企業へのAI導入コンサルティング業務を提供する企業・LifePromptが1月16日、大学入試共通テストを3つの生成AIに解かせる実験をおこない、その結果をを公開した。その結果によると、「やはりGPT-4はバケモノ」だったそうだ。この実験がネットで「面白い」「数学苦手なんや」などと話題になっている。
-

「GPT-4」と「Bard」、「Claude2」。一番賢いの誰だ

本実験は、米Open AI社の「ChatGPT(GPT-4)」と、米Google社の「Bard」、米Anthropic社の「Claude2」のそれぞれの性能を比較するためのもの。2024年の大学入試共通テストのうち、国語・英語(リーディング)・数学(1A、2B)・社会(世界史・日本史)・理科基礎の5教科7科目について、テキストか画像で試験問題をAIに入力し、テキストでの出力内容をもとに答え合わせをおこなった。
実験の結果、「GPT-4」がダントツで、数学以外の科目で受験者平均を超えたそうだ。Claude2もGPT-4には及ばなかったものの、複数科目で受験者平均を上回ったという。
-
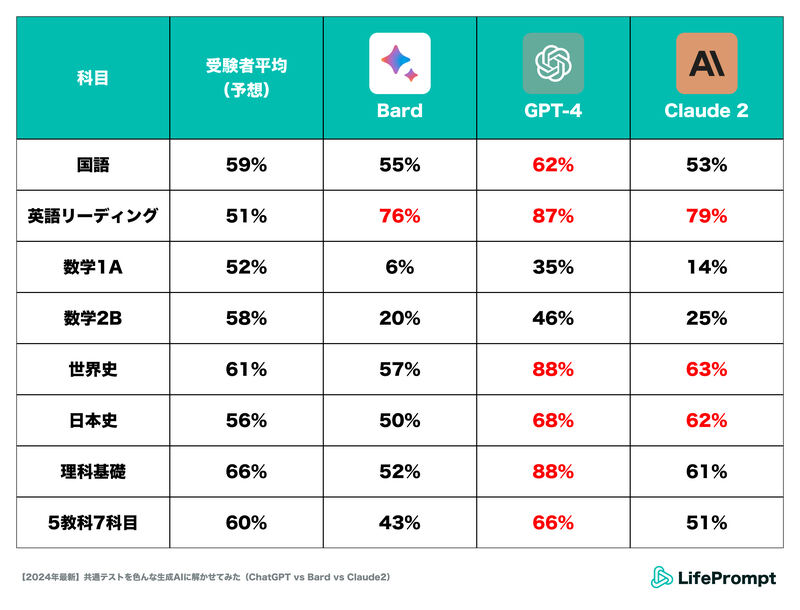
赤字は受験者平均点を超えた箇所。「GPT-4」が頭一つ抜けている感じ

同社は、この結果について、「GPT-4の生成AIとしての性能がシンプルに高い」「他のAIに比べてプロンプトや効果的な活用方法が研究されているため、ポテンシャル発揮率が高かった」と考察した。また、「とりわけリンク化された画像を読み取る性能や、解釈が定まっている事実を的確に取り出す能力の高さは、社会や理科を回答させている中で実感できるレベル」だったとのこと。
一方、どの生成AIも「複数の処理を同時に求められると急激にパフォーマンスが悪くなる」傾向にあったという。たとえば、日本の史実を年代順に並び替える問題では、「与えられた文章の年代を特定する」「3つの出来事を古い順に並び替える」という動作を、一つの問題の中で同時に求められると、年代特定が不正確になったり、出来事の並び替えが正常に行えなくなったりするようだ。また数学は、特殊な解答形式に対応できず、どのAIも点を取れていなかったとのこと。
このほか同実験では、「GPT-4」と「Bard」、「Claude2」において、それぞれの解答の特徴についても考察している。興味があればチェックしてほしい。
ネット上では「コンピュータなのに数学が苦手なんやな」「要するに、日本の将来を担う人材に求められる能力は、AIがだいたい備えてるってことだよな…」「ある意味、シンギュラリティはもう来ているのかもねえ」「」「満点近く取れるのかと思ったぁ😲」「これは面白い」などの声が寄せられた。