AWSのハイ・パフォーマンス・コンピューティング
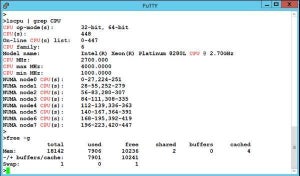
Amazon Web Servicesは12月2日(米国時間)、米国ラスベガスで年次イベント「AWS re:Invent 2019」をスタートした。基調講演では、AWS Global Infrastructure and Customers Support, Vice President, Peter DeSantis氏が、同社のハイ・パフォーマンス・コンピューティング(HPC: High-Performance Computing)に関する取り組みについて発表した。同社は仮想マシンの性能を随時引き上げており、その性能はHPCの需要に応えるレベルを維持している。
-

AWS Global Infrastructure and Customers Support, Vice President, Peter DeSantis氏

こうした性能を実現する1つの技術がNitroコントローラだ。EC2のすべての仮想マシンはNitroコントローラの上で動作している。高いパフォーマンスとスケーラビリティ、優れたレスポンス性能はこうしたハードウェアを使うことで実現されている。
-

AWS EC2の性能を支えるNitroコントローラ

EC2の仮想マシンで動作するアプリケーションは主にTCPを使って通信を行うことになるが、ここにも最適化が施されている。複数のインスタンスから単一のインスタンスに対して同時にTCP経由でデータを送信した場合、通常はパケットロスや通信ごとの速度差が発生する。
この速度差はTCPの仕様上、通信量が増えれば発生しやすくなるが、EFA(Elastic Fabric Adapter )を使うと発生しにくくなる。どの通信も同じ速度が実現され、断続的な通信が連続的な通信に平準化される。また、プロセッサ数に対するスケーラビリティも高くなる。Nitroコントローラはこうした通信を支えている。
-

EFAを使うことで通信のスケーラビリティが向上

ハイパフォーマンス・コンピューティングに対する需要は増える一方だ。しかし、こうした環境を自前で整えるには高い資本力が必要になる。AWSの提供しているクラウドコンピューティングを利用することで、こうしたハイパフォーマンス・コンピューティングに必要になるリソースを瞬時に整備でき、さらには、使用した分だけ料金を支払えばよいため、運用を適切に行えば高い費用対効果を得ることができる。
性能化する機械学習
画像認識や音声認識、機械翻訳など、現在ではさまざまなサービスが機械学習を利用している。機械学習は適切な教材データを用意し、利用に適した学習モデルを選択し、それらを学習によって整えることによってサービスの提供が可能になる。学習にかかる処理はいわゆるハイパフォーマンス・コンピューティングの領域であり、当然AWSはこの分野に対し投資している。
機械学習ではGPUが使われることが多い。複数のGPUを利用することで機械学習にかかる時間を短縮するという発想だ。
-

機械学習に使われるGPUクラスタボード

機械学習では一旦学習させてデータを用意してしまえば、あとはそれなりのパフォーマンスリソースでも利用することができる。問題は学習に時間がかかるということだが、AWSでは高いスケーラビリティを実現することで学習時間を短縮している。
-

EFAを使うことで高いスケーラビリティを実現

-

EFAを使うことで学習時間もスケーラビリティを向上

上記のスクリーンショットはAWSが提供しているサービスによる学習のスケーラビリティがどのように改善されたかを示すものだ。使用するGPUの個数が増えるごとに学習時間が短縮されていることがわかる。学習時間を短縮したい場合、それに合わせてアテンドするGPUの個数を増やせば良いということになる。
こうした学習プラットフォームを自前で用意しようとすると、きわめて高額な資本が必要になる。運用にもかなりのコストと手間が必要になる。AWSの場合、そうしたコストと手間がかからないのが最大の利点だ。必要な時に必要なだけリソースを割り当て、必要な時間だけ実行すればよい。これで経費を最小限をに抑えつつ、最大の効果を上げることができる。
HPC/機械学習をリーズナブルに実現
PCを数台利用するといった規模であれば、仮想環境よりもオンプレミスのベアメタルに軍配が上がるケースは多い。費用に比べて実現できるパフォーマンスが高く、さらに手の届くところにあるという地理的条件もあって、クリティカルな問題に対処しやすいという特徴がある。特に社内に優れたエンジニアを抱えている場合、こうしたやり方の利点は大きい。
一方、数百台から数千台のPCを同時に利用するといったハイパフォーマンス・コンピューティングや機械学習といった話になると、自社にハードウェアを用意するにはかなりの資金が必要になる。構築および管理できる専門家チームも必要になり、かなりの労力と資本が必要だ。このレベルになってくると、AWSの提供するクラウドプラットフォームのほうが経費的なメリットがわかりやすくなってくる。
さらに、AWSが提供するクラウドプラットフォームは毎年スケーラビリティが向上している。性能が必要になったらその分だけ台数を増やせばよいのだ。それだけ費用は発生するが、すべてを自前で揃える場合と比べれば廉価で済む。