RightMark Memory Analyzer 3.8
cpu.rightmark.org
http://cpu.rightmark.org/products/rmma.shtml
ということでいよいよRMMAである。先にも述べたとおり、ここからはTurboBoost:Offの環境で測定を行なっている。
Instruction Decode(グラフ3~18)
さて、ではここから行こう。今回はInstruction Decodeの結果を全部示したが、これはかなり振る舞いが面白い事になっているからだ。まず最初に確認のために書いておくと、このテストでは、
| NOP(1) |
nop |
| SUB(2) |
sub eax, eax |
| XOR(2) |
xor eax, eax |
| TEST(2) |
test eax, eax |
| XOR/ADD(4) |
xor eax, eax; add eax, eax |
| CMP #1(2) |
cmp eax, eax |
| CMP #2(4) |
cmp ax, 0x00 |
| CMP #3(6) |
cmp eax, 0x00000000 |
| CMP #4(6) |
cmp eax, 0x0000007f |
| CMP #5(6) |
cmp eax, 0x00007fff |
| CMP #6(6) |
cmp eax, 0x7fffffff |
| Prefixed CMP #1(8) |
cmp eax, 0x00000000 |
| Prefixed CMP #2(8) |
cmp eax, 0x0000007f |
| Prefixed CMP #3(8) |
cmp eax, 0x00007fff |
| Prefixed CMP #4(8) |
cmp eax, 0x7fffffff |
の15種類のテストを行なう。()の中は命令のサイズである。順に見てゆこう。
まずNOP(グラフ3)。L3 MISSする8MBより先はさすがに落ち込んでいる(そしてここの落ち込みぶりはIvy Bridgeより低い)が、逆にそこまで4Byte/cycleをきっちり維持しているのはちょっと異様である。このグラフだけ見ていれば、「Ivy BridgeはL1 Missの時点で4Bytes/cycleを維持できず、L2は3.5Bytes/cycle程度の帯域で接続されているが、Haswellは4Bytes/cycle以上の帯域でL2/L3が接続されているので、4Bytes/cycleが維持できる」と考えてしまいそうになる。ところが次のSUB(グラフ4)を見ると、Ivy Bridgeでも8MB付近まで4.5Bytes/cycleをきっちり維持していることがわかる。従って、先の仮説は成立しない。で同じ2Byte命令であっても、XOR(グラフ5)の結果が全然違うあたりが清々しい。実はXORはNOPと同じく、Zeroing Idioms(こちらの後半を参照)で処理されるため、実際には命令が発行されないのだが、そうしたケースで8Bytes/cycle、つまり4命令/cycleをきちんと維持できているところがHaswellの大きな違いとして示される。
これとやや違った傾向をしめすのがTEST(グラフ6)で、こちらは最初2KBまでは8Bytes/cycleで動いているのに、そこから次第に下がってL1 Hitのぎりぎりの32KBでは6Bytes/cycleになっている。ただそこからはL3 Missの8MBまで一定、というこれもまた独特な結果になっている。そうかと思うと、XOR/ADD(グラフ7)では8Bytes/cycleが8MB近辺まで維持するなど、明らかに命令によってスループットが明確に変わっているのがはっきり判る。
ではCMP系では? ということで、CMP #1(グラフ8)ではTESTとほぼ同じ傾向である。これが変わってくるのはCMP #2(グラフ9)である。命令サイズは4Bytesだが、最初8KB付近までは16Bytes/cycle、L2 Hitの256KB付近までは12Bytes/cycle、L3の範囲では9Bytes/cycle程度を維持している。ではこれがそれぞれL2/L3の帯域のボトルネックなのか? というと、L3に関してはそのようだがL2に関してはそうではない事がCMP #3(グラフ10)から判る。命令が6Byteの場合、L2では16Bytes/cycle弱の帯域を維持できている事がはっきり示されている。CMP #4~#6(グラフ11~13)はグラフ10とほぼ重なっており、この結果として命令のオペランドそのものはBandwidthに影響しない(命令のオペコードそのもので帯域が決まる)事もここから読み取れる。
では更に長い命令は? ということでPrefixed CMPのテストがグラフ14~17である。遂にBandwidthのピークは32Bytes/cycleに達しており、Haswellはサイズが8ByteのPrefixed CMP命令すら4命令/cycleでデコードできることになっている。これは何かちょっとおかしい。
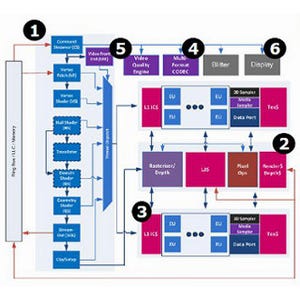
なんでこんな事になるのか、であるが筆者の推論はμOp Decode Cacheの内部構造が変更された、と見ている。μOp Decode CacheそのものはSandy Bridgeの世代で搭載されたもので、Decode段で一度x86命令をμOpに変換したら、それを続くSchedulerに送り出すと共に、その内容を最大1.5K分格納できるCacheに納めるというもので、言って見ればL0 Cacheに相当するものである。これがうまくHitしている場合、Schedulerには最大4μOp/cycleで命令が供給されることになる。つまり、4命令/Cycleで動作しているように見えているケースの殆どは、L1/L2から供給されるのではなく、このμOp Decode Cacheから命令が供給されている公算が極めて高い。
ただ、μOp Decode CacheそのものはIvy Bridgeも搭載しているし、μOp Decode Cacheのサイズが変わったという話も無い。そもそもμOp Decode Cacheは処理パイプラインに組み込まれているから、L1よりも更に高速にアクセスできる必要があり、これを大容量化するとダイサイズと消費電力の両面でペナルティは大きいから、変更していないと考えるのが順当だろう。にもかかわらずこれだけDecode Bandwidthが違う理由として考えられるのは、μOp Decode Cacheの保持方法が変わったものと思われる。
ここからは純粋な推定だが、Sandy Bridge/Ivy BridgeにおけるμOp Decode Cacheの保持方法は、純粋にアドレスベースでの命令格納と思われる。何を言っているかといえば、図1の用にDecoded μOp Cacheに対応したTagが本来の命令のメモリアドレスを保持しているという、ごく当たり前の仕組みである。こちらの方法だと、たとえば1500命令を超えた長大なループだと当然μOp CacheがMissするので、その先は普通にL1から命令をDecodeすることになり、後はL1/L2/L3のそれぞれの帯域がDecode速度のボトルネックになる。
ではHaswellは? というと、ある程度「繰り返し」をサポートする様になっているようだ。例えるなら図2の用に、同じ命令セットが続く場合はそれを省く仕組みだ(念のために言えばこれは概念図で、このまま実装すると色々不都合が多いので、Tag側に何らかの拡張を施していると思われる)。
これをどこまでサポートしているか、というと例えばグラフ3ではL3 Missとなる8MBあたりから急速にBandwidthが落ちているあたり、μOp Decode CacheのCache対象はあくまでもL3までに格納されている命令に限っているようだ。またうまくCacheに収まるかどうかは命令によっても差があるようで、同じ2バイト命令のXOR(xor EAX, EAX)とTEST(test EAX, EAX)でBandwidthのグラフの形が異なっていることからこれが見て取れる。
加えて言うと、Decoderそのものにも手が入っているようだ、Sandy Bridge/Ivy Bridgeの場合、Decode部はSimple×3+Complex×1の構成で、cmp命令などはSimple Decoderのみで処理される。この結果として、例えばPrefixed CMP #1~#4のテストでは最大24Bytes/cycleで頭打ちになっているわけだが、Haswellではこれが32Bytes/cycleに達しており、しかもグラフの形が明らかにL1 I-Cacheにアクセスしていることを物語っている。ということは、少なくともcmp命令はComplex Decoderでも処理できるようになっているという事になる。グラフ6で、Testの結果が他のものと異なる傾向なのは、
- Testに関してはμOp Decode Cacheで繰り返しのサポートが無い。なので、1.5KのμOp Decode Cacheを使い切ると、L1 Accessになる。
- Test命令をComplex Decodeがサポートしない。
の2つの合わせ技なのではないかと想像される。
今回Decode部のすべてを確認した訳ではないが、こんな限られたテストでもこれだけ違いがあるあたり、HaswellのDecodeは単にIvy BridgeにAVX2命令を追加したのみならず、色々と機能追加や機能強化を行なっている様に筆者には見える。
最後がPrefixed NOPの結果(グラフ18)である。これはNOP命令の前に意味の無いPrefixをだらだら追加して、どの程度のスループットになるかを見るテストである。要するにComplex Decoder→Microcodeの動作を見るものだが、結果を見ると判るとおり微妙ながらIvy Bridgeより改善されている様に見受けられる。原理的にスループットをドラスティックに改善するのは難しいし、元々Microcodeまで動くような命令は滅多にないから、むしろ手を入れて改善したことそのものが驚きとも言える。
次ページ:RMMA 3.8 - I-ROB