富士通研究所は10月25日、AI運用時の入力データの正解付けを自動化することで、AIの精度の推定とAIモデルの自動修復を可能にする技術「High Durability Learning(ハイ デュラビリティ ラーニング)」を、世界で初めて開発したと発表した。
近年、AIの普及が進み、AI活用による業務効率化や生産性向上などに期待が集まっているが、学習データから構築したAIモデルは業務で使い続けるにしたがい、社会情勢や市場・環境の変化などにより、入力データの傾向が構築当初の学習データと比べて変わってしまうことがあり、AIの推定精度が低下する問題が発生すると同社では指摘している。
例えば、金融分野での企業の信用リスクをAIで評価する場合、企業の財務データを用いて学習したAIモデルを使うと、経済構造の変化などで入力データの傾向が学習時と比べ変化するため、信用リスクの推定精度が低下する場合があるという。
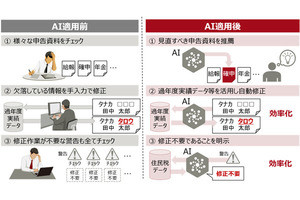
そのため、業務でAIを活用する際には、AIの運用段階で随時精度を確認し、AIモデルの精度が低下した場合には、最新のデータを用いて再学習を行い、AIモデルの修復および予測精度の回復を図る必要があるとしている。
AIモデルの精度を確認するには、最新の入力データ(例:財務データ)とセットとなる正解データ(例:格付け)が不可欠となるものの、正解データを準備するには大量のデータに対して専門家が正解付けを行うことが必要になるなど、多大な作業やコストを要するという。また、人手による調査で精度低下が確認できるまでは、再学習が必要となるタイミングを見極めることは難しく、精度が低下した時でもそのことに気づけないこともある。
-

AI運用における課題(金融分野での信用リスク評価の例)

そこで、同社ではAIの精度を随時推定でき、精度低下時にはAIモデルの自動修復を実現する技術としてHigh Durability Learningを開発。
主な特徴として「運用時におけるAIモデルの精度を高度に推定」「自動修復によるAIの精度低下を抑制」の2点を挙げている。
精度を高度に推定することに関しては、AIモデルを学習する際に用いる学習データの分布と運用時の入力データの分布を形状としてとらえ、学習時から運用時へのデータの変化の傾向を把握することで、運用時の入力データに対する正解付けを自動で実施する。これにより、入力データに対する元のAIモデルの推定結果と、自動設定した正解を比較することで、その時点のAIモデルの精度が推定可能だという。
-

「High Durability Learning」による入力データの自動正解付け

精度低下の抑制については、入力データに付与した正解にもとづいて、AIモデルの分離境界を入力データの傾向に応じて調整することで、AIモデルを新たな入力データに順応させることができるようになり、大規模な再学習を実施することなく、AIの精度低下を抑えることを可能としている。
効果として、金融分野における信用リスクの評価を3,800社の財務データを用いて検証したところ、新技術によりAIの精度を誤差3%に抑えて推定したことを確認したほか、AIの精度が従来技術だと69%まで低下するが、新技術では89%で維持できることを確認した。
新技術によりAIの精度を長期間維持できるため、AIの安定運用が可能となることに加え、入力データの種類やAIのモデルに依存せずに適用することが可能なため、さまざまな業務において、新規導入のAIだけでなく、すでに導入済みのAIとも組み合わせることができるという。
そのため、金融分野だけでなく、小売分野での商品分類AIや流通分野における文字認識AIなど、多様な業務でのAIの運用効率を高めることが期待されている。今後、同社ではさまざまな現場での業務適用や検証を進め、2020年度中に富士通の目的指向型プロセスとフレームワーク「Design the Trusted Future by Data×AI」へ組み込むほか、AI技術「Zinrai」を支える新たな機械学習技術として実用化を目指す方針だ。