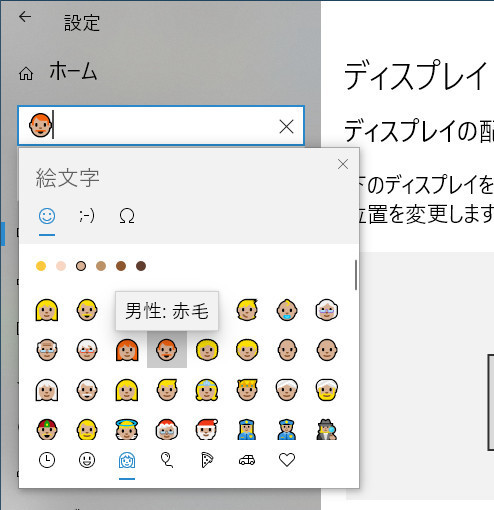
写真03: Windows 10や11の設定プログラムにある検索欄は、複雑な絵文字も認識してただしく1文字として扱うことができる

1980年台には、UNIXなどさまざまなオペレーティングシステムが、いまでいう地域化を行い始めるようになる。このとき、さまざまな議論があり、さまざまな実装があった。MS-DOSやBASIC言語の日本語対応で生まれた「シフトJIS」をUNIXで利用した例もあったほど、当時ちょっとした混乱があった。1980年台の中頃にはEUCが提案され、これを使った地域化(コードには各国の漢字コードを使う)に統一されていく。このとき、すでに「国際化」が考慮されていたため、その後の道筋がはっきりしていた。ユニコードへの対応では、UTF-8が採用され、現在のLinuxはそれを受け継ぐ。なので、bashで変数に絵文字を入れても文字列の長さを正しく表示できる(写真04)。
-
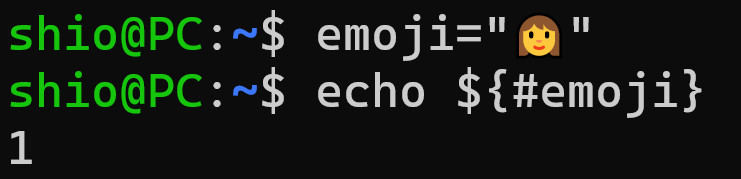
写真04: Linuxのbashは、文字エンコードにUTF-8を使うためサロゲートペアの問題は発生しない

Windowsや開発ツールなどが整備され、ソフトウェア開発では、文字列やソースコードではUTF-8が使え、サロゲートペア問題は見えなくなりつつある。しかし、ExcelのLEN関数などのように、ときおり、サロゲートペアが顔を出し、それが一般ユーザーにも見えてしまうことがある。もちろん、サロゲートペアを含む文字列をExcelで処理しなければ、この問題を見ることもないが、今後、絵文字などサロゲートペアを含む文字列データが増え、大きな問題になるんじゃないかという気がしている。
追記
実はこの連載、毎回のサブタイトルには必ず元ネタがある。今回の元ネタは米国のテレビドラマ「スターゲイト ユニバース」。1960年台の米国ドラマ「タイムトンネル」をリメークするとこんな感じなのかと筆者は勝手に思っている。ちょっとミリタリー系なんだが、タイムトンネルも設定は米軍のプロジェクトだった。このため、タイトルでは、サロゲートの表記をネタに合わせた。なお、サロゲートペアのユニコード・コンソーシアムの正式な日本語表記は「代用対」である。
Unicode Terminology: English - Japanese
https://www.unicode.org/terminology/termenja.html




