Cortex-A53
Cortex-A53は、現在のA7のパイプラインをベースに、ARMv8アーキテクチャに対応したプロセッサだ。A53については、整数パイプラインの詳細などは公開されず、プロセッサ全体のブロックのみの解説だった。A53は、低消費電力であることを前提に作られているため、64bit化は、最低限のリソースで実現していると思われる。
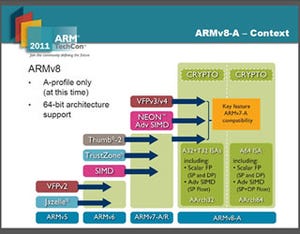
Photo01は、Cortex-A53のブロック図だ。A53は、4つまでのマルチコア構成が可能で、L2キャッシュをコア間で共有する。SoC内部での接続には、AMBA 4(ARM社の提供するシステム接続技術)を利用する。

|
Photo01: Cortex-A53は、4コアで1クラスタを構成する。これをSoC内部バスであるAMBAでメモリコントローラーやCortex-A57クラスタなどと接続する |
各コアには、L1キャッシュがあり、デコードのあと、ロードストア、整数、NEONの3つのパイプラインに分かれる。なお、ARMv8では、ARMv7ではオプションだったNEONが標準となったが、オプションとして暗号化命令拡張が用意されている。
さて、その性能だが、Cortex-A7よりも25%程度高速化されているという。これは32bitモード同士の比較だが、A7が40nmプロセスで製造した実シリコンの値であるのに対して、A57の速度は、エミュレーションからの推定値である。なお、クロックあたりのDMIPS(ドライストーンベンチマークから計算した1秒間の命令実行回数)値は、A7が1.9DMIPS/MHzであるのに対してA53は2.3DMIPS/MHzである。また、1.2GHzクロックでのSPEC Int 2000(base)の結果はA7が420であるのに対してA53は、540となっている。

|
Photo02: A53とA5/A7の比較。SPEC int2000でCortex-A53は、A7よりも25%以上高速になるようだ |
現行の主力プロセッサであるCortex-A9との比較だが、クワッドコア同士の比較で、1.4GHzのA9プロセッサよりも、1.3GHzのA53のほうが高速になっている。もともと、A7がA9と同程度の性能があった。Cortex-A9は、A15がハイエンドとして普及する来年には、メインストリームから価格重視の価格帯のスマートフォン、タブレットのプロセッサとして使われることになるが、A53の性能からすると、A9プロセッサの後継としての資格は十分あるだろう。

|
Photo03: クワッドコアでのCortex-A9との比較。クロック周波数が低いのにCortex-A53のほうが高速になる |
さて、コア内部の各部分を見ていくことにしよう。まずは、L1を含むフロントエンド部分(Photo04)だが、ここは、L1、予測機構、命令キューの3ステージ構成となっている。

|
Photo04: フロントエンド部。L1命令キャッシュはフィルバッファーを介してL2側と接続している。ここには、分岐予測機構などがある。Instruction Parsingは、デコーダーの前の段階で分岐命令を解析して、ターゲットアドレスなどを確定させるための機構だと推測される |
全段となるL2側とは128bitのFill Bufferを介して32キロバイトのL1キャッシュが接続する。L1は2wayセット・アソシアティブ構成で、フェッチ幅は64bitである。また、ここには、条件実行(ARMの32bit命令には条件フィールドがあり、演算結果によって、次の命令をスキップするかどうかを指定できる)予測機構と、インダイレクトアクセス(レジスタの値を使う間接メモリ指定)の予測機構(256エントリ)がある。また、ここに10エントリの「μTLB」(Translation Lookaside Buffer)がある。マイクロとなっているのは、Main TLBが別にデータパスのほうにあるからだ。命令は、メモリの連続した場所に置かれることがほとんどで、局所性が非常に高いため、データ用ほど大量のTLBが不要だからであろう。
また、ここに命令デコーダーとは別に「Instruction Parsing」というブロックがあり、直後の命令キューの1クロックサイクルで2命令を予測している。分岐予測機構があるのにBranch Target Bufferがないのは、デコーダーの前にここで、解析が行われるからだと思われる。
このフロントエンド部の後ろにあるのが命令デコーダーと演算実行パイプラインだ(Photo05)。全段の命令キューに入った命令は取り出されてデコードされる。その後、整数、ロードストア、NEONのパイプラインに分かれるが、「ロード」と「ストア」はそれぞれ2つのパイプから構成され、整数部分も2つの「整数演算」、「かけ算」、「割り算」の4つのパイプから構成される。またNEON(SIMD演算機構。VFPと呼ばれるベクタ演算命令処理を含む)のパイプは、内部的には、かけ算、割り算、平開(いわゆるルートの計算)を処理するパイプとそれ以外の演算のパイプに分かれている。

|
Photo05: 実行パイプライン部。ストア用、ロード用の2つのパイプに4つの整数用パイプ(かけ算、割り算、その他用2つ)があり、NEONのパイプラインは、2つに分かれている。NEON部のパイプラインは、整数部よりも長い |
なお、アーキテクチャ上のレジスタは、32bitと64bitモード(AArch32とAArch64)で違っているが、32bitモード時は、割り込み用などでレジスタのバンク切り替えが自動で行われる。これはスタックポインタやリンクレジスタ(サブルーチンコールの戻りアドレスを入れておくレジスタ)を待避して値を設定する手間を省き、素早い割り込みやエラー処理などを行うための機構。じつは、このバンク切り替え分を含めると、32bitモードには、31個の32bitレジスタがある。64bitモードでは31個の64bit汎用レジスタを扱う。レジスタファイル機構は、32bitと64bitで共有されており、ハードウェア的には、64bitのレジスタが31個あり、32bitモードでは32bit幅でこれを使い、必要に応じてアクセス先を切り替えているとのことだ。なお、A53は、インオーダーなので、レジスタリネーミングなどの機構が不要であるため、レジスタファイルのレジスタ数は、アーキテクチャ上の数と一致する。
L2とメモリアクセス部(Photo06)だが、メモリコントローラーとは、AMBA4を介して接続されている。AMBAは、SoC内部の高速な接続を行うインタフェースで、AMBA 4はその4世代目ということだ。Cortex-A53では、AMBA4 ACEと呼ばれる仕様のものを利用する。ACEはAXI Coherency Extensionsの意味で、AXIはAMBAに含まれるバスインタフェースの仕様である。AMBAには、コア間やコアメモリ間を接続する高速なAXI(Advanced eXtensible Interface)と周辺機器を接続するための低速なAPB(Advanced Peripheral Bus)の2つのインタフェースが含まれている。

|
Photo06: L2とL1データキャッシュ。プリフェッチャーは複数ストリームの扱いが可能 |
L2は、このACEを介してSoC内部のメモリコントローラーをアクセスする。また、スヌーピングのためのSCU(Snoop Control Unit)がある。
A53は、4コアがひとまとりまりとなってクラスタを構成する。クラスタ内ではL2を共有し、AMBAで他のCortex-A53/57クラスタと接続することも可能だ。
L2共用キャッシュとL1データキャッシュの間には、ストアバッファ、プリフェッチャー、Main TLBがある。ストアバッファは、コア側からの複数の書き込みをまとめるもの。なお、L2はL1でキャッシュされているデータを保持しないエクスクルーシブ構成となっている。また、L2キャッシュサイズは、設計時に変更が可能だ。
Main TLBは、512エントリの4Wayセットアソシアティブ構成である。これとは別にL1データキャッシュ用のμTLBが別にある。
また、コア側(ロードストアパイプ側)とは、バッファを介して接続している。
Photo07は、クワッドコアのCortex-A53のダイレイアウトとヒートマップだ。写真左側が1メガのL2キャッシュ、中央部分がコア、フロントエンド部との接続部分だ。右側の上下には、左右対称にコアが配置されている。各コアのダイ外周側にL1キャッシュなどのフロントエンド部が配置されている。これは、TSMCの28HPMプロセス用のもので、ARM社のライブラリから構成したものだという。赤く表示され温度が高くなっているのは、デコーダーの周辺と思われる。また、L2との接続部分の温度も高くなっている。

|
Photo07: Cortex-A53のレイアウト。左側がL2キャッシュ部 |