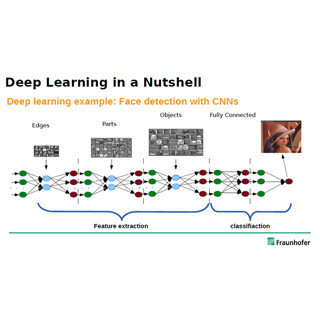
DeepSentiBankであるが、ニューラルネットとしてはAlexNetのアーキテクチャを使い、フレームワークとしてはCaffeを使っている。そして、YFCC100mの1Mイメージをトレーニングデータとして使っている。

|
|
ニューラルネットとしてはAlexNetのアーキテクチャを使い、YFCC100mの内の1Mイメージをトレーニング用に使用した |
その結果を次の図に示す。この表には、3つのシステムの認識結果が書かれており、最初の行は、低レベルの特徴抽出とSVMという従来の手法を用いたSentiBank1.1の結果、2行目はディープラーニングを用いているが、まだチューニングが完全でないもの。最後の行が、チューニングされたDeepSentiBankの結果である。2089のANPが含まれる入力で、SentiBankが第1候補として挙げたものが正解であった確率は、SentiBank1.1では1.7%であるが、DeepSentiBankでは8.16%に向上している。これは非常に低いと思われるかも知れないが、後に出てくるイメージにキャプションを付ける例では、1位から6位は、
- person with cute dog in a park
- person with cute dog in the park
- handsome man with dog in a park
- handsome man with dog in a park
- person with a cute dog
- man with dog in a park
という解答であり、どれも間違ってはいない。その中で最初の解答が正解とされたものと一致するというのはなかなか高い確率とはならない。
Top10の中に、正解が含まれている確率は、2089ANPの場合は26.1%、1200ANPの入力では44.4%である。

|
|
3つの版のSentiBankの認識結果。2089ANPの入力でTop10までに正解が含まれている確率は、SentiBank1.1では10.3%であったが、Deep Learningを使う最新のDeepSentiBankでは26.1%に向上している |
ディープラーニングを使用することで従来方式と比べて大きな改善が得られたが、まだ、認識率は十分ではないので、より複雑なニューラルネットを評価した。対象はVGGnetとGoogLeNetである。
AlexNetのTop10が36.4%に対してVGGnetでは40.15%、GoogLeNetでは46.4%とネットワークを大きくしていくことで、認識率が高まることが分かったという。

|
|
VGGnetとGoogLeNetを使ったDeepSentiBankの比較。Top10の確率はAlexNetの36.4%に対してVGGnetは40.16%、GoogLeNetは46.4%に向上している |
イメージへのキャプション付けに関して、Borth氏のグループは、Concept And Syntax Transition Networkを考案した。この方法では、YFCC100mのタイトルからコンセプトを抜き出し、それに構文からの情報や同じようなコンセプトの情報を使って、次の図の下側に書かれたようなネットワークを作る。

|
|
コンセプトとそれらの関係を示すCASTネットワークを作る |
次の図では、左の写真から「dog」、「cute」、「man」、「park」というコンセプトを抽出している。そして、下に描かれたネットワークを作っている。

|
|
左の写真からdog、cute、man、parkというコンセプトを抽出し、下側のネットワークを作る |
CASTネットワークから作られたキャプションの候補がオーバレイで表示されているが、どれも間違いではない。このため、ディープラーニングの性能評価では、上位5位とか10位までに正解が含まれている確率が何%というような評価を行うのが一般的である。

|
|
1位から6位までのキャプションの例。どれも間違ってはいない |
DeepSentiBankで作成したキャプションの例を次の写真に示す。左上は、「良い帽子を冠り、もの思わし気な表情の格好の良い男性」、右上は「繁華な都市の中の息をのむ建築」、下側は「とても素晴らしい目立った美しさを持つ、楽し気な花」というキャプションが付いている。
形容詞を認識することは、名詞だけの認識より難しいと思われるが、この発表で、その必要性は理解できた。惹き起こされる感情を認識できるという点で興味深い研究である。

|

|

|
|
DeepSentiBankで作成したキャプションの例 |
||