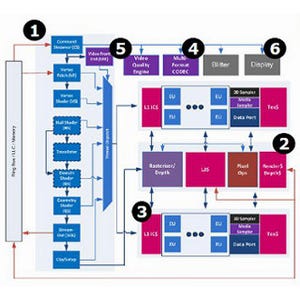
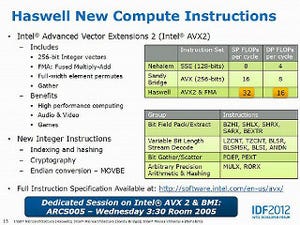
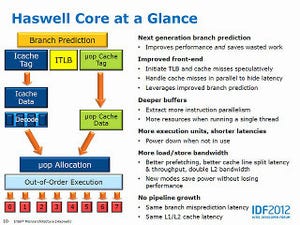
Checksum/Substring Search(グラフ124・125)
普段はまず示さない結果であるが、今回あまりに結果が乖離しているのでこれをちょっと御紹介する。まずグラフ124がchecksumである。checksumではCRC32とADLER32の2種類のアルゴリズムを使って、チェックサムを計算するというテストである。CRCの方は御存知の通り広く使われているもの。ADLER32はMark Adler氏が考案したもので、高速な代わりにやや信頼性には欠けると評されているものだ。ちなみにこのChechsumのテストコードは2004年にかかれたもので、なので勿論SSE 4.2で追加されたCRC命令には未対応である。

|
さて、結果はグラフ124の通り。CRC32はIvy Bridge/Haswell共に0.12Bytes/cycleの処理速度で完全に同じだが、ADLER32ではIvy Bridgeが0.89Bytes/cycleなのに対しHaswellでは0.97Bytes/cycleと9%ほど高速に処理が行なわれているのが判る。グラフを見て判るとおり、この差を誤差扱いするのには無理がある。
ではどんなことをしているのか、というので実際のソースを見るとList 1の通りである。ADLER32そのものはRFC1950で標準化されており、このRFCの末尾にサンプルソースも添付されているが、これは結構処理が遅く、なので最適化方法も広く知られている。RMMAではこの最適化ソースをベースに、更にInner loopを部分的に展開して高速化を図ったものを利用していることが判る。
ということでソースを眺めてみたものの、ではどのあたりがHaswellで高速化されている要因なのか、というのはにわかに判断つかなかった。プロファイラ付でコンパイル・実行して分析すればわかるかもしれないが、今回はその時間もなかったのでとりあえず見送ったが、adler32()、crc32()共にプログラムそのものはごく普通の処理しかしておらず、また何しろプログラムそのものも2007年末にBuildされたものだから、SSE2までにしか対応したOptimizationが掛けられていない。その意味では、Legacyなプログラムであっても、高速に動く「場合がある」という一例にはなると思う。

|
もっと極端に差が出たのが、グラフ125のSubstring Searchである。これは与えられた文字列を検索する速度を測定するというものだが、Case-Insensitive(大文字小文字を区別しない)場合にはHaswell/Ivy Bridge共に0.06Bytes/cycle(1文字を判断するのに大体16.7cycle必要)程度の性能なのに対し、Case-Sensitive(大文字小文字を区別する)ではIvy Bridgeが0.28Bytes/cycle、Haswellは0.41Bytes/cycleということでHaswellが46%も高速に処理できている事が判る。
プログラムの観点から言えば、Case-Sensitiveの方が簡単(文字コードが一致しているかどうかを見るだけ)である。Case-Insensitiveの方は、例えば大文字の"A"(ASCIIコードで0x41)と小文字の"a"(ASCIIコードで0x61)が同じであると判断しなければならないため、一工夫している。List 2が、その実際の比較ルーチンのソースであり、StrNStr()がCase-Sensitive、StrNIStr()がCase-Insensitiveのロジックである。やってることはどちらも一緒で、単にPointerを進めながら1文字づつ比較し、比較対象の文字列(List 2先頭で宣言されている szBaseStringの"RightMark Memory Analyzer ")と、上位ルーチンから渡された文字列を比較、一致した場所があればその先頭ポインタを、さもなければNULLを返すだけである。ただStrNStr()は比較の際に直接文字コードを比較しているのに対し、StrNIStr()ではToUpper()という関数を使って文字をすべて大文字化しているのが違いである。ToUpper()はStrNIStr()の直前に定義されている通り、単にASCIIコードで小文字(0x61~0x7a)の範囲であれば、0x20を引いて大文字のコードにして返す(そうれなければそのまま返す)だけの処理である。
ということでこちらもソースを眺めてみたものの、そもそもCase-Sensitiveの場合に1.5倍も性能が変わる要因がどの辺にあるのかも判らないし、ToUpper()を掛けるだけでそれが同じ性能に落ちてしまう要因も判断つきにくい。一般論として、こうした性能の変わり方をする場合、
- ToUpper()を掛けない場合、生成されたコードがうまくCPU内部の最適化ロジックと合わさって高速に処理できるようになった(MicroOps FusionとかMacro Fusionなどがこうした対象になりやすい)。
- ToUpper()を掛けると、生成されたコードがCPU内部の最適化ロジックに合わなくなってしまい、結果としてベタなコードで実行されることになる。
といった事になると考えられる。ただ今回のケースの場合、Haswellのどのあたりの最適化にHitしているのかがさっぱり見当がつかないのが問題だ。これも最終的にはプロファイラ付で実行して分析しないと判らないだろう。
ということで、プログラム次第ではHaswellが高速に動作する場合がある、という一例をちょっとお示しできたと思う。
List 1:
//---------------------------------------------------------------------------
//
// Checksum.cpp: Checksum Routines Implementation
//
//---------------------------------------------------------------------------
#include "StdAfx.h"
#include "Checksum.h"
DWORD __cdecl adler32(DWORD adler, BYTE* buf, int len)
{
// @WARNING: assume the buffer is always non-NULL
// if (! buf) return 1;
DWORD s1 = adler & 0xffff;
DWORD s2 = (adler >> 16) & 0xffff;
while (len > 0)
{
int k = len < NMAX ? len : NMAX;
len -= k;
while (k >= 16)
{
s1 += buf[0]; s2 += s1;
s1 += buf[1]; s2 += s1;
s1 += buf[2]; s2 += s1;
s1 += buf[3]; s2 += s1;
s1 += buf[4]; s2 += s1;
s1 += buf[5]; s2 += s1;
s1 += buf[6]; s2 += s1;
s1 += buf[7]; s2 += s1;
s1 += buf[8]; s2 += s1;
s1 += buf[9]; s2 += s1;
s1 += buf[10]; s2 += s1;
s1 += buf[11]; s2 += s1;
s1 += buf[12]; s2 += s1;
s1 += buf[13]; s2 += s1;
s1 += buf[14]; s2 += s1;
s1 += buf[15]; s2 += s1;
buf += 16;
k -= 16;
}
while (k--)
{
s1 += *buf++;
s2 += s1;
}
s1 %= BASE;
s2 %= BASE;
}
return (s2 << 16) | s1;
}
DWORD crc32(DWORD crc, BYTE* buf, int len)
{
// @WARNING: assume the buffer is always non-NULL
// if (! buf) return 0;
crc ^= 0xffffffffL;
while (len >= 8)
{
crc = crc_table[(int(crc) ^ (*buf++)) & 0xff] ^ (crc >> 8);
crc = crc_table[(int(crc) ^ (*buf++)) & 0xff] ^ (crc >> 8);
crc = crc_table[(int(crc) ^ (*buf++)) & 0xff] ^ (crc >> 8);
crc = crc_table[(int(crc) ^ (*buf++)) & 0xff] ^ (crc >> 8);
crc = crc_table[(int(crc) ^ (*buf++)) & 0xff] ^ (crc >> 8);
crc = crc_table[(int(crc) ^ (*buf++)) & 0xff] ^ (crc >> 8);
crc = crc_table[(int(crc) ^ (*buf++)) & 0xff] ^ (crc >> 8);
crc = crc_table[(int(crc) ^ (*buf++)) & 0xff] ^ (crc >> 8);
len -= 8;
}
if (len) do
{
crc = crc_table[((int)crc ^ (*buf++)) & 0xff] ^ (crc >> 8);
} while (--len);
return crc ^ 0xffffffffL;
}List 2:
//---------------------------------------------------------------------------
//
// SubString.cpp: SubString Search Routines Implementation
//
//---------------------------------------------------------------------------
#include "StdAfx.h"
#include "SubString.h"
const char* szBaseString = "RightMark Memory Analyzer ";
const int BaseLength = strlen(szBaseString);
char szSubString[260];
void __cdecl GenerateSubString(DWORD len)
{
// copy whole strings
int i = 0;
int l = int(len);
while (l > BaseLength)
{
strncpy(&szSubString[i], szBaseString, BaseLength);
i += BaseLength;
l -= BaseLength;
}
// copy last bytes
strncpy(&szSubString[i], szBaseString, l);
// make the string null-terminated
szSubString[len] = '\0';
}
char* __cdecl StrNStr(const char* Str, const char* SubStr, DWORD maxLen)
{
for (char* start = (char *)Str; DWORD(start) < DWORD(Str) + maxLen; ++start)
{
// find start of pattern in string
if (*start == *SubStr)
{
char* pptr = (char *)SubStr;
char* sptr = start;
while (*sptr++ == *pptr++)
{
// if end of pattern then pattern was found
if ('\0' == *pptr)
return start;
}
}
if (*start == '\0')
{
break;
}
}
return NULL;
}
inline char ToUpper(char c)
{
return ((c > char(0x60)) && (c < char(0x7b))) ? (c - 0x20) : c;
}
char* __cdecl StrNIStr(const char* Str, const char* SubStr, DWORD maxLen)
{
for (char* start = (char *)Str; DWORD(start) < DWORD(Str) + maxLen; ++start)
{
// find start of pattern in string
if (ToUpper(*start) == ToUpper(*SubStr))
{
char* pptr = (char *)SubStr;
char* sptr = start;
while (ToUpper(*sptr++) == ToUpper(*pptr++))
{
// if end of pattern then pattern was found
if ('\0' == *pptr)
return start;
}
}
if (*start == '\0')
{
break;
}
}
return NULL;
}次ページ:まとめと考察